
昨天看了一本投资的书:“稳定获利3”:
期货适合小资金博取暴力,股票适合大资金保值增值。
未必需要完全认同,保守一点的人,股票是进攻型,etf是保守型,没有对与错,选择自己合适的。
但讲出一个道理:广泛对更多市场建立认知,进而发现其中可能的几十年一遇的大机会。
你只会etf,就说ETF好,不妨看看转债,看看股票,看看期货,甚至是其它。
有人说,不是说专注、长期主义嘛?这就需要动用“多元思维模型”了。
在AI量化人跟中,这基本是一码事。
投资口在我眼中就是时间序列罢了,背后的驱动逻辑不同,表现上都是量价时空。
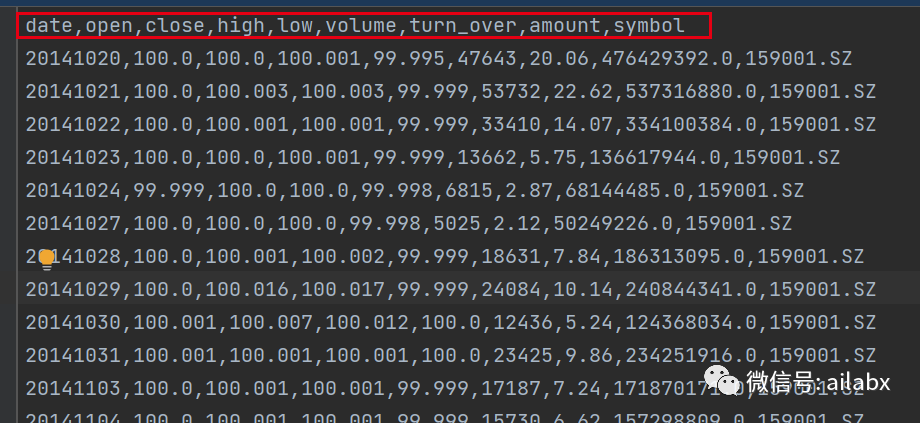
可转债数据:看价格,也看动量:
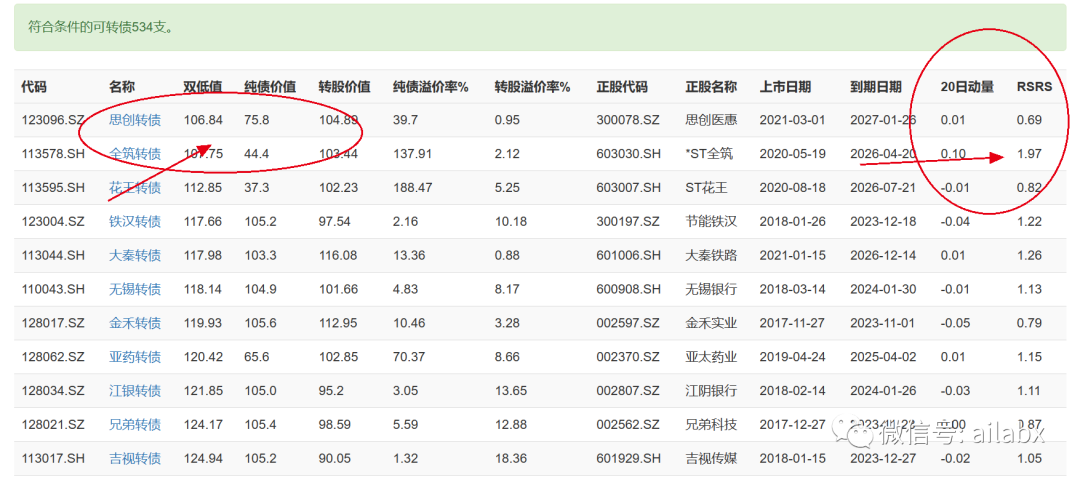

数据已经发布至星球,大家可前往下载。可转债历史数据全量下载,包括价量数据,纯债价值,转股价值,转股溢价,双低值等。
也可以点击“阅读原文”直接查看。
吾日三省吾身
今天的集思录上看到一个热贴:“草根靠什么快速积累财富”。
显然这个所有人都非常关心的问题。
答案当然是没有答案 ,但大家至少有一个共识,打工是不可能快速积累财富的。————当然,互联网黄金时代的大把期权这个其实是反例。
这个问题,我的思考是:按富爸爸里的逻辑,买入或构建可以带来现金流或者复利倍增的资产。
买入=投资。过去二十年,最大的机会是房产,其次是互联网大厂的期权。
我都遇到过,但都没完全把握住,之前回顾过,博君一乐:
28岁财务自由的程序员,我想起那些年错过的1个亿,悲伤的故事
向前看,就是哪里找这样的大机会?
投资领域的话,我们当下在做的事情,就是布局AI量化,让机器帮我们找机会。构建的话,AI量化平台,还有目之所及就是大模型。
但参与“构建”,难免需要协作。
最近在短视频平台,把大明王朝开国的电视剧刷了个七七八八。朱元璋开局一个碗,结果带王冠。当然历史上只有一个朱元璋,他如果对战陈友谅失败了,连这个碗也没了。但大家要知道,拿了大把期权,但没有兑现的大明王朝淮西勋贵。
历史评说太复杂,我们只讨论财富故事。
我见过有人持续妥协,无论他内心认同与否,他的目的性很强,忍下所有;我也见过有人八面玲珑,人见人爱,花见花开。
如果你也厌倦了职场的蝇营狗苟,投资+AI确实是一条不错的路,并不容易,但至少没有这些东西。投资与机器,都讲逻辑、判断。
今天构建可转债的数据。
大家也许要问为什么先构建可转债的数据,两个原因:
一是从投资理念看,可转债与ETF相似之处在于,可转债也属于“中低”风险投资领域;
二是可转债几百支,数据量相对小,而且可转债的数据里,也需要构建对应的正股数据,也后续做股票数据打下基础。
可转债基础数据:
@asset(description='从tushare更新可转债列表', group_name='basic')
def bond_list_from_ts():
df = loader_ts.get_bond_list()
df = df.rename(columns={'ts_code': 'symbol'})
df['_id'] = df['symbol']
get_dagster_logger().info(df)
mongo_utils.write_df('bond_basic', df, drop_tb_if_exist=True)
return df
A股市场,一共上市954支可转债,除去已经退市的,当前可以交易的转债为567支,下图完成入mongo数据库。
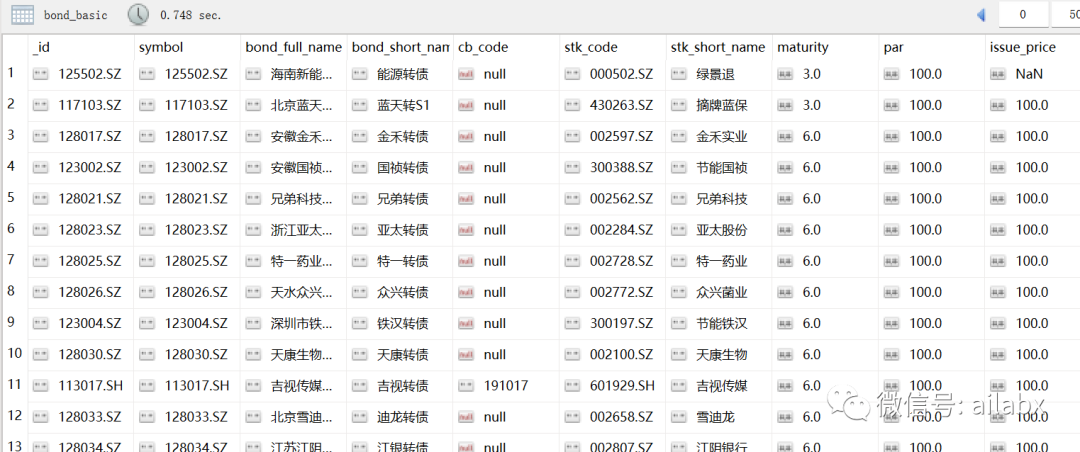
从mongo取出可转债列表:
@asset(description='从mongo读存续期内的可转债列表', group_name='bond') def bond_list_from_mongo(): items = mongo_utils.get_db()['bond_basic'].find({}, {'_id': 0, 'symbol': 1}) symbols = list(pd.DataFrame(list(items))['symbol']) get_dagster_logger().debug(symbols) return symbols
获取可转债的日线数据,包括债券价值,转股溢价率等:
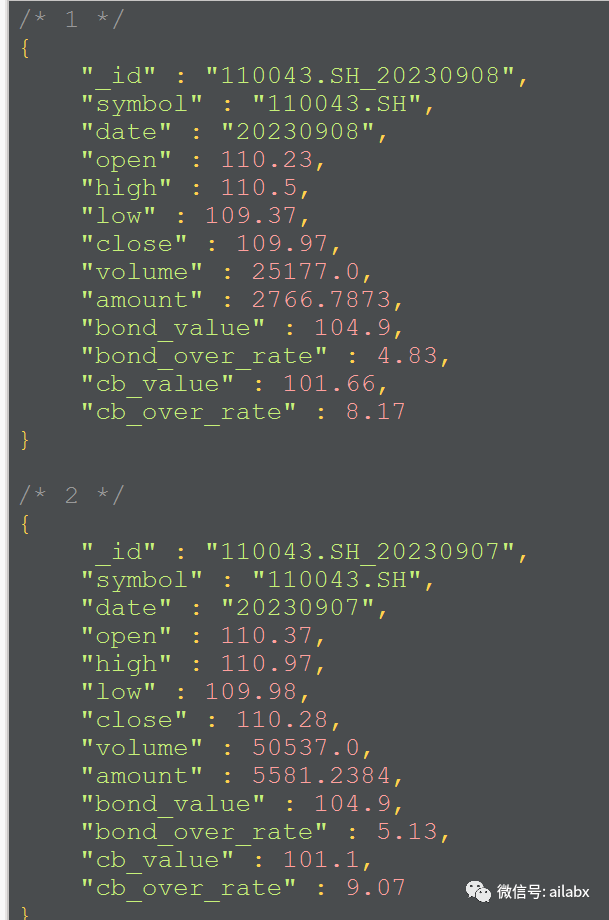
与ETF数据类似,我们把导入日线历史数据、日线增量数据,导入到csv里,而后全局计算其因子,供排序、检索之用。ETF全量数据下载,引擎重构代码升级分析,ETF的数据截至昨天又重新更新:
大数据看投资
近期商品强势,主要是黄金。无论是动量还是阻力支撑,都很强。

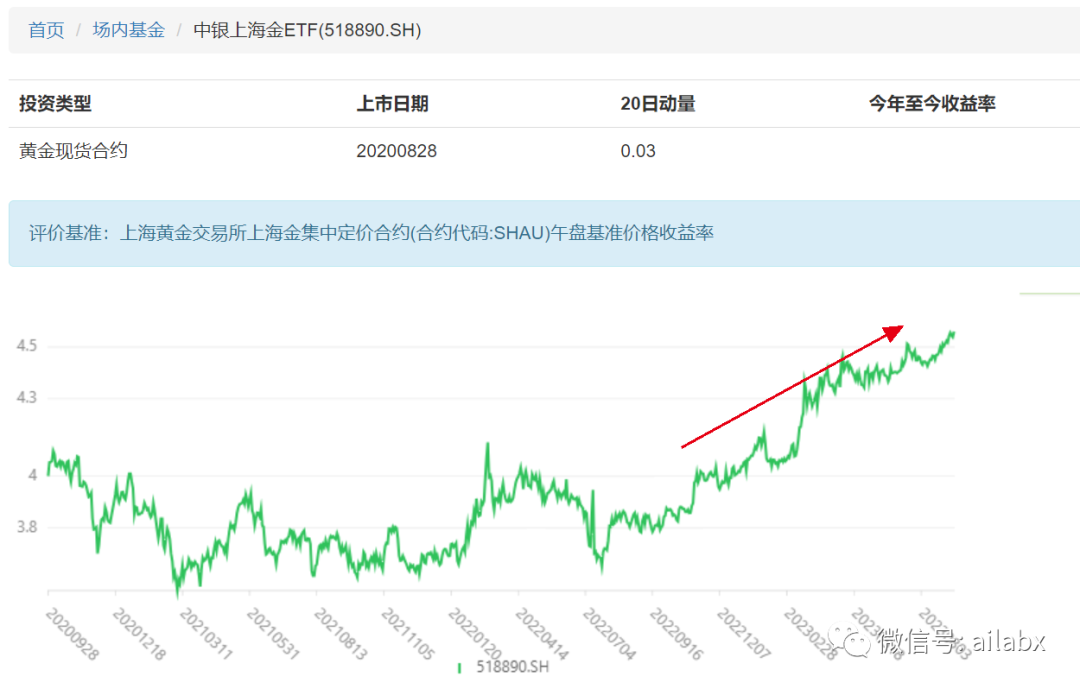
其次易方达原油:

银行、保险、证券等行业动量弱势,但支撑很强。
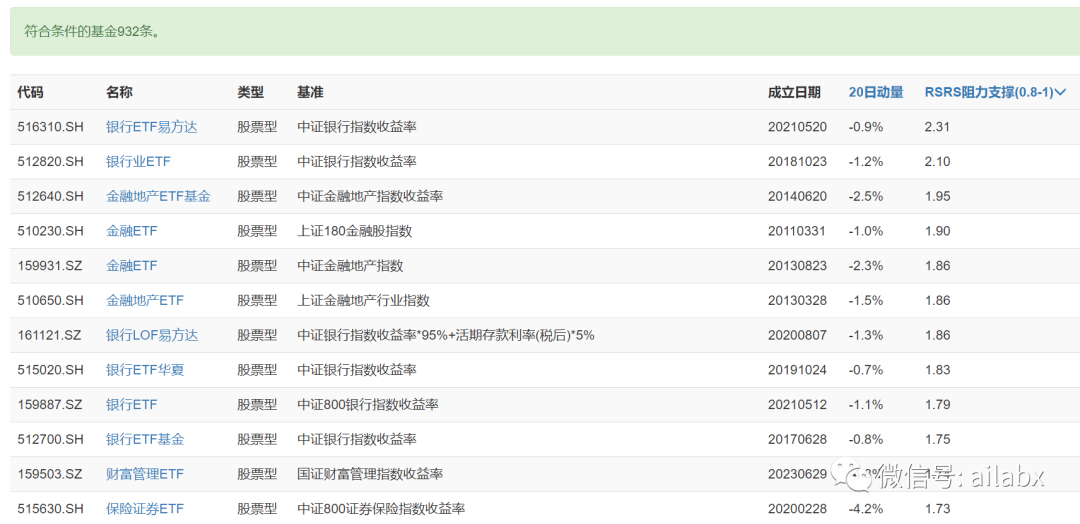
小结
七年之约,只是开始。
践行长期主义。
万物之中,希望至美。
人工智能与金融投资,都是长坡厚雪,且还是为数不多,可以满足个人英雄主义情结的地方。
走,一起赶路吧。
市场分析:ETF全市场数据分析,从20日动量来看,除了标普信息科技之外,其余动量最强的是商品,煤炭、原油、能源等等。

01 数据下载
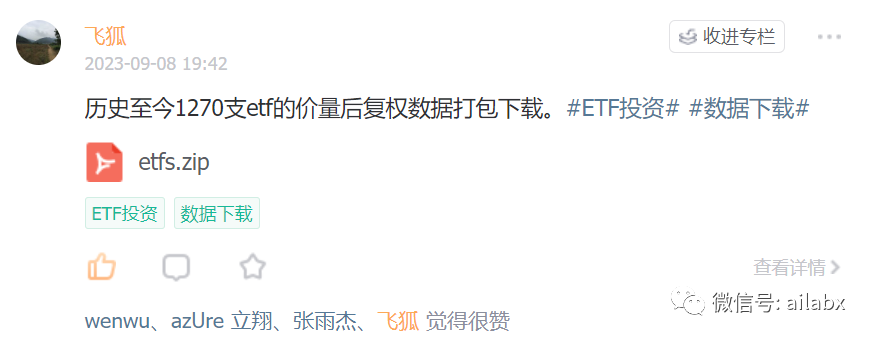
汇报一下最新数据进展:历史至今1270支etf的价量后复权数据打包下载。
数据是量化的基础,在机器学习领域,大家大量的时间都花在整理数据上,我希望把这些事情给大家准备好。大家把心思更多花在金融逻辑与策略上。
OHLCV及换手率,量价数据都是“后复权”(量化一般使用后复权,与你看到的真实价格可能会有不同)之后的。如果你自己处理,需要下载复权因子,然后合并之类的,1000多支etf(含LOF)是个不小的工作量,而且调试挺繁琐的。
之前发过沪深300成份股的历史量价及估值数据:

02 系统升级
关于系统升级,昨天大家报了说与老版本收益率差距较大的问题。早起我就起来调试了。使用同样的最新的数据集。
等权+月底再平衡的策略:
from engine.backtest import run from engine.algos import * from config import DATA_DIR from engine.engine_utils import load_data, get_backtest, get_bench_bkts, show_results symbols = ['510300.SH', # 沪深300 '511220.SH', # 城投债 '518880.SH', # 黄金 '513100.SH', # 纳指100 ] fields = ['close/shift(close,20)-1', 'close/shift(close,1)-1'] fields.append('roc_20>0') names = ['roc_20', 'return_0'] names.append('roc_20_gt_0') df = load_data(fields, names, symbols, path=DATA_DIR.joinpath('etfs')) data = df.pivot_table(values='close',columns='symbol', index='date') data.fillna(method='ffill', inplace=True) import bt # create the strategy s = bt.Strategy('s1', [bt.algos.RunMonthly(), bt.algos.SelectAll(), bt.algos.WeighEqually(), bt.algos.Rebalance()]) test = bt.Backtest(s, data) res = bt.run(test) print(res.stats)
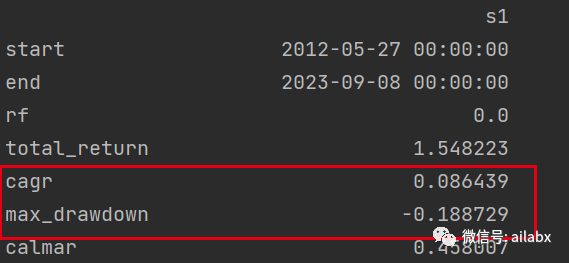
老版本年化:8.6%,最大回撤:-18.87%,
老版本的bt内核会把日期往前一天,但这一天,本身不参与运算,我们真实输入的数据其实是2012-05-28开始。
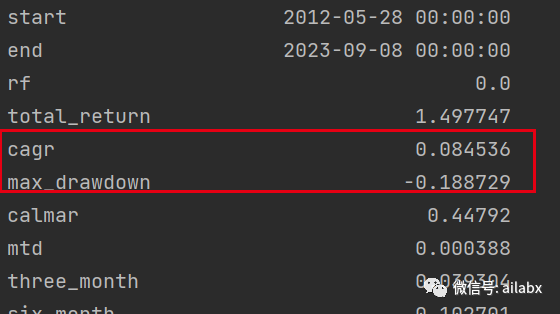
新版本:年化8.4%,最大回撤数据一模一样。
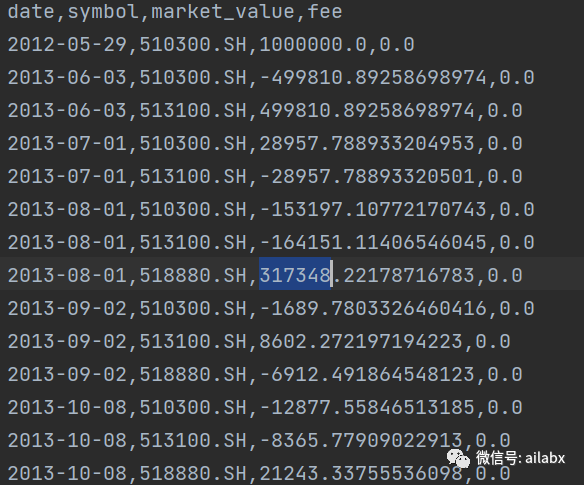
从调试的角度,大家可以把交易记录打印出来,甚至保存到csv里对比:
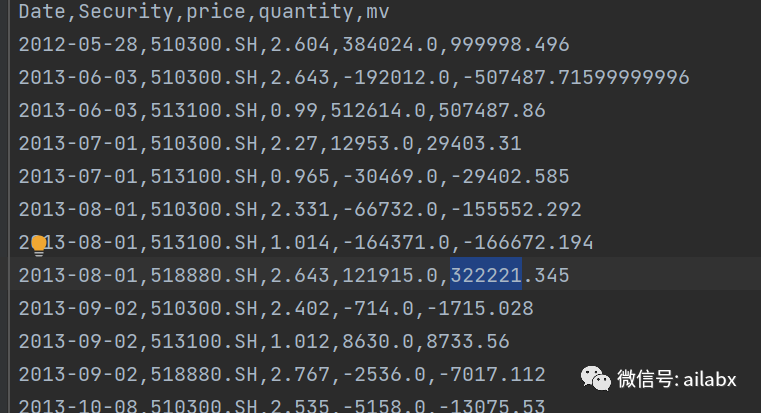
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103913
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!