
主流的公、私募量化,多因子模型是重中之重和热点方向。容量大,可以与前沿技术相结合。
东方证券的一张图:多因子选股体系


多因子选股体系主要包括 Alpha 模型、风险模型、交易成本模型和组合优化四个模块。Alpha 模型负责对股票收益或 Alpha 的预测,对组合收益的影响相对更大,是量化研究的重中之
重。传统的 Alpha 模型一般分为 Alpha 因子库构建和 Alpha 因子加权两个核心步骤。
其中:在 Alpha 因子构建中,可以引入的常见机器学习模型主要有两大类:遗传规划和神经网络。
先挖掘因子,再合成,忽略了因子之间的相互作用。
今天开始要代码实现的:一种新的因子组合挖掘框架,直接使用因子组合的表现来优化一个强化
学习因子生成器,最终生成的是一组公式因子集合,这些因子协同使用具有较高的选股效力。这
样做既能保留遗传规划算法公式化的优势,也能提升模型泛化能力,适应多种股票池,还能大幅
提升运算效率。

我对这篇论文感兴趣的核心在于,它具备一定程度上的通用性,集传统遗传规划的优点,可以显示生成表达式,结果了深度学习的泛化能力和端到端的能力。另外,原作者是提供代码的,不过它使用qlib的数据库,我进行了拆分,与咱们的开源项目,数据模块整合起来,让这个模块更加通用。
核心代码在Quantlab工程的如下位置:alphagen。

代码环境,需要:pytorch框架上的强化学习包:
stable_baselines3==2.0.0 sb3_contrib==2.0.0
核心的调用代码如下:
import json import os from datetime import datetime from typing import Optional import numpy as np from sb3_contrib import MaskablePPO from stable_baselines3.common.callbacks import BaseCallback from alphagen.data.calculator import AlphaCalculator from alphagen.models.alpha_pool import AlphaPool, AlphaPoolBase from alphagen.rl.env.core import AlphaEnvCore from alphagen.rl.env.wrapper import AlphaEnv import torch from alphagen.rl.policy import LSTMSharedNet from alphagen.utils import reseed_everything from alphagen.caculator.duckdb_caculator import DuckdbCalculator def train(seed: int = 0, pool_capacity: int = 10, steps: int = 200_000, instruments: str = "csi300"): calculator_train = DuckdbCalculator(instrument=instruments, start_time='2010-01-01', end_time='2019-12-31') calculator_valid = DuckdbCalculator(instrument=instruments, start_time='2020-01-01', end_time='2020-12-31') calculator_test = DuckdbCalculator(instrument=instruments, start_time='2021-01-01', end_time='2022-12-31') pool = AlphaPool( capacity=pool_capacity, calculator=calculator_train, ic_lower_bound=None, l1_alpha=5e-3 ) reseed_everything(seed) device = torch.device('cuda:0') env = AlphaEnv(pool=pool, device=device, print_expr=True) name_prefix = f"new_{instruments}_{pool_capacity}_{seed}" timestamp = datetime.now().strftime('%Y%m%d%H%M%S') checkpoint_callback = CustomCallback( save_freq=10000, show_freq=10000, save_path='/path/for/checkpoints', valid_calculator=calculator_valid, test_calculator=calculator_test, name_prefix=name_prefix, timestamp=timestamp, verbose=1, ) model = MaskablePPO( 'MlpPolicy', env, policy_kwargs=dict( features_extractor_class=LSTMSharedNet, features_extractor_kwargs=dict( n_layers=2, d_model=128, dropout=0.1, device=device, ), ), gamma=1., ent_coef=0.01, batch_size=128, tensorboard_log='/path/for/tb/log', device=device, verbose=1, ) model.learn( total_timesteps=steps, callback=checkpoint_callback, tb_log_name=f'{name_prefix}_{timestamp}', )
其中DuckdbCaculator是我们实现的。
就是根据表达式计算因子,IC值等等。
使用了sb3的强化学习扩展包里的MaskablePPO算法。
一直认为强化学习最适合金融投资,因为它是多轮博弈的结果,且博弈的成本都可以体现在过程中。
我一直在找一个通用的范式,我们开发的框架,也是奔着通用的,算子化,积木式的方式。
从原始数据,到机器建模,再到实盘交易。
传统的因子生成方法都是逐个挖掘的,而忽略了这些因子在下游应用需要集成的问题。因子挖掘出来,再使用机器模型来合成,这时候,如何做到最优呢,有时候,加入一个低IC的因子,效果反而可能会更好。——非线性的世界,我们如何想得明白?
我在星球发了一篇研报,最近打算复现它。

华泰那个DeepAlpha我看了,它的因子生成是直接把函数变在层运算,并没有参与到深度网络的运算中。
而这篇DeepGen强化学习,它引入的类似GPLearn的公式生成树,然后使用强化学习来优化参数的逻辑。使用了gplearn, dso来做baseline,看起来还不错,至少这个范式比较有通用性。
值得复现一下代码。
作者本身有给代码,不过与qlib紧密结合,我打算使用咱们自己的框架Quantlab来复现。
吾日三省吾身
看了一些80,90年代的老房子,房价依然不菲。
背后支撑的力量,一是学区,二是位置。
精炼为两个字——稀缺。
3000点保卫战再次打响。
人口增长放缓、老龄化的问题在未来20年会突显出来。
现在有些幼儿园出现的招不满孩子的情况,未来可能会延伸。
人口基础,决定了劳力力来源,创新能力和消费力量。
20年后,也许并不需要这么多房子。
仔细想想,为什么要买房子,或者说某个位置的房子。
一是教育;二是上班。
教育考虑名校资源,上班考虑通勤。
财务自由之目标就是让上班变得“非必须”。孩子教育也就是义务教育之九年的必要性。当然有些人可能进入了稳定的工作状态,比如体制内,那工作地点可能未来几十年是不变的,通勤也是刚性考量。
看李白传记,真是潇洒,但之于他,有怀才不遇,略带悲剧色彩的意味。
才华是老天追着喂饭,且身逢其时。
但放荡不羁,好喝酒,没有情商还总想参与国家大事。
重友情,好旅游,四海为家,挥金如土,认为千金散尽还复来。
天生我才必有用。
看完不禁反思,人的一生应当如何度过呢?人生的意义是什么?

做自己。
做自己喜欢、擅长且有社会价值的事情。能从这些事情中合理合法获得物质回报,同时还获得尊重。这就是好的人生状态。
在做这些事情的过程中,可以把这些事情,逐步自动化,沉淀为资产,能够带来被动收入那就更好了。
本周Quantlab源代码已经更新:
AI量化里什么最重要,数据+因子。
从这个角度看过去,Qlib完全努力错了方向,一直搞模型,很学术风,然而,模型在如此低信噪比的金融数据里,挖不出东西。
从实战的角度,你要么做自动化,比如WonderTrader, Vnpy都有用,自动化尽管非刚需,但私募机构是需要的,虽然大家都会有自研能力。
Qlib如果要做AI导向的框架,应该是因子挖掘的流水线;而不是因子模型,这个不重要,搞一个StockRanker就够用了。所以,我们就来做这件事了。
Quant2.0:将量化的研究模式从小型的天才工坊转变为工业化、标准化的阿尔法工厂。
Quant3.0: 端对端;
Quant4.0:AutoML,可解释。
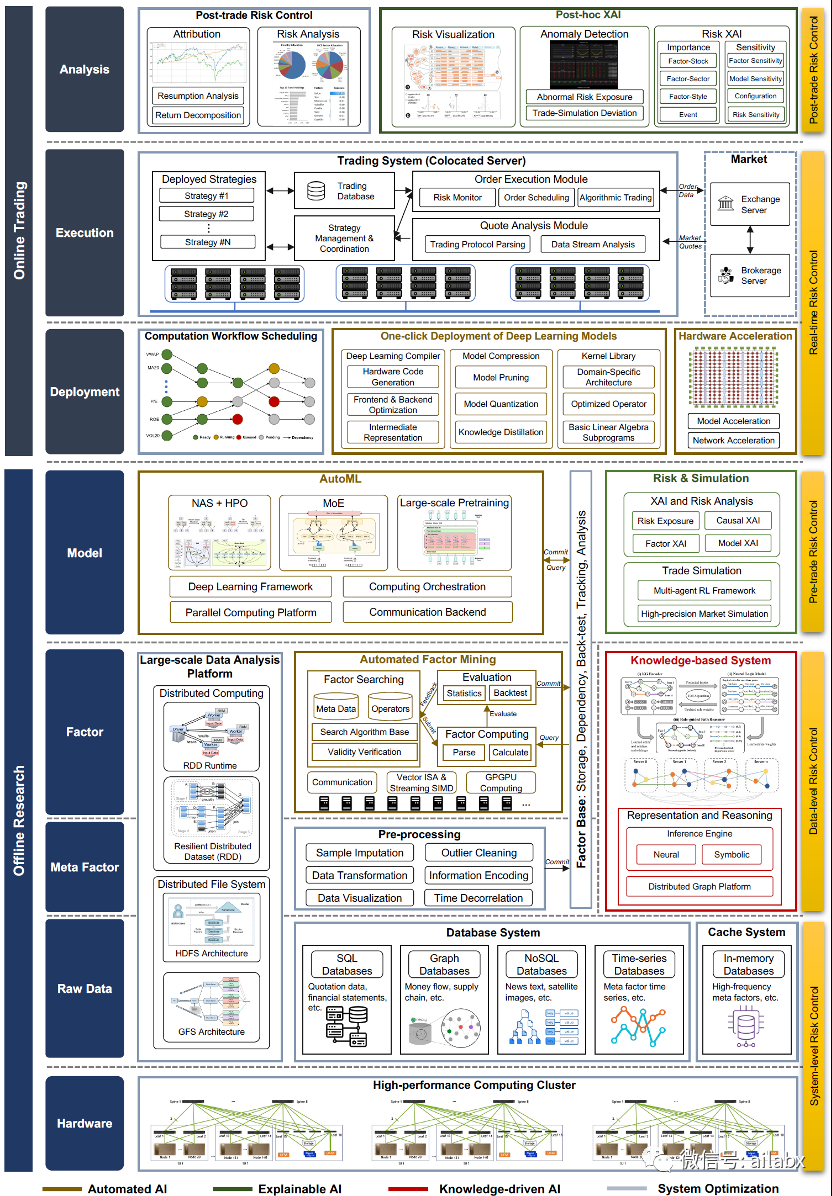
(Quant4.0架构图)
计算因子只是投研阶段的第一部分,而最重要的部分其实在于如何挑选最为有效的因子。
信号没有标注的问题,而除了强化学习之外,监督训练都需要标签。而qlib默认使用明天的收益率,这也有明显问题。按A股的规律,就是一涨一跌的逻辑。上涨过程可能回调,下跌过程也会缓一下,但方向没有变。至少看5天,超过一个月可能就不是价量的规律可以覆盖的范围。
相当于“预测”5天后的收益率,来选出股票,而且这里需要考虑中途回调可能触发的止损机制。然后持仓周期也是5天,5天后再看,如果仍然排名高,则继续持仓,否则换更优的股票,如此循环往复。
现在再回头看,什么是好的因子?
好的因子,就是可以区分出,挑选出N天后涨幅最大的股票。
从IC的角度,就是这个因子的截面值,与收益率有大的相关性(正或负都可以,绝对值越大越好)。
手动构造,还是自动化挖掘?
私募的做法:数据清洗;因子挖掘、特征提取;机器学习因子组合;算法交易;T+0增强。
因子评估方面,alphalens就是合适的,如果觉得重,不好整合,可以把alphalens的代码重新收拾一下即可。
吾日三省吾身
最近股市确实一般。。。
世界千年未有之大变局。。。俄乌未见转机,哈以又起硝烟。
以投资为生的同学,估计会有巨大的压力。
尽管资本市场一定是长期向上的,但过程是周期波动的,有时候,一个周期底部时间,也许会超过你的想象力,你的承受力,甚至,一转眼就是一辈子。
这里没有任何悲观或者乐观的意味——没有人知道。
我们说要构建一个反脆弱的体系,无论是你的生活,人生,还是投资组合,均如此。
回首往事,30岁之前的年少轻狂,就是明明什么都没有,但充满激情和希望,认为一切只是时间问题。
30岁之后,开始务实。诸事不易,好事多磨,做时间的朋友。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103764
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!