
房子是世界人民都有的情结,国人尤是。
我们的传统观念告诉我们,你得在一个城市有自己的房子,才算安定下来。
这个城市才和你有了关系。
河南亮亮丽君夫妇的事情,就是当下地产暴雷的一个缩影,个中细节很多媒体都写的,这里不想展开。
时代的一粒沙,落在普通人身上就是一座山。


为什么想聊这个话题,因为随着孩子长大,媳妇又重提学区的事情。
过去十来年地产的黄金时代,平均年化10-15%,核心区学区房比这个数值要高很多。
很多人踩中对的点,就是被动发财。
我一个同学,西城、海淀各一套学区房。这二十年的工作工资收入,在这两套房子面前不值一提。
问题来了,现在还是入手房子的好时机嘛?
先说人群, 这里针对中产聊这个话题,富豪的行为咱不懂,您买N套搁着喂猪也不为奇。
中产买房,可能是改善性的,2居换3居。郊区换市区,为了工作方便。还有一个重要的理由,为了孩子读书。
普通人买房有两重要因素,一是未来增值预期(至少不能跌吧),二是杠杆率,就是你的现金流不能断了。
未来增值预期这一块,大家应该都容易共识,一线城市核心区能跑过通胀就不错了。另外预售新房风险极高就别考虑了,没必要给自己找麻烦事。很多人并没有考虑太多增值属性,就觉得二手房尽管旧一点,离单位还近,孩子还能上更好的学校,看起来还挺划算的。
那么第2个问题来了。
杠杆率,普通人买房多数是要借贷的,就是上杠杆。
金融上讲,就是拿未来的收入流作“抵押”,其实主要就是工资。
现在居民负债率62.1%,比世界平均40%高得多,比发达国家70%还是低一些。
这里的居民负责,多数就是房子。意味着,有人把杠杆用于极致,“赌”的就是房子还要继续升值,赌的是自己的工资可以稳步提升。
但这两个维度,这几年大家发现,都不实现。
以前即便公司出现状况,可以很快换一家公司,工资还可能更高,“接着奏乐接着舞”呗。
有钱人老了,年轻人少了。
上世纪的60-70后,在中国加入WTO时,赶上风口,积累财富的这些人,老了。老人是不会追求什么核心区,学区房的。未来人口少了,这个趋势基本也是确定的。
创二代不创业了,大家收拾银两,怕“凭运气赚的钱,被二代凭实力亏掉”,干脆做做理财,衣食无忧好了。
在教育公平深入人心,学区改革是大概率的事情。
“双减”落地如此决绝,学区房会远嘛,没有学区资源支撑,那些老破小谈什么价值呢?
只是怎么软着陆的问题。
说到这,问题基本清楚了,如果特别有钱,那随意。
如果还要费尽心力上杠杆,赌一个没边的学区,那慎重。
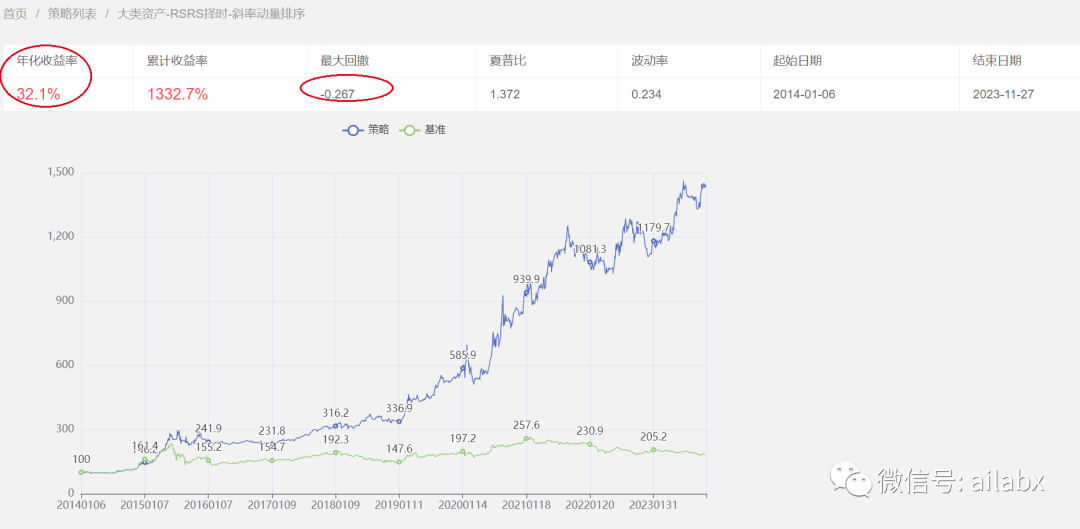
昨天的比较满意的策略:
历史长期年化32.1%, 最大回撤26.7%,夏普比1.372(代码+数据下载)
数据和任务现在在服务器都是盘后执行了。
大家本地化的版本是使用streamlit做的界面,功能是一样的,策略代码和回测系统都是完全开源的。
历史长期年化32.1%, 最大回撤26.7%,夏普比1.372(代码+数据下载)
一觉醒来,发现大家都在聊大模型了。
而且甚至发现,好多人竟然开始教大模型了。
门槛都这么低了嘛?
我不得不出来写点东西了。
之前大模型上没有特别发力,只能算是持续关注。因为觉得这个东西太重,一般公司玩不动。
当然,现在形势有了一些变化,单机单卡能玩的模型已经不少了,而且开源世界也争奇斗艳。
01 大模型概览
LLM(Large Language Model),最需要区分的就是上个时代的“预训练”,主要以Bert系为主。
其实LLM本质上也是预训练。
传统以Bert为代表的预训练参数量多大呢,我查了下,大致是100多M,也也就是1亿级别或者说0.1B吧,而GPT-3的参数量是175B。这就是区别。
当然了,现在开源的,普通人能玩的,大致分布在6B和13B等。
除了参数大之外呢?
其实基于Transformer体系,发现出三个路线:只有编码器,如Bert系列,只有解码器的GPT系列,还是编码又解码的T5系列。
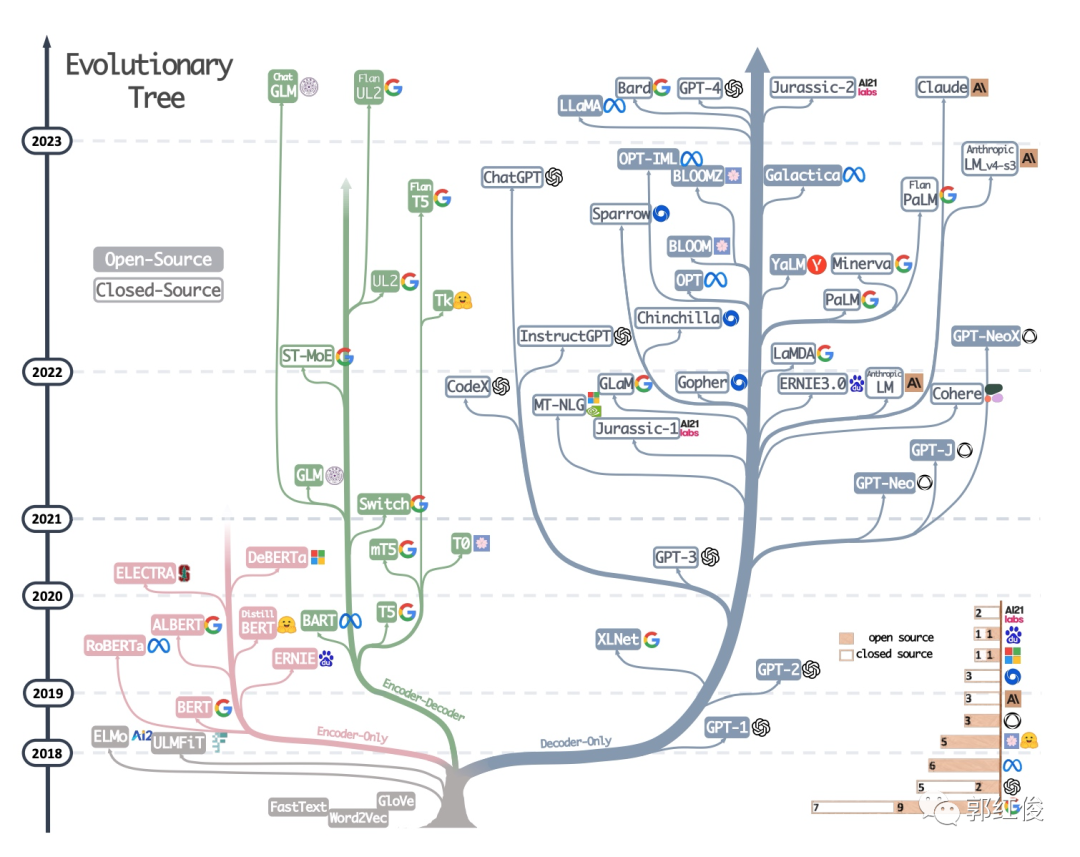
”只有编码器“这一支比较好理解,就是“阅读理解”。
你读一本书,看一部电影,然后你会判断这是好书,好电影,或者给出差评。这就是机器学习里的分类。很长一段时间,业内有句话叫,离线部署的话,分类直接无脑Bert肯定没错。
以前做NLP分类,我们也会对文本进行向量化的编码,比如“词袋模型”,但事实在丢失了很多信息。后来有了word embedding对向量进行编码。
中间绿色的这一支,主要应用是翻译。这个也好理解,传统的seq to seq就是这个逻辑,把一类文本编译,然后解码成对应的另一种文本。
当时最不被看到的就是GPT这一支。解码器就是“续写”。当时的写诗,写对联,就是那种形式上可以对齐,但一看就是玩具,除了偶尔拿出来卖弄,没有什么实际的商业价值而被人忽略。
我们现然说的LLM,通常是以ChatGPT为代表的生成式,也就是Decoder-Only这一支。
02 如何快速上手大模型
咱们这里说的上手,不是很多社群讲的,怎么去买一个ChatGPT的账号,如何写prompts(提示)让模型回答我们的问题。——这都不叫事。
我们指的上手,就是训练(微调)出自己的大模型,比如应用于金融量化投资?
无论是挂载知识库,还是Agent访问我们的数据库等。
想来从meta的LLama2开始比较合适。
llama2有三个版本,7B,13B和70B。我的4卡的机器上,fine-tune13B是没有问题的。130亿的参数,也基本够用了。
吾日三省吾身
中年危机是一种心态吧。
成年人的世界没有容易的事情。
有些事情,讲对错是没有意义的。人家是金主,是需求方。要求可能无理,但人家出钱呀。你需要这个项目,需要沾人家的产品品牌,就没有什么立场与人聊什么流程,规范,你为什么不早说?
对品牌,体验的无限要求,本身也没有错误。加上时间限制虽说有点过份,那人家还觉得你们上纲上线呢。
上有老,下有下,不像年轻人那么洒脱,尽管财务状态,各种积累,认知会相对好一些,但要顾虑的因素也更多一些。
财务上的基本自由是心灵自由的基础。
其实很多人都说,如果有稳定的被动收入2万/月,尽可以“尽情”放飞自我。
注意,这里肯定得是被动的且是稳定的。
这就需要构建一条或多条被动收入管道或系统。
一本书?现在出书的门槛不高,而且一本书拿不到多少版税,常销且畅销?上次听到这个词是来自李笑来。。
一首歌?也就方文山吧。
多数人能想到就是定存吃利息(要求本金大),或者房子出租收租子(同样对本金有要求)。
一门课?知识付费?主要看流量和个人IP品牌。如果有IP,其实做啥都容易,这个杠杆已经足够。否则辛苦一门课,卖个100来份,几万块钱,就不太划算了,基本算不上被动收入。因为知识付强的供给较多,用户有的选,你需要带来什么样的差异化内容?很难,内容同质的情况下,就看流量与个人品牌(品牌与流量有时候可以对等)。
有流量,你就是网红了。
还有一个逻辑,是产品逻辑。比如像集思录,理杏仁这样的小而美的投资辅助平台。创建者本身不是大V,不带流量或品牌,但由于产品或服务本身的价值性,产品积累了用户和流量。
产品逻辑,就是为特定的人群,解决一个特定的问题。
网红逻辑,人性中的好奇,肯定是作品为先,比如搞笑的,小杨哥这种,知识类的,货币战争这种,卢克文这种。内容本身不变现,或者少,但内容积累的粉丝,人设,网红。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103651
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!