
DeepAlphaGen系列:
端到端因子挖掘框架:DeepAlphaGen:因子生成的强化学习Env Wrapper包装器实现细节
端到端因子挖掘框架:DeepAlphaGen:因子生成的强化学习Env搭建
原理比较简单,使用强化学习来生成“因子表达式”——逆波兰表达式。然后把因子组合在一起做优化,评价标准仍然是传统的IC/IR这一套。
我们的基准是gplearn遗传算法挖因子。
Qlib加载数据,这里没有看出groupby(‘symbol’)
class Feature(Expression):
def __init__(self, feature: FeatureType) -> None:
self._feature = feature
def evaluate(self, data: StockData, period: slice = slice(0, 1)) -> Tensor:
assert period.step == 1 or period.step is None
if (period.start < -data.max_backtrack_days or
period.stop - 1 > data.max_future_days):
raise OutOfDataRangeError()
start = period.start + data.max_backtrack_days
stop = period.stop + data.max_backtrack_days + data.n_days - 1
return data.data[start:stop, int(self._feature), :]
def __str__(self) -> str: return '
无论是基于深度强化学习,还是gplearn遗传算法,只要是多标的,多个symbols同时计算,那么在进行表达式运算时,肯定要groupby symbol或者甚至groupby date。
否则rolling是有问题的。
目前的依赖包:torch的cuda版本是需要根据你本机的显卡的版本来确定的,我电脑上的驱动版本比较老,是10.2,因此只能安装较低版本的pytorch。
baostock==0.8.8 gym==0.26.2 matplotlib==3.3.4 numpy pandas==1.2.4 pyqlib #qlib==0.0.2.dev20 sb3_contrib==2.0.0 stable_baselines3==2.0.0 torch==1.10.2+cu102 --extra-index-url https://download.pytorch.org/whl/cu102 shimmy==1.1.0 fire tqdm loguru requests joblib scipy scikit-learn
经过一番折腾:
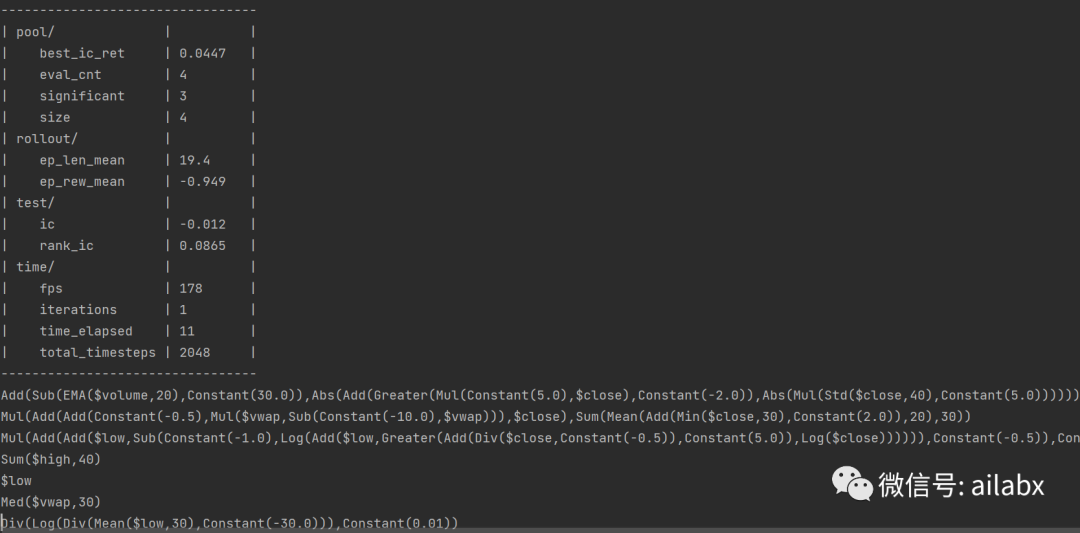
已经开始端对端挖因子了:

吾日三省吾身
做一件事情,意义很重要。
工作也好,创业也罢。
有时候做一件事,就是纯粹为赚钱,比如年轻时候想赚快钱,合理合法,也没有什么问题。
比如当年那么多年靠SEO做外贸,其实主体工作就是满世界发垃圾链接,做排名。
只不过长期主义的事情,需要一个更大更持久的意义。
先辈们是有信仰,甚至不惜牺牲个人生命为代价,在追求一些东西。
意义,可以是利益,更多不是。
意义是个人赋予的。
达芬奇创造的意义,爱迪生发明的意义,对于未知的渴求,对世界的好奇心。
今天继续实现强化学习环境的包装器:
我们有生成符号token序列,这里的序列有多种类型,比如函数std,csrank等,还有特征,通常就是ohlcv,还是日期,比如20d,还有常数。然后就是结束符号。
下面的函数就是把int变成一个token,其实就是查列表。
def action2token(action_raw: int) -> Token:
action = action_raw + 1
if action < OFFSET_OP:
raise ValueError
elif action < OFFSET_FEATURE:
return OperatorToken(OPERATORS[action - OFFSET_OP])
elif action < OFFSET_DELTA_TIME:
return FeatureToken(FeatureType(action - OFFSET_FEATURE))
elif action < OFFSET_CONSTANT:
return DeltaTimeToken(DELTA_TIMES[action - OFFSET_DELTA_TIME])
elif action < OFFSET_SEP:
return ConstantToken(CONSTANTS[action - OFFSET_CONSTANT])
elif action == OFFSET_SEP:
return SequenceIndicatorToken(SequenceIndicatorType.SEP) else: assert False
咱们不使用qlib作为数据源,
而是使用咱们自己的框架里的Mongoloader。
Caculator的代码比较简单,就是根据表达式来计算IC值。
论文的代码都是使用torsor来计算的,我考虑直接使用pandas的函数也可以,后期再转化为torch的tensor。
from typing import Optional, List, Tuple import torch from torch import Tensor from alphagen.data.calculator import AlphaCalculator from alphagen.data.expression import Expression from alphagen.models.alpha_pool import AlphaPool from alphagen.rl.env.wrapper import AlphaEnv from alphagen.utils.correlation import batch_pearsonr, batch_spearmanr from alphagen.utils.pytorch_utils import normalize_by_day device = torch.device('cuda:0') pool_capacity = 10 class QuantlabCalculator(AlphaCalculator): def __init__(self, data, target: Optional[Expression]): self.data = data if target is None: # Combination-only mode self.target_value = None else: self.target_value = normalize_by_day(target.evaluate(self.data)) def _calc_alpha(self, expr: Expression) -> Tensor: return normalize_by_day(expr.evaluate(self.data)) def _calc_IC(self, value1: Tensor, value2: Tensor) -> float: return batch_pearsonr(value1, value2).mean().item() def _calc_rIC(self, value1: Tensor, value2: Tensor) -> float: return batch_spearmanr(value1, value2).mean().item() def make_ensemble_alpha(self, exprs: List[Expression], weights: List[float]) -> Tensor: n = len(exprs) factors: List[Tensor] = [self._calc_alpha(exprs[i]) * weights[i] for i in range(n)] return sum(factors) # type: ignore def calc_single_IC_ret(self, expr: Expression) -> float: value = self._calc_alpha(expr) return self._calc_IC(value, self.target_value) def calc_single_rIC_ret(self, expr: Expression) -> float: value = self._calc_alpha(expr) return self._calc_rIC(value, self.target_value) def calc_single_all_ret(self, expr: Expression) -> Tuple[float, float]: value = self._calc_alpha(expr) return self._calc_IC(value, self.target_value), self._calc_rIC(value, self.target_value) def calc_mutual_IC(self, expr1: Expression, expr2: Expression) -> float: value1, value2 = self._calc_alpha(expr1), self._calc_alpha(expr2) return self._calc_IC(value1, value2) def calc_pool_IC_ret(self, exprs: List[Expression], weights: List[float]) -> float: with torch.no_grad(): ensemble_value = self.make_ensemble_alpha(exprs, weights) return self._calc_IC(ensemble_value, self.target_value) def calc_pool_rIC_ret(self, exprs: List[Expression], weights: List[float]) -> float: with torch.no_grad(): ensemble_value = self.make_ensemble_alpha(exprs, weights) return self._calc_rIC(ensemble_value, self.target_value) def calc_pool_all_ret(self, exprs: List[Expression], weights: List[float]) -> Tuple[float, float]: with torch.no_grad(): ensemble_value = self.make_ensemble_alpha(exprs, weights) return self._calc_IC(ensemble_value, self.target_value), self._calc_rIC(ensemble_value, self.target_value) instruments: str = "csi300", target = 'Ref(close, -20) / close - 1' from quantlab.datafeed.dataloader import Mongoloader data_train = Mongoloader(symbols=[],start_date='20100101',end_date='20191231') calculator_train = QuantlabCalculator(data_train, target) pool = AlphaPool( capacity=pool_capacity, calculator=calculator_train, ic_lower_bound=None, l1_alpha=5e-3 ) env = AlphaEnv(pool=pool, device=device, print_expr=True)
环境生成一个表达式:

def try_new_expr(self, expr: Expression) -> float: ic_ret, ic_mut = self._calc_ics(expr, ic_mut_threshold=0.99) if ic_ret is None or ic_mut is None or np.isnan(ic_ret) or np.isnan(ic_mut).any(): return 0. self._add_factor(expr, ic_ret, ic_mut) if self.size > 1: new_weights = self._optimize(alpha=self.l1_alpha, lr=5e-4, n_iter=500) worst_idx = np.argmin(np.abs(new_weights)) if worst_idx != self.capacity: self.weights[:self.size] = new_weights self._pop() new_ic_ret = self.evaluate_ensemble() increment = new_ic_ret - self.best_ic_ret if increment > 0: self.best_ic_ret = new_ic_ret self.eval_cnt += 1 return new_ic_ret
基本逻辑就是,强化学习环境生成一个“因子”,计算因子的ic,合成后的因子的ic,如果更优,则保存。循环这个过程。
这基本算是一个通用框架。
只是按qlib的实现,所有的算子都是一个类。递归的方式来计算的。
这里可以有更优的实现方式,明天咱们继续。
Quantlab的开源平台的系统代码,请前往星球下载:(每周五定期更新一次,含20%+的策略集)
系统源代码发布v2.4供下载,带年化32.1%策略,简化GUI逻辑
+ self._feature.name.lower()
@property
def is_featured(self): return True
无论是基于深度强化学习,还是gplearn遗传算法,只要是多标的,多个symbols同时计算,那么在进行表达式运算时,肯定要groupby symbol或者甚至groupby date。
否则rolling是有问题的。
目前的依赖包:torch的cuda版本是需要根据你本机的显卡的版本来确定的,我电脑上的驱动版本比较老,是10.2,因此只能安装较低版本的pytorch。
经过一番折腾:
已经开始端对端挖因子了:
吾日三省吾身
做一件事情,意义很重要。
工作也好,创业也罢。
有时候做一件事,就是纯粹为赚钱,比如年轻时候想赚快钱,合理合法,也没有什么问题。
比如当年那么多年靠SEO做外贸,其实主体工作就是满世界发垃圾链接,做排名。
只不过长期主义的事情,需要一个更大更持久的意义。
先辈们是有信仰,甚至不惜牺牲个人生命为代价,在追求一些东西。
意义,可以是利益,更多不是。
意义是个人赋予的。
达芬奇创造的意义,爱迪生发明的意义,对于未知的渴求,对世界的好奇心。
咱们不使用qlib作为数据源,
而是使用咱们自己的框架里的Mongoloader。
Caculator的代码比较简单,就是根据表达式来计算IC值。
论文的代码都是使用torsor来计算的,我考虑直接使用pandas的函数也可以,后期再转化为torch的tensor。
环境生成一个表达式:
基本逻辑就是,强化学习环境生成一个“因子”,计算因子的ic,合成后的因子的ic,如果更优,则保存。循环这个过程。
这基本算是一个通用框架。
只是按qlib的实现,所有的算子都是一个类。递归的方式来计算的。
这里可以有更优的实现方式,明天咱们继续。
Quantlab的开源平台的系统代码,请前往星球下载:(每周五定期更新一次,含20%+的策略集)
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103640
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!