
因子挖掘的流水线,一定是量化投资的未来。
分解下来,
一是数据,最常用的量价数据,无论是高频还是日频,对于我们处理没什么影响。
二是挖掘流程。gplearn或者深度强化学习,这也是通过框架。
三、扩展函数集,这个是可以积累的,比如ts_rank,甚至各种技术指标。
四、因子合成:加权,线性,或者树模型,深度学习。
五、回测,止损,投资体系。
六、实盘对接
后续我们会围绕这些主题,持续完善咱们的quantlab。按星球惯例,预计明天统计更新迭代后的代码。【星球优惠券】AI量化实验室——量化投资的星辰大海
从上面的路线图来,回测系统只占其中一小部分,新手一般认为这基本就是全部。其实不是。
市场上开源的量化回测系统很多,而且你自己实现一个简单的也超级容易,星球里有好几个版本。另外,回测到实盘,或者说,所谓“无缝切换”,其实不是什么大问题,broker,获取数据的方式,本身就不一样,只是少一点代码罢了,不必为了兼容实盘而兼容。实盘系统本身比回测更简单。
我一直在考虑回测系统,希望功能要够,足够简单,这样我们才能专注在策略和因子上,而不是与框架“做斗争”。
回测系统按运行方式有三类:向量化,时间驱动,事件驱动。
一般现在市面上主流是时间驱动,就是按bar来循环。真正的事件驱动pyalgotrade显得有点多余。这个好处是与实盘的运行机制一样,vnpy早看也是,后来改成时间驱动,因为调试起来更加容易。
按如上规划:回测系统够用即可,重点策略,核心是因子。
数据自动更新之类的,也不在回测系统范围内,自行加载CSV即可。
下载期货主连合约数据:

import akshare as ak from datetime import datetime import pandas as pd ''' 0 V0 dce PVC连续 1 P0 dce 棕榈油连续 2 B0 dce 豆二连续 3 M0 dce 豆粕连续 4 I0 dce 铁矿石连续 5 JD0 dce 鸡蛋连续 6 L0 dce 塑料连续 7 PP0 dce 聚丙烯连续 8 FB0 dce 纤维板连续 9 BB0 dce 胶合板连续 10 Y0 dce 豆油连续 11 C0 dce 玉米连续 12 A0 dce 豆一连续 13 J0 dce 焦炭连续 14 JM0 dce 焦煤连续 15 CS0 dce 淀粉连续 16 EG0 dce 乙二醇连续 17 RR0 dce 粳米连续 18 EB0 dce 苯乙烯连续 19 LH0 dce 生猪连续 20 TA0 czce PTA连续 21 OI0 czce 菜油连续 22 RS0 czce 菜籽连续 23 RM0 czce 菜粕连续 24 ZC0 czce 动力煤连续 25 WH0 czce 强麦连续 26 JR0 czce 粳稻连续 27 SR0 czce 白糖连续 28 CF0 czce 棉花连续 29 RI0 czce 早籼稻连续 30 MA0 czce 甲醇连续 31 FG0 czce 玻璃连续 32 LR0 czce 晚籼稻连续 33 SF0 czce 硅铁连续 34 SM0 czce 锰硅连续 35 CY0 czce 棉纱连续 36 AP0 czce 苹果连续 37 CJ0 czce 红枣连续 38 UR0 czce 尿素连续 39 SA0 czce 纯碱连续 40 PF0 czce 短纤连续 41 PK0 czce 花生连续 42 FU0 shfe 燃料油连续 43 SC0 ine 上海原油连续 44 AL0 shfe 铝连续 45 RU0 shfe 天然橡胶连续 46 ZN0 shfe 沪锌连续 47 CU0 shfe 铜连续 48 AU0 shfe 黄金连续 49 RB0 shfe 螺纹钢连续 50 WR0 shfe 线材连续 51 PB0 shfe 铅连续 52 AG0 shfe 白银连续 53 BU0 shfe 沥青连续 54 HC0 shfe 热轧卷板连续 55 SN0 shfe 锡连续 56 NI0 shfe 镍连续 57 SP0 shfe 纸浆连续 58 NR0 ine 20号胶连续 59 SS0 shfe 不锈钢连续 60 LU0 ine 低硫燃料油连续 61 BC0 ine 国际铜连续 62 IF0 cffex 沪深300指数期货连续 63 TF0 cffex 5年期国债期货连续 64 IH0 cffex 上证50指数期货连续 65 IC0 cffex 中证500指数期货连续 66 TS0 cffex 2年期国债期货连续 ''' symbol = 'V0' df = ak.futures_main_sina(symbol="V0", start_date="19900101", end_date=datetime.now().strftime('%Y%m%d')) print(df) df.rename(columns={'日期':'date','开盘价':'open', '最高价':'high', '最低价':'low','收盘价':'close', '成交量':'volume','持仓量':'open_interest','动态结算价':'vwap'}, inplace=True) from config import DATA_DIR df.to_csv(DATA_DIR.joinpath(symbol+'.csv'),index=None)
数据格式已经处理好了。
新增CSVLoader:
from config import DATA_DIR_CACHE_H5, DATA_DIR import os class CSVDataloader(Dataloader): def __init__(self, path:WindowsPath, symbols, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): super(CSVDataloader, self).__init__(path, symbols, start_date, end_date) def _load_dfs(self): dfs = [] csvs = os.listdir(self.path.resolve()) for csv in csvs: df = pd.read_csv(self.path.joinpath(csv).resolve(), index_col=None) df.set_index('date', inplace=True) dfs.append(df) return dfs
因子通过表达式计算:
gplearn也是整合到这里,信号计算之后,进行回测。
代码和数据请前往星球下载:
吾日三省吾身
昨天与一位大模型公司CEO吃饭,兄弟是前知名上市公司CTO,早就财富自由。现在是为了理想而战,
这是最佳的工作状态,不必畏首畏尾,纯粹为兴趣而战,享受过程中的快乐与心流状态。
当然,谁都有需要焦虑的事情。
比如,我们聊起的主题,孩子上初中了,教育分流的事情。
我们都是高考受益的一代人,对于好大学和学历是有执念的。
但孩子学习这个事情吧,未必都可以强求。
大家会说,未来的事,谁知道呢。尽管我们劝别人都说“儿孙自有儿孙福”,但时代的一粒沙,落在个人身上就是一座山。
记得20年前,刚出校园时,大家聊起北京户口。很多朋友说,户口的作用也就是孩子读书,20年后,没准不需要了呢,或者你把孩子送出国了呢?
20年过去了,似乎更重要的。能送出国的家庭寥寥。很多朋友陷入孩子一上初中,不得不将孩子送回老家上学的困境。
未来是不可预知的。
谁知道会发生什么?
不必去焦虑未来,但要充分做好准备。
比如多读书,书中有几乎一切问题的答案和解决方案。
专注自己的成长,但行好事,莫问前程。
用做科研的方式做投资。——那天好兄弟提醒我身上还有“科学家”气质,科学家暂时还不敢担,但还算一个不错的工程师,技术与极客,好奇心与探索未知领域的精神。
我做事情,需要强逻辑。而传统金融投资偏艺术甚至玄学;好在量化把它往科学侧拉了拉,我们做AI量化更应该建立科学的研究体系。
加上最近在思考的“人生的使命”。——我们需要“Calling(召唤感)”的目标。
好在前沿私募大玩家已经是这个实践体系了:Quantlab3.0进展,结合Quant4.0的思考:全自动,可解释AI量化是未来
咱们星球快800人的,我让我有机会近距离对一些100亿私募的同学做一些调研。
A公司:2022年成立,目前团队12人,其中核心投研人员7人(包括CTA3人,股票策略2人,IT模型迭代2人),管理规模1个亿。
策略为传统多因子模型,其中4成量价策略基础,3成基本面数据、2成期限结构及1成另类因子模型作为辅助,通过波动率的风险预算模型做风控(硬止损)。调仓周期3-5天。属于非日内,短线。
业绩表现:成立来年化10.4%,最大回撤7.42%。
B公司:2022年6月成立,主要深耕量化选股及CTA策略。量化团队现有7人。指数增强策略:筛选后的2400只票池中,通过多因子选股的合成信号,选取200-400只股票。
多因子模型由40%量价因子+60%另类及基本面因子构成,因子基本由人工挖掘,追求逻辑性。调仓周期3-5天,今年以前超额收益14.11%。
CTA策略:截面策略占总策略的75%以上,平均持仓周期5天,通过主观团队协助搭建的高频基本面因子日间频率获取截面alpha,叠加不超过25%的时序策略增加策略灵活性,时序平均持仓周期1-3天。子策略也是多因子模型框架构成,杠杆使用率为一倍,交易品种35~40个,单品种占比不超过整体仓位的4%。
年化收益率15.79%,最大回撤不超过1%,规模2个亿左右。
这种调研每周抽时间会持续做,给大家分享。
我更偏好管理规模相对小,比如亿级别,对于咱们而言更有参考性。
团队规模小,量化可能就2-3人,如果你技术够,一个人也能顶上。另外多因子是私募正道,这个毫无疑问,小团队一般没有到分钟或者订单流,而是日间短周期。因子策略有截面有时序,目前看截面不少(这一点上修正了我的一些观点),因子现阶段仍然主观为主,当然大家都在积极拥抱AI。
因此,总结出来对星球下一步的规划:
策略的核心就是因子,我们希望帮大家的主观转为量化,这一定是趋势。而且不依赖明星交易员的感觉,应该是福特“流水线“式的因子工厂。
1、因子流水线:因子评价与筛选体系。
2、因子组合与机器学习。
3、深度学习端对端挖因子。
4、止损与交易系统与实盘。
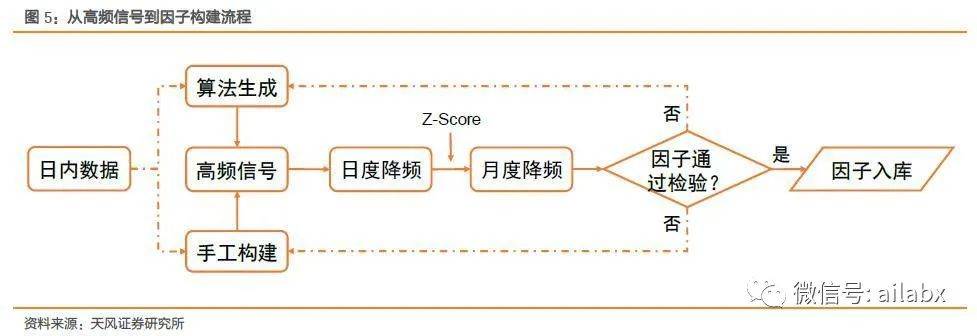
昨天咱们把gplearn挖因子的流程基本跑通了:
340万名表,开上亿豪车,住6亿美金毫宅:科技才是人类的星辰大海;quantlab3.0整合gplearn因子挖掘。
今天要把gplearn整合到咱们quantlab3.0的回测环境里。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103595
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!