
感恩过往数年的陪伴与支持。
100天的时候,已经是1年多以前的事情了。
1000天计划的核心是“持续”。需要辅以“专注”,“做减法”效果更佳。在一个足够窄的领域付出足够多,你就是专家。专家就能创造价值,进而实现自己的价值。 AI量化实验室 100天复盘
专注,做减法,依然是当下的心得。
只不过100天的时候,计划是研报复现与前沿论文复现。
在之后的1年多里,我们践行了很多方向:
ETF轮动系列策略开发:
年化28.5,最大回撤23.5%,夏普比1.19,红利低波动+创成长ETF的趋势轮动策略(代码+数据)
系统源代码发布v2.4供下载,带年化32.1%策略,简化GUI逻辑
低代码甚至零代码开发策略。
streamlit方向:”零代码量化平台“,点击几下鼠标即可生成一个可实盘策略(平台源码+数据)
wxpython方向:点击几下就可以生成一个策略:wxpython加上“积木式”AI量化回测引擎(代码+数据下载)
机器学习方向:
gplearn因子挖掘:分钟级数据效果还是非常好的:年化81%,最大回撤10%。(quantlab3.1源代码+数据下载)
端到端因子挖掘框架:DeepAlphaGen V1.0代码发布,支持最新版本qlib
quantlab3.0系统代码预发布:附年化42%+的机器学习策略案例(小时级数据+代码下载)
支持数个开源底层回测引擎(backtrader, pybroker, qlib等):
AI量化系统Quantlab V1.7代码更新,支持pybroker引擎,含大类资产风险平价及波动率策略源码集,平均年化15%
backtrader的策略模板,结合“积木式”的策略模块(全系统代码下载)。
重写qlib的alpha158年因子表达式,年化40%(代码+数据共享)
还有很多,看似很散,但有一条主线,就是——如何尽力给星球同学们提供更大的价值。
AI量化是一个很大的领域,前沿都在做各种各样的探索;同时,星球同学也提出了各种诉求,实盘的呼声也比较高。
2023年的总结,一个词:“探索”。
探索了几乎所有的低层回测框架;
探索了多种交易标的,ETF,可转债,股票,期货。
探索了交易模式:从规则量化到机器学习,深度学习。
2024年,关键词:专注——用科研的方法专注于AI量化投资(从因子到策略)。
效果导向,结果导向。
量化投资的结果导向就是——“可实盘的策略”。
当前私募的主流是“因子策略”,其中因子挖掘是核心。
前沿研究是“端到端”因子挖掘,甚至是策略生成。
下面是我在星球分享的一些思考:
新年是一个起点,计划不仅是一种仪式感,而是战略和导航。
财富自由核心是什么?积累资产。
积累资产无外乎两种:
1、买入资产(投资,包含但不限于股票,基金,房地产,一切可交易,会增值的东西)。
2、自己创建资产(广义的创业,超级个体)。
一、买资产的核心要素:一是本金;二是认知。
普通人本金靠省,积累这个没办法。
2024提升自己的投资认知,比如理财方法等。期货,加密货币。。。但风险控制第一,赚自己认知范围内的钱。
我推荐的是专栏里写的10%长期年化,适合所有普通人。
让账户自动运转:构建一个稳健的长期年化10%(回撤小于6%)的大类资产组合
二、然后把心思花在建仓资产上。
你可以创建专栏,录个视频课,写本书,开发个网站,写个软件都可以。
这些统称内容或者知识,作品,产品。
内容输出取决于输入+你自己的深度思考,多读书,多学习,持续输入,终身学习。
变现的逻辑取决于别人的价值,以及你的渠道杠杆。
2024年,不忘初心,来年一起努力,拥抱财富自由:
闲庭独坐对闲花,轻煮时光慢煮茶,不问人间烟火事,任凭岁月染霜华。


星球下一步的计划: 针对ETF,股票,期货建立因子挖掘流水线。
今天的两件事情:
1、补充gplearn函数集,向world quant 101对齐,同时争取与咱们因子表达式复用。
2、发布3.1版本。
使用我们准备好的脚本,下载好螺纹钢的主连合编数据,后续咱们也会准备分钟级数据等,但对于咱们的因子挖掘没有本质的影响:
symbol = 'RB0'
df = ak.futures_main_sina(symbol="V0", start_date="19900101", end_date=datetime.now().strftime('%Y%m%d'))
df.rename(columns={'日期': 'date', '开盘价': 'open', '最高价': 'high', '最低价': 'low', '收盘价': 'close', '成交量': 'volume',
'持仓量': 'open_interest', '动态结算价': 'vwap'}, inplace=True)
print(df['date'])
df['date'] = df['date'].apply(lambda x: str(x).replace('-', ''))
from config import DATA_DIR
df.to_csv(DATA_DIR.joinpath('futures').joinpath(symbol + '.csv'), index=None)
print(df)

导入gpquant的代码,实现在适合咱们因子挖掘的23个基础函数(四则运算,正余弦等)和23个时间序列函数(偏度,峰度,相关性以及常见的技术指标):
function_map = {
"square": square1,
"sqrt": sqrt1,
"cube": cube1,
"cbrt": cbrt1,
"sign": sign1,
"neg": neg1,
"inv": inv1,
"abs": abs1,
"sin": sin1,
"cos": cos1,
"tan": tan1,
"log": log1,
"sig": sig1,
"add": add2,
"sub": sub2,
"mul": mul2,
"div": div2,
"max": max2,
"min": min2,
"mean": mean2,
"clear by cond": clear_by_cond3,
"if then else": if_then_else3,
"if cond then else": if_cond_then_else4,
"ts delay": ts_delay2,
"ts delta": ts_delta2,
"ts pct change": ts_pct_change2,
"ts mean return": ts_mean_return2,
"ts max": ts_max2,
"ts min": ts_min2,
"ts sum": ts_sum2,
"ts product": ts_product2,
"ts mean": ts_mean2,
"ts std": ts_std2,
"ts median": ts_median2,
"ts midpoint": ts_midpoint2,
"ts skew": ts_skew2,
"ts kurt": ts_kurt2,
"ts inverse cv": ts_inverse_cv2,
"ts cov": ts_cov3,
"ts corr": ts_corr3,
"ts autocorr": ts_autocorr3,
"ts maxmin": ts_maxmin2,
"ts zscore": ts_zscore2,
"ts regression beta": ts_regression_beta3,
"ts linear slope": ts_linear_slope2,
"ts linear intercept": ts_linear_intercept2,
"ts argmax": ts_argmax2,
"ts argmin": ts_argmin2,
"ts argmaxmin": ts_argmaxmin2,
"ts rank": ts_rank2,
"ts ema": ts_ema2,
"ts dema": ts_dema2,
"ts kama": ts_kama4,
"ts AROONOSC": ts_AROONOSC3,
"ts WR": ts_WR4,
"ts CCI": ts_CCI4,
"ts ATR": ts_ATR4,
"ts NATR": ts_NATR4,
"ts ADX": ts_ADX4,
"ts MFI": ts_MFI5,
}
另外,gplearn要用于因子挖掘,还有一个重要的扩展,就是fitness适应度(也就是我们的优化目标,可以是年化收益,夏普比等,大家下载代码后,也可以自行扩展):
fitness_map = {
"annual return": ann_return,
"sharpe ratio": sharpe_ratio,
"mean absolute error": mean_absolute_error,
"mean square error": mean_square_error,
"direction accuracy": direction_accuracy,
}
gplearn的代码:
import numpy as np import pandas as pd from gplearn import fitness # 数据集 from gplearn.genetic import SymbolicRegressor train_data = pd.read_csv('../data/IC_train.csv', index_col=0, parse_dates=[0]) test_data = pd.read_csv('../data/IC_test.csv', index_col=0, parse_dates=[0]) feature_names = list(train_data.columns) train_data.loc[:, 'y'] = np.log(train_data['Close'].shift(-4) / train_data['Close']) train_data.dropna(inplace=True) from examples.backtest import BackTester class SymbolicTestor(BackTester): # 回测的设定 def init(self): self.params = {'factor': pd.Series} @BackTester.process_strategy def run_(self, *args, **kwargs) -> dict[str: int]: factor = np.array(self.params['factor']) long_cond = factor > 0 short_cond = factor < 0 self.backtest_env['signal'] = np.where(long_cond, 1, np.where(short_cond, -1, np.nan)) self.construct_position_(keep_raw=True, max_holding_period=1200, take_profit=None, stop_loss=None) # 回测环境(适应度函数) comm = [0 / 10000, 0 / 10000] # 买卖费率 bt = SymbolicTestor(train_data, transact_base='PreClose', commissions=(comm[0], comm[1])) # 加载数据,根据Close成交,comm是买-卖 def score_func_basic(y, y_pred, sample_weight): # 因子评价指标 try: _ = bt.run_(factor=y_pred) factor_ret = _['annualized_mean']/_['max_drawdown'] if _['max_drawdown'] != 0 else 0 # 可以把max_drawdown换成annualized_std except: factor_ret = 0 return factor_ret def my_gplearn(function_set, my_fitness, pop_num=100, gen_num=3, tour_num=10, random_state = 42, feature_names=None): # pop_num, gen_num, tour_num的几个可选值:500, 5, 50; 1000, 3, 20; 1000, 15, 100 metric = fitness.make_fitness(function=my_fitness, # function(y, y_pred, sample_weight) that returns a floating point number. greater_is_better=True, # 上述y是输入的目标y向量,y_pred是genetic program中的预测值,sample_weight是样本权重向量 wrap=False) # 不保存,运行的更快 # gplearn.fitness.make_fitness(function, greater_is_better, wrap=True) return SymbolicRegressor(population_size=pop_num, # 每一代公式群体中的公式数量 500,100 generations=gen_num, # 公式进化的世代数量 10,3 metric=metric, # 适应度指标,这里是前述定义的通过 大于0做多,小于0做空的 累积净值/最大回撤 的评判函数 tournament_size=tour_num, # 在每一代公式中选中tournament的规模,对适应度最高的公式进行变异或繁殖 50 function_set=function_set, const_range=(-1.0, 1.0), # 公式中包含的常数范围 parsimony_coefficient='auto', # 对较大树的惩罚,默认0.001,auto则用c = Cov(l,f)/Var( l), where Cov(l,f) is the covariance between program size l and program fitness f in the population, and Var(l) is the variance of program sizes. stopping_criteria=100.0, # 是对metric的限制(此处为收益/回撤) init_depth=(2, 3), # 公式树的初始化深度,树深度最小2层,最大6层 init_method='half and half', # 树的形状,grow生分枝整的不对称,full长出浓密 p_crossover=0.8, # 交叉变异概率 0.8 p_subtree_mutation=0.05, # 子树变异概率 p_hoist_mutation=0.05, # hoist变异概率 0.15 p_point_mutation=0.05, # 点变异概率 p_point_replace=0.05, # 点变异中每个节点进行变异进化的概率 max_samples=1.0, # The fraction of samples to draw from X to evaluate each program on. feature_names=feature_names, warm_start=False, low_memory=False, n_jobs=1, verbose=1, random_state=random_state) # 函数集 function_set=['add', 'sub', 'mul', 'div', 'sqrt', 'log', # 用于构建和进化公式使用的函数集 'abs', 'neg', 'inv', 'sin', 'cos', 'tan', 'max', 'min', # 'if', 'gtpn', 'andpn', 'orpn', 'ltpn', 'gtp', 'andp', 'orp', 'ltp', 'gtn', 'andn', 'orn', 'ltn', 'delayy', 'delta', 'signedpower', 'decayl', 'stdd', 'rankk' ] # 最后一行是自己的函数,目前不用自己函数效果更好 my_cmodel_gp = my_gplearn(function_set, score_func_basic, random_state=0, feature_names=feature_names) # 可以通过换random_state来生成不同因子 my_cmodel_gp.fit(train_data.loc[:, :'rank_num'].values, train_data.loc[:, 'y'].values) print(my_cmodel_gp) # 策略结果 factor = my_cmodel_gp.predict(test_data.values) bt_test = SymbolicTestor(test_data, transact_base='PreClose', commissions=(comm[0], comm[1])) # 加载数据,根据Close成交,comm是买-卖 bt_test.run_(factor=factor) md = bt_test.summary() print(md.out_stats) print(bt.fees_factor) md.plot_(comm=comm, show_bool=True)
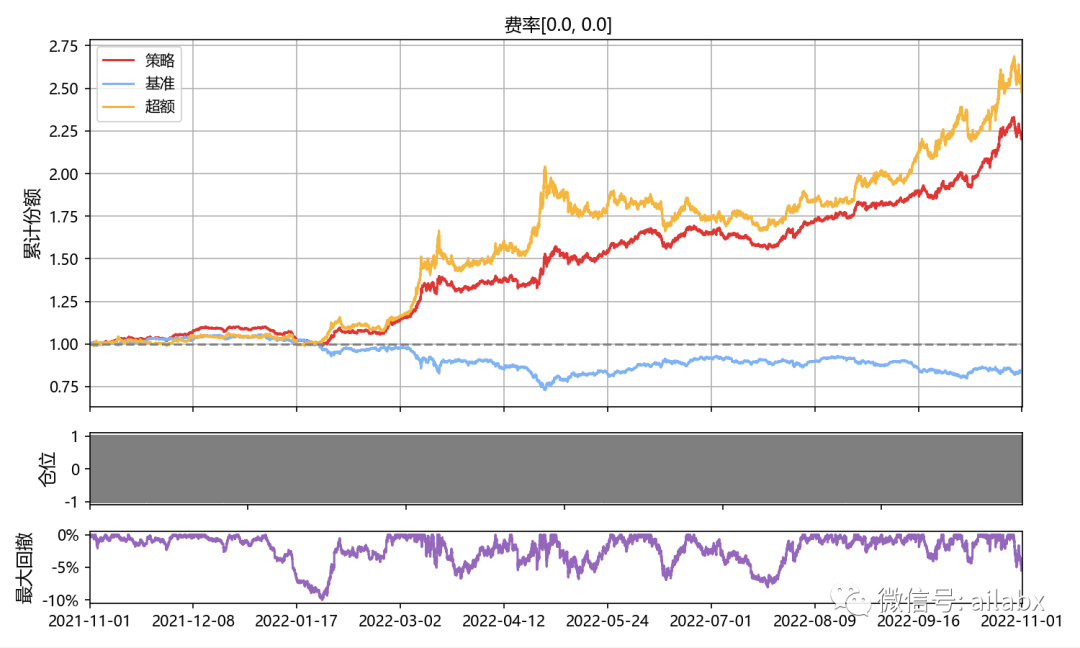
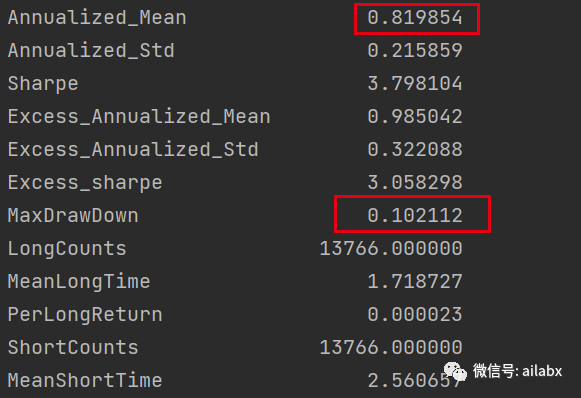
分钟线,如果不加费率,那么效果还是非常好的:年化81%,最大回撤10%。
代码已经发布,大家前往星球下载:【星球优惠券】AI量化实验室——量化投资的星辰大海
直接运行gpquant_demo.py即可。
吾日三省吾身
这几天,除了思考AI量化实验室2024年的方向,额外思考2024年的规划。
回溯了2021-2022年,基本就是定了一个数字,一个收益率。
可以说是美好的愿景,但目标无法转化为系统,意义是有限的。
Z计划=投资计划,500万,10%的长期年化收益。10%是投资能力的代表,使用基金做大类资产配置就可以“轻松”做到。这个需要拉长周期来看,而且是被动收入,建立好投资体系,等待美好自然发生即可。
更重要的是本金的积累。
对于多数普通人而言,如何建立B计划,发展另一条收入管道非常关键,你的收入结构如何优化,如何赚到更多工资以外、理财以外的收入(一开始不必刻意强调被动收入)。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103591
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!