
后续咱们会在几块重点领域发力:
1、数据,给大家提供好数据(含脚本),日线,或者分钟线,期货,ETF,可转债,加密货币等。——这一块持续积累。现在我们已经有期货“主连”合约的日线脚本,大家也可以自己下载更新数据。——以CSV的形式存储,方便大家自己更新。
CSVDataloader升级,可以指定目录,以及特定的子集合,比如csi300=沪深300成份股,比如ETF重点行业。
2、因子表达式,可以兼容gplearn的函数计算,这样表达式算出来与gplearn的表达式同构。可以使用gplearn的make_functions。也可以自动标注label。
gplearn默认只支持单标的时间序列,扩充为支持3D数据。
3、因子合成,使用树模型lightGBM或者lightGBM的Ranker,对多支标的进行排序。
单因子回测以及多因子轮动模块,可以固定下来模板。
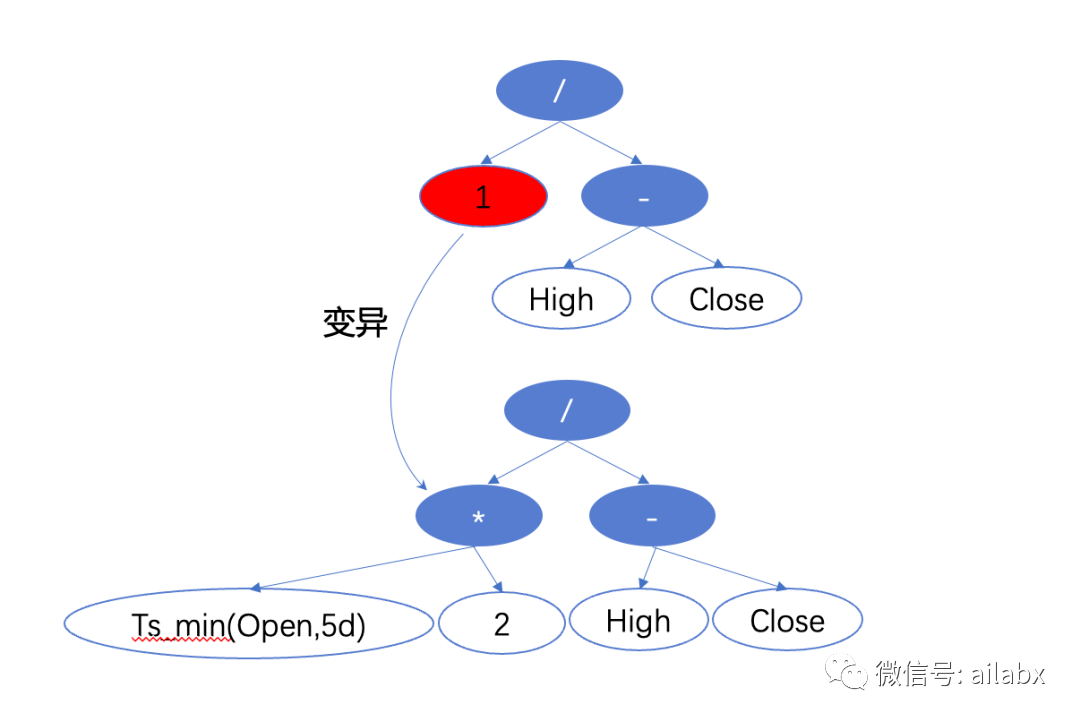

日拱一卒:gplearn引入自定义函数
from scipy.stats import rankdata def _rolling_rank(data): value = rankdata(data)[-1] return value def _rolling_prod(data): return np.prod(data) def _ts_sum(data): window = 10 value = np.array(pd.Series(data.flatten()).rolling(window).sum().tolist()) value = np.nan_to_num(value) return value def _sma(data): window = 10 value = np.array(pd.Series(data.flatten()).rolling(window).mean().tolist()) value = np.nan_to_num(value) return value def _stddev(data): window = 10 value = np.array(pd.Series(data.flatten()).rolling(window).std().tolist()) value = np.nan_to_num(value) return value def _ts_rank(data): window = 10 value = np.array(pd.Series(data.flatten()).rolling(10).apply(_rolling_rank).tolist()) value = np.nan_to_num(value) return value def _product(data): window = 10 value = np.array(pd.Series(data.flatten()).rolling(10).apply(_rolling_prod).tolist()) value = np.nan_to_num(value) return value def _ts_min(data): window = 10 value = np.array(pd.Series(data.flatten()).rolling(window).min().tolist()) value = np.nan_to_num(value) return value def _ts_max(data): window = 10 value = np.array(pd.Series(data.flatten()).rolling(window).max().tolist()) value = np.nan_to_num(value) return value def _delta(data): value = np.diff(data.flatten()) value = np.append(0, value) return value def _delay(data): period = 1 value = pd.Series(data.flatten()).shift(1) value = np.nan_to_num(value) return value def _rank(data): value = np.array(pd.Series(data.flatten()).rank().tolist()) value = np.nan_to_num(value) return value def _scale(data): k = 1 data = pd.Series(data.flatten()) value = data.mul(1).div(np.abs(data).sum()) value = np.nan_to_num(value) return value def _ts_argmax(data): window = 10 value = pd.Series(data.flatten()).rolling(10).apply(np.argmax) + 1 value = np.nan_to_num(value) return value def _ts_argmin(data): window = 10 value = pd.Series(data.flatten()).rolling(10).apply(np.argmin) + 1 value = np.nan_to_num(value) return value # make_function函数群 delta = make_function(function=_delta, name='delta', arity=1) delay = make_function(function=_delay, name='delay', arity=1) rank = make_function(function=_rank, name='rank', arity=1) scale = make_function(function=_scale, name='scale', arity=1) sma = make_function(function=_sma, name='sma', arity=1) stddev = make_function(function=_stddev, name='stddev', arity=1) product = make_function(function=_product, name='product', arity=1) ts_rank = make_function(function=_ts_rank, name='ts_rank', arity=1) ts_min = make_function(function=_ts_min, name='ts_min', arity=1) ts_max = make_function(function=_ts_max, name='ts_max', arity=1) ts_argmax = make_function(function=_ts_argmax, name='ts_argmax', arity=1) ts_argmin = make_function(function=_ts_argmin, name='ts_argmin', arity=1) ts_sum = make_function(function=_ts_sum, name='ts_sum', arity=1)
gplearn引入自定义函数是比较简单的,当然私募公司的积累,很多也在这些函数上。
大家更加关心的问题是:这是单支股票,如何进行多支股票的因子挖掘呢?
后文再分享
吾日三省吾身
真理在大炮的射程范围内。
放之四海而皆准。
可笑之事,就是如果你弱小,你还尝试跟人讲道理,谈规则。
新年唯一要做的,花心思的事情,10倍努力,去追求目标。
日拱一卒,功不唐捐。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103585
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!