
昨天咱们把StockRanker的主体架子搭起来了,数据预处理,模型训练都做好了。
bigquant内置的机器模型,就一个StockRanker。
其余都是社区成员自发开发的。
而Qlib入门级的demo,就是gbdt,就是使用lightGBM。
区别在于,lightGBM有三种模式,或者说多数的机器学习模型,都是三种有监督的学习模式: 分类(离散的标签),回归(连续的标签)和排序(推荐算法用得多,也是离散的label)。
qlib的示例都是连续的标签,比如”预测“未来第2天的收益率。
而bigquant是离散的标签,在收益率的基础上,对它进行了划分,比如20等级。
客观讲,个人认为后者更加科学。
精确预测股份运动,本身太难,甚至在某种意义上讲不可能。
但相对A比B好,这一点就容易一些。
动量轮动也是这个逻辑,我并没有说它会涨多少,而是说,按趋势惯性而言,A相对B,惯性更强一些。
排序相比分类,又更进一步。分类仍然是预测,而且相互也可以比较,比如预测收益在第5档,肯定比在第4档要好。
但这里有一个问题,都是第3档,就区分不出来。
而排序就很好的解决了这个问题。
这一点的处理上,bigquant是具备借鉴和实战意义的。qlib更偏学术。
之前咱们写过一些分析文章:
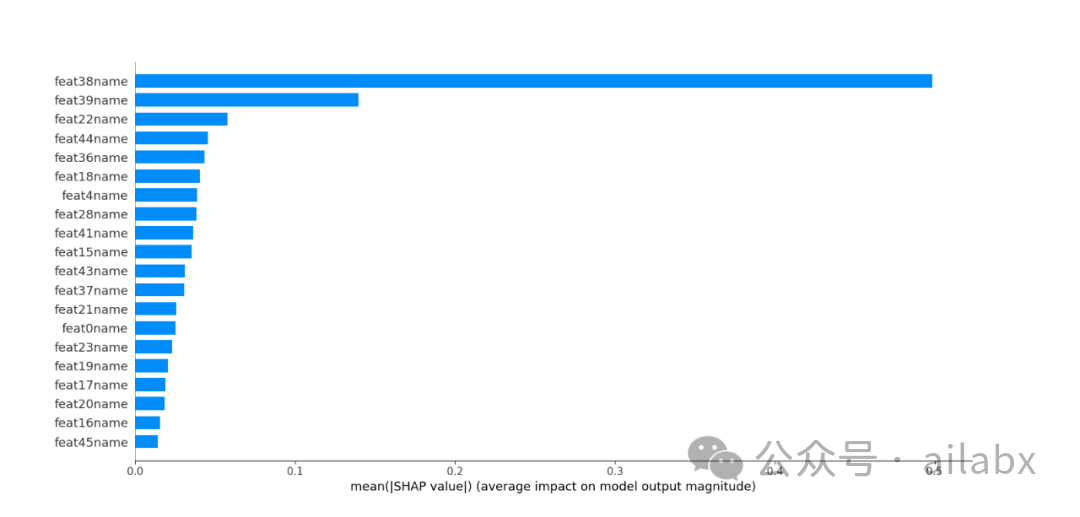
从特征重要性的筛选看,随机森林和lightGBM二者类似,都是那几个因子。就是说因子重要性。因子是具备稳定性的。
后面的问题,一是调参,二是如何解决过拟合。

沪深300”高低价通道“策略(附代码),梯度提升排序算法之dataset准备与模型实现
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103556
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!