
今天继续,这是平台化的第4篇文章,主要是场内基金的选择。当然需要对场内基金做一些分类,方便大家挑选。
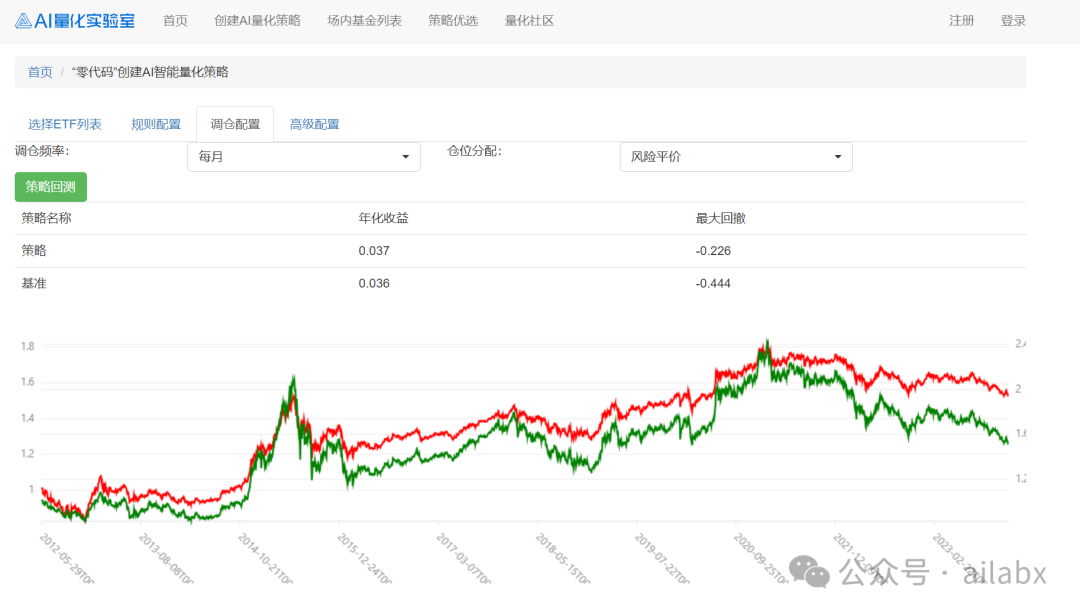
初步实现的效果如下:


界面逻辑基本成型,主体流程走通,当然后续最复杂的是“交易规则配置”,当然这也是“低代码”开发策略之核心。
倒不是技术上的难点,而是体验上如何做到门槛更低,但又要确保功能强大和扩展性。
# symbol, name, list_date, type:指数,ETF,LOF, 期货,转债, tags:多选:热门,宽基,QDII import json import pandas as pd from quant import mongo_utils def build_etfs(): df = pd.read_csv('etfs.csv') def get_type(name): if 'LOF' in name: return 'LOF' return 'ETF' df.rename(columns={'ts_code': 'symbol'}, inplace=True) df = df[['symbol', 'name', 'list_date', 'benchmark']] df['type'] = df['name'].apply(lambda name: get_type(name)) print(df) df['_id'] = df['symbol'] mongo_utils.write_df('basic', df, drop_tb_if_exist=True) if __name__ == '__main__': build_etfs()
习惯后端开发,多年没有写过js了,一直觉得这个东西不好调试,每次总想绕开它,之前试过streamlit, nicegui等等,但要变成真正的b/s结构的东西,整合起来怪怪的。
然后再寄希望于vue这样的前端工程化,数据驱动来解决问题。但引入npm, axios之类的反而更重。
还是之前说的那句话,两条路不知走哪一条——走难的那条。
其实jquery, bootstrap, 一些控件交互和操作,并没有那么难。
适应一下就好了。
吾日三省吾身
在大周期,大变局下,普通人为一份工作,能有多卑微?
战战兢兢,如履薄冰?
我们谈财富自由,谈梦想,谈的都在人生上限,想看看人生的潜力到底有多少。
而作为普通人,或者普通中产,在这个大变局下,更多人开始关心下限。
中年失业了怎么办?
越来越长的生命做什么?
我想,最好的办法,就是在还有工作的时候,学会与工作解耦。
去掉平台的加持和身份,你还有什么?
有没有独一无二的价值?
能没有“独立”生产和交付用户价值的能力?
大家知道,原生的GPLearn并不适合挖掘因子,主要存在以下几个问题:
1、gplearn只支持单标的,在CTA策略单标的可以,但单标的下挖掘的因子,很容易过拟合。
2、内置的函数不适合金融量化因子,需要自己扩展。而且原生的扩展,不支持常数项,比如SMA(10),这个10就是常数。
3、原生的fitness是ic和Rank IC,不支持夏普比或者卡玛比率这种。
4、而且网上能用的代码有限,版本鱼龙混杂,不成体系,或者文档不全。
5、传统的因子挖掘方法大多基于遗传规划(Genetic Programming)方法,这类方法具有收敛速度慢、超参数难以调优等局限;
网上的代码都是“暴改”之后的,且没有文档,demo未必能跑通。
我给大家跑通了一份,但是基于qlib的,与DeepAlpha同构,后续以这份代码为蓝本了。
大家直接pip install -r requirements.txt即可(python 3.8)


基于A股的qlib数据也会打包给大家,置于~/.qlib/qlib_data/cn_data_rolling目录下:


1、支持GPLearn, DSO以及强化学习的版本。
2、数据目前的A股全量数据,qlib格式。
3、支持多支股票同时挖掘。
4、支持多因子联合评测。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103506
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!