
今天的几项工作进展如下:
1、django-apscheduler,下载热门etf/lof数据。
2、把之前的策略发布一遍
3、对所有策略进行回测并保存数据。
4、网站的一些细节:vip的管理后台筛选,社区列表页的样式,文章可编辑和删除,评论可编辑和删除。
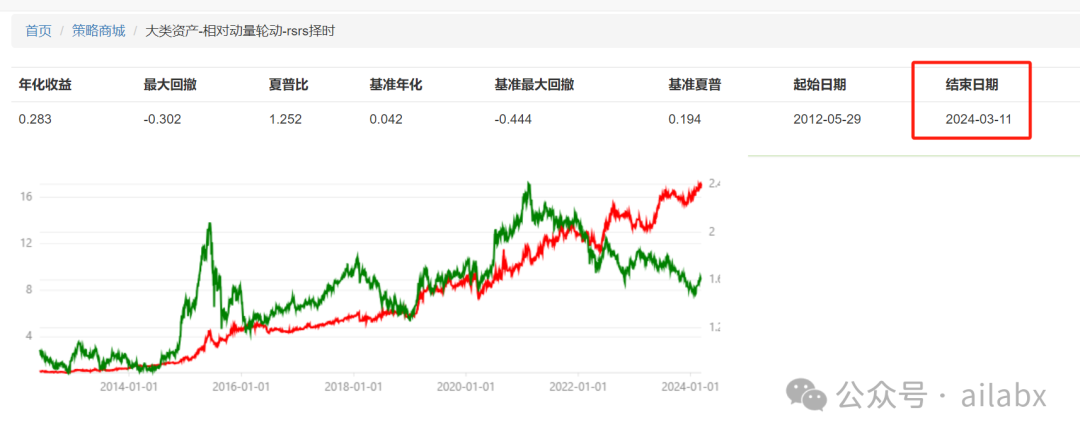
数据和日期已经更新到最新:


Django-Apscheduler使用不复杂,但在服务器上部署时,有一点需要特别注意,我们使用了多进程部署,那么会启动多个定时任务管理,会出现任务重复,下面我做了一个基于redis的“任务锁”。
def apscheduler_lock(func): @wraps(func) def wrapper(*args, **kwargs): lock_key = "apscheduler_lock" lock_value = "locked" # 连接到Redis redis_client = redis.Redis(host=SERVER_IP, port=6379) # 尝试获取锁 acquired_lock = redis_client.set(lock_key, lock_value, nx=True, ex=60) if acquired_lock: # 如果成功获得了锁,执行apscheduler程序 result = func(*args, **kwargs) # 执行完毕后释放锁 redis_client.delete(lock_key) return result else: # 没有获得锁,跳过执行apscheduler程序 return None # 可以根据需要返回其他信息 return wrapper
然后我们定期更新etf/lof数据,并且更新策略回测:
def job_update_quotes(): print(' 任务开始运行!{}'.format(time.strftime("%Y-%m-%d %H:%M:%S"))) print('job_test') items = mongo_utils.get_db()['basic'].find({'tags': {'$in': ['热门']}}) for item in items: symbol = item['symbol'] print('开始更新:{}'.format(symbol)) update_quotes(symbol) print('完成更新:{}'.format(symbol)) def start_scheduler(): # 监控任务 register_events(scheduler) # 这个event 这个会有已经被废弃的用法删除线,我不知道这个删除了 ,还会不会好用 scheduler.add_job(job_update_quotes, 'interval', seconds=10) scheduler.add_job(run_strategies, 'cron', hour='20', minute='30', args=[], id='tasks', replace_existing=True) scheduler.start()
之后,我们需要把数据源切回到线上:
在咱们Quantlab3.7版本中,仍然使用CSVDataloader,在读CSV文件时,会判断symbol_date.csv,如果不存在,尝试从服务器中读取,若读到数据,则覆盖symbol_date.csv。
class CSVDataloader(Dataloader): def __init__(self, path:WindowsPath, symbols, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')): super(CSVDataloader, self).__init__(path, symbols, start_date, end_date) # 尝试创建当天文件夹 self.today_path = path.joinpath(datetime.now().date().strftime('%Y%m%d')) self.today_path.mkdir(exist_ok=True) def _try_get_from_server(self, symbol): URL = 'http://127.0.0.1:8000/api/quotes/{}'.format(symbol) try: items = requests.get(URL).json()['data'] return pd.DataFrame(items) except: return None def _read_csv(self, csvs, symbol): file = symbol + '.csv' if file in csvs: print('从本地读取:{}'.format(file)) df = pd.read_csv(self.today_path.joinpath(file), index_col=None) else: # 从服务器更新 df = self._try_get_from_server(symbol) if df is not None: print('从服务器读取:{}'.format(symbol)) df.to_csv(self.today_path.joinpath(file), index=False) else: print('获取数据失败:{}'.format(symbol)) df['date'] = df['date'].apply(lambda x: str(x)) df.set_index('date', inplace=True) df['symbol'] = symbol df.index = pd.to_datetime(df.index) df.sort_index(inplace=True, ascending=True) df = df.loc[self.start_date:, :] return df
吾日三省吾身
人在社会中的关系统称为“生产关系”。
人生有一件很重要的事情,就是在社会中,找到你自己作为“生产者”的定位。
你要为社会生产出什么有价值的产品?
因此,除了开源AI量化系统之外,把系统平台化很重要,经过过去10来天的努力,网站的雏形已经落成且上线了。
后续会持续优化,提升价值与体验。
创业板动量成长指数选取创业板市场中具有良好成长能力和动量效应的50只股票组成的指数。该指数反映了创业板中成长能力良好、动量效应显著的上市公司整体运行情况。所谓成长能力望成为未来市场的领导者。而动量效应则是指这些公司近期股价走势较好。
红利低波动指数选取市场上50只流动性好、连续分红、红利支付率适中、每股股息正增长以及股息率高且波动率低的证券作为样本。
两者有较低的相关性,很适合做轮动策略。

每日一策略

AI量化平台开发
继续收拾AI量化平台细节。
这里说明下,为何要下定决心自己开发论坛。咱们线上的版本,借用了一些开源的东西,这一次的版本是我从0开始写的。
从长期主义的角度,自己写的代码维护起来更容易,更有积累。
而且从长远来看,这并没有多大的工作量。
说实在,打算拿100天搞定量化平台(目前是第10天,平台已经初见样子),再拿100天搞定Futter开发App都是小Case,如果确实有必要的话。
当然,咱们的重心是策略和因子,如何帮大家轻松赚到钱。——这个初心和理念是不变的。
昨天咱们写的贴子列表,基本就是搞定CURD,评论也是:发布,列表呈现。
这几天使用django, 从model到 form到view的感受下来。
djang确实把DRY做到极致,ListView, CreateView, DetailView, FormView,而且还可以排列组合。
一开始学习肯定有一点成本,但熟悉之后,代码会组织得特别舒服,大量可复用,不会出错,可维护性也好。
比如下面的代码,文章详情页加评论列表,以及加上评论发布功能。
若使用普通View,就是手动查询文章object,评论list,然后生成Form。
class ArticleDetailView(FormView, DetailView): model = Article form_class = CommentForm # success_url = '/' def get_success_url(self): return reverse_lazy('bbs:article_detail', kwargs=self.kwargs) def get_context_data(self, **kwargs): context = super().get_context_data(**kwargs) context['comments'] = Comment.objects.filter(article=self.kwargs.get('pk')) return context def form_valid(self, form): article = self.get_object() # 获取当前文章对象 user = self.request.user # 获取当前用户 content = form.cleaned_data['content'] # 获取表单内容 c = Comment(article=article, author=user, content=content) c.save() return super().form_valid(form)
对比原生代码——也还好就是了:
def ArticleDetail(request, pk:int): article = Article.objects.get(pk=pk) form = CommentForm() comments = Comment.objects.filter(article=pk).order_by('-pub_time') if request.method == "POST": form = CommentForm(request.POST) form.instance.author = request.user form.instance.article = article if form.is_valid(): form.save() form = CommentForm() return render(request, 'bbs/article_detail.html', {**locals()})
之前的最新版本Quantlab:
Quantlab3.6代码发布——重写创业板择时策略:年化20%, 回撤18.8%(代码+数据下载)
现在还不太完善,但基本的骨架有了,方便咱们后续分享因子和策略——“勿在浮沙筑高台”。
花这一周时间打基础是对的,当然还有不少细节,比如首次加载慢的问题,发贴无法粘贴图片等。
策略发布向导还没有完成。
当然,咱们策略平台化只进行了11天,已经算效率很高了。
下周计划:1、所有ETF/LOF数据盘后更新
2、所有策略定时运行,保存结果
3、星球会员权限功能:网站特殊标的,可下载所有公开策略
4、发布Quantlab3.7:Quantlab支持从服务器直接加载数据,下载的策略,可以Quantlab里无缝运行。5、网站细节的持续改进。其他想做的事情,大家感兴趣也可以参与进来:两个方向:1、基于大模型的金融投资智能体。2、基于Flutter开发通用端。
昨天在星球里分享的华泰金融工程的研报: 多智能体与因子挖掘。
这里我们来拆解下,后续择机代码实现。
这篇研报总结起来:基于GPT和多智能体系统构建端到端的量价因子挖掘系统。
一共有3个智能体协同构成:FactGPT, CodeGPT和EvalGPT。
FactorGPT负责构建因子表达式,采用了Few-Shot方式,在提示中加入已有的因子示例。要求模型直接输出因子的名称、数学表达式和含义。

这一步特别关键,相当于让大模型“仿写”因子表达式,而且还要解释含义。
CodeGPT,负责将因子表达式转换为可自动执行的程序,并计算结果;
设定模型可自主调用或自行生成算子,使得代码可执行性更高。模型生成代码后,将运行代码文件,若有报错信息抛出,模型将根据报错信息修改代码文件。模型将不断迭代上述过程直到代码文件可以运行,直至成功运行。
CodeGPT就是根据上一步写的表达式,自行写代码。
EvalGPT,负责对因子计算结果进行回测检验,同时生成优化建议,并可将建议返回给FactorGPT,进而继续优化该因子。这一步是调用因子回测工具。
研报出具的效果还不错,无论是rank ic还是因子分层的单调性上。


为了让大模型能够更加自动化地完成高复杂度任务,构建更为复杂且具备影响力的应用,探索基于大模型的多智能体(Multi-Agent)框架,智能体本身的主动性、反应性等能力大幅扩展大模型的能力边界,而多智能间的分工合作进一步显示出“群体的智慧”。
研报里使用的基础开源框架是:LangChain。
这个也是当前LLM开发中就用比较多的。当然咱们星球也会持续调研更多前沿的框架,共享给大家。
找时间,咱们写一篇LangChain开发多智能体的文章:

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103481
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!