
大模型挖掘因子还在继续开发:
zvt框架的使用:
![]()

直接pip安装zvt框架是无法成功的,我尝试了python3.7和python 3.8均是如此。当然这是开源项目的问题,也是咱们星球的核心价值——我把requirements整理了一下。
希望没有代码的,给出代码复现。有代码的,要能够运行起来;另外还需要有数据生态。
dash是plotly出的,金融绘图确实显得更高级一点,与streamlit类似,比streamlit门槛高一些:
这个示例是机器学习预测股票的走势并可视化:
from zvt.domain import Stock, Stock1dHfqKdata from zvt.ml import MaStockMLMachine Stock.record_data(provider="em") entity_ids = ["stock_sz_000001", "stock_sz_000338", "stock_sh_601318"] Stock1dHfqKdata.record_data(provider="em", entity_ids=entity_ids, sleeping_time=1) machine = MaStockMLMachine(entity_ids=["stock_sz_000001"], data_provider="em") machine.train() machine.predict() machine.draw_result(entity_id="stock_sz_000001")
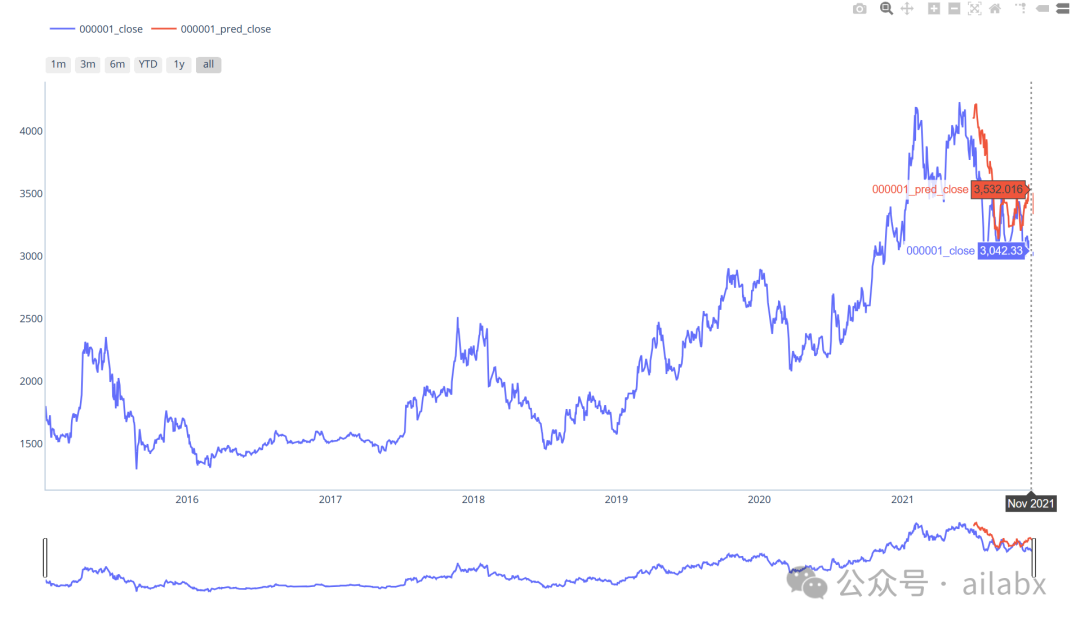
zvt这个框架的特别之处在于,内置了很多数据源,有公开的,有jq这样付费的,可以一键使用,而且api看起来非常简洁,值得分析一下。
代码启动后,在用户的目录下,多了很多个sqlite数据库文件:
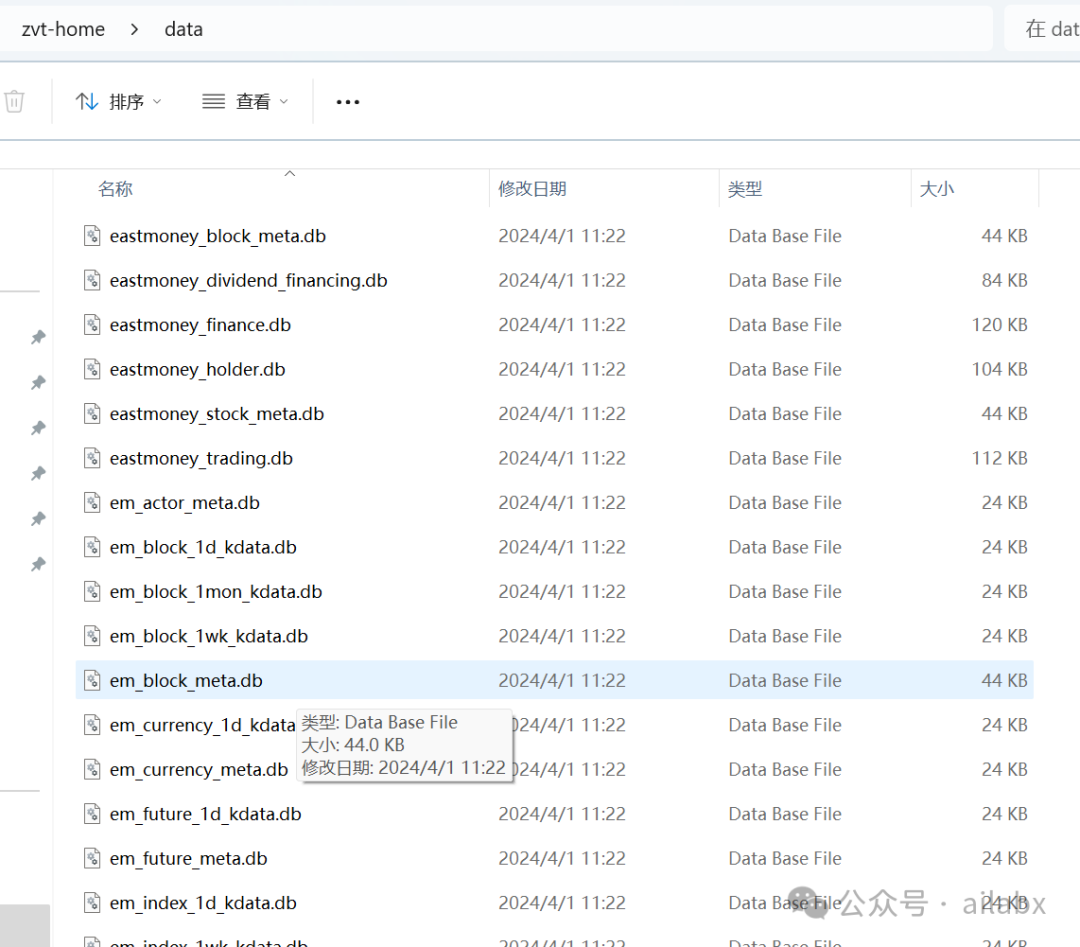
确实做了大量的数据存储,查询的工作:
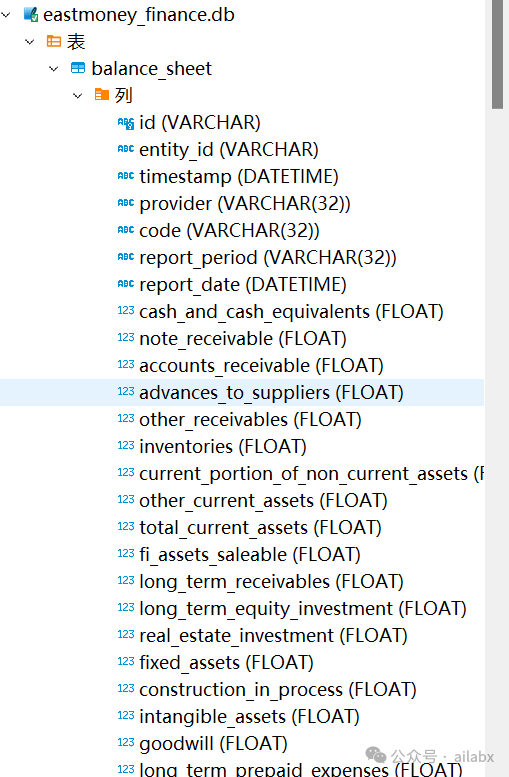
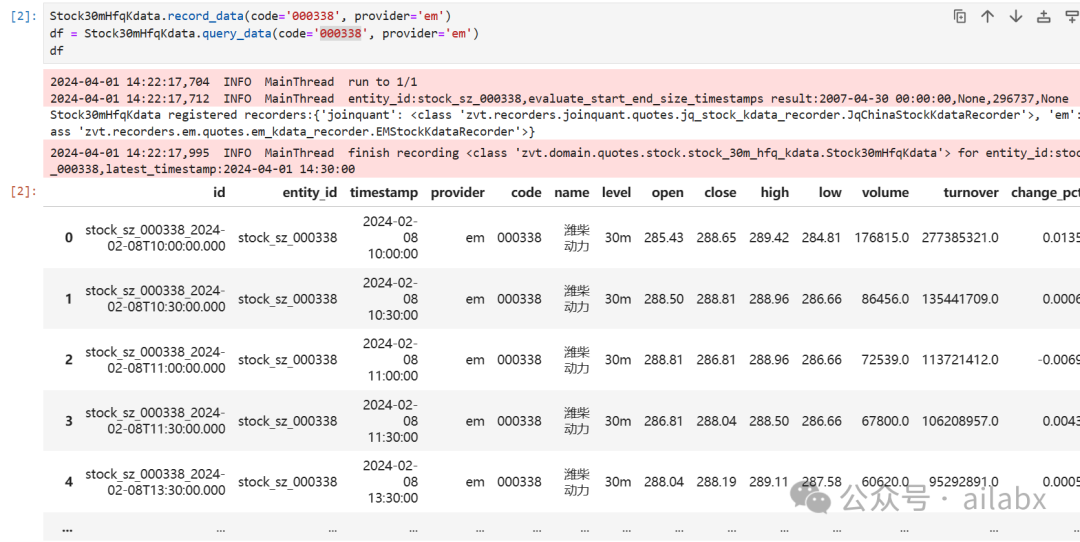
这是从东方财富免费接口下载股票30分钟后复权的数据:
龙虎榜的策略代码:
# -*- coding: utf-8 -*- from typing import List, Union import pandas as pd from zvt.contract import IntervalLevel from zvt.contract.factor import Factor, Transformer, Accumulator from zvt.domain import Stock, DragonAndTiger from zvt.trader import StockTrader class DragonTigerFactor(Factor): def __init__( self, provider: str = "em", entity_provider: str = "em", entity_ids: List[str] = None, exchanges: List[str] = None, codes: List[str] = None, start_timestamp: Union[str, pd.Timestamp] = None, end_timestamp: Union[str, pd.Timestamp] = None, columns: List = None, filters: List = [DragonAndTiger.dep1 == "机构专用"], order: object = None, limit: int = None, level: Union[str, IntervalLevel] = IntervalLevel.LEVEL_1DAY, category_field: str = "entity_id", time_field: str = "timestamp", keep_window: int = None, keep_all_timestamp: bool = False, fill_method: str = "ffill", effective_number: int = None, transformer: Transformer = None, accumulator: Accumulator = None, need_persist: bool = False, only_compute_factor: bool = False, factor_name: str = None, clear_state: bool = False, only_load_factor: bool = False, ) -> None: super().__init__( DragonAndTiger, Stock, provider, entity_provider, entity_ids, exchanges, codes, start_timestamp, end_timestamp, columns, filters, order, limit, level, category_field, time_field, keep_window, keep_all_timestamp, fill_method, effective_number, transformer, accumulator, need_persist, only_compute_factor, factor_name, clear_state, only_load_factor, ) def compute_result(self): self.factor_df["filter_result"] = True super().compute_result() class MyTrader(StockTrader): def init_factors( self, entity_ids, entity_schema, exchanges, codes, start_timestamp, end_timestamp, adjust_type=None ): return [ DragonTigerFactor( entity_ids=entity_ids, exchanges=exchanges, codes=codes, start_timestamp=start_timestamp, end_timestamp=end_timestamp, ) ] if __name__ == "__main__": trader = MyTrader(start_timestamp="2020-01-01", end_timestamp="2022-05-01") trader.run()
大模型落地&AGI实验室
OpenAI开启“IPhone时刻”,或者说“牛顿时刻”也不为过。
传统NLP任务有多难,大模型就有多惊艳,重要的是,我们发现了实现AGI(通用人工智能)的可能性!
但大模型需要的理念很深,资源很多,普通人和小公司望尘莫及。
论文层出不穷,如何跟进,怎么落地?
咱们”AGI实验室”的初心,为大家提供消费级笔记本上,就能运行的大模型解决方案的代码,充分释放LLM的潜能,躬身入局,拥抱这个技术浪潮。
这个星球是为大模型落地而设的,不是量化,不要混淆了。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103447
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!