
python的工具包pandas提供了内连接、外连接(左连接和右连接)和全连接方法,从而由dataframe生成信息更丰富的数据。本文简述pandas中的连接方法的应用举例。pandas中数据表连接的概念与一般数据库中对应的概念含义相同。
import panas as pd
创建两个表:products 和 customers,内容如下:
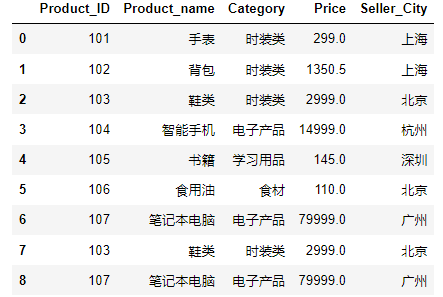
product=pd.DataFrame({
'Product_ID':[101,102,103,104,105,106,107,103,107],
'Product_name':['手表','背包','鞋类','智能手机','书籍','食用油','笔记本电脑','鞋类','笔记本电脑'],
'Category':['时装类','时装类','时装类','电子产品','学习用品','食材','电子产品','时装类','电子产品'],
'Price':[299.0,1350.50,2999.0,14999.0,145.0,110.0,79999.0,2999.0,79999.0],
'Seller_City':['上海','上海','北京','杭州','深圳','北京','广州','北京','广州']
})结果如下:

customer=pd.DataFrame({ 'id':[1,2,3,4,5,6,7,8,9], 'name':['李丽','王晓薇','张静','薛紫薇','刘婷','刘铭','王涛','吴小刚','刘谦'], 'age':[20,25,15,10,30,65,35,18,23], 'Product_ID':[101,0,106,0,103,104,0,0,107], 'Purchased_Product':['手表','NA','食用油','NA','鞋类','智能手机','NA','NA','笔记本电脑'], 'City':['上海','北京','广州','深圳','深圳','北京','杭州','北京','上海']})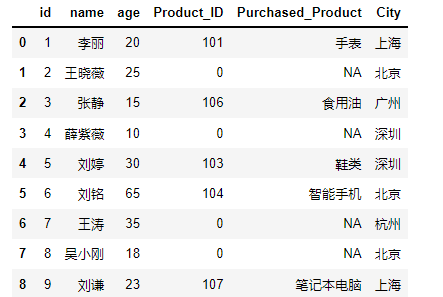
pandas提供的merge函数 和 内连接(inner join)
merge函数是pandas中操作dataframe数据常用的一个函数,其默认状态为执行内连接(inner join),要连接的两个dataframe为其中的两个参数,另一个参数是要建立的列名称。
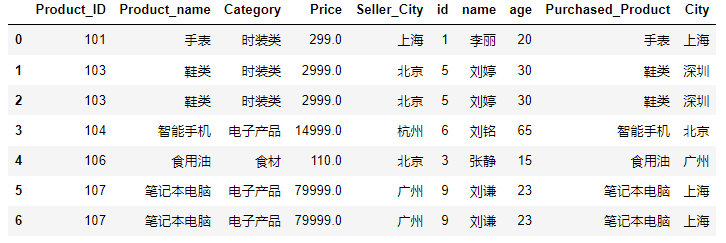
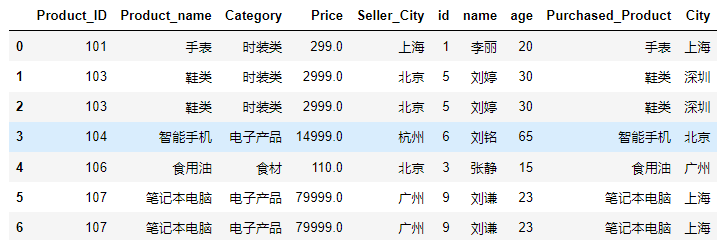
pd.merge(product,customer,on='Product_ID')基于product_id列,建立productcustomer两个表的内连接,结果如下图:
参数‘left_on’ 和 ‘right_on’ 分别为连表的键名称,可以用数组包括多个列。
pd.merge(product,customer,how='inner',left_on=['Product_ID','Seller_City'],right_on=['Product_ID','City'])运行结果如下,
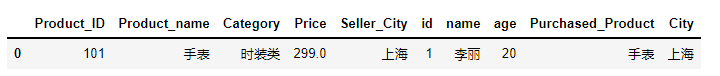
全连接(Full join)
如果想获取全部产品的信息,可以使用全连接,把product和customer两个dataframe结合起来。
pd.merge(product,customer,on='Product_ID',how='outer')运行结果如下:
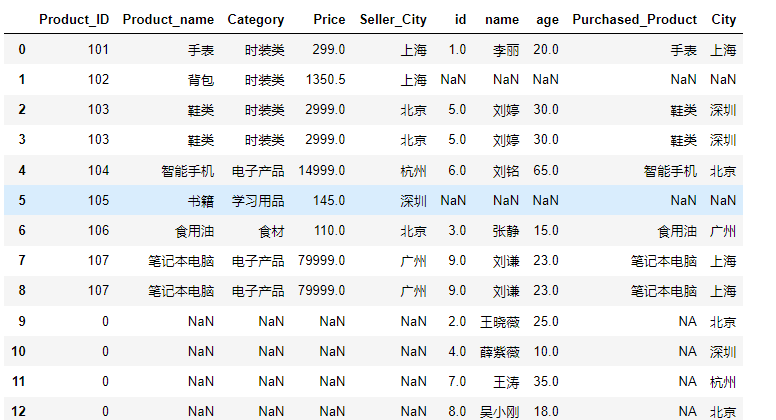
其中所有不匹配的行都标志为NaN。如果命令中有 indicator 参数,就会出现_merge列,
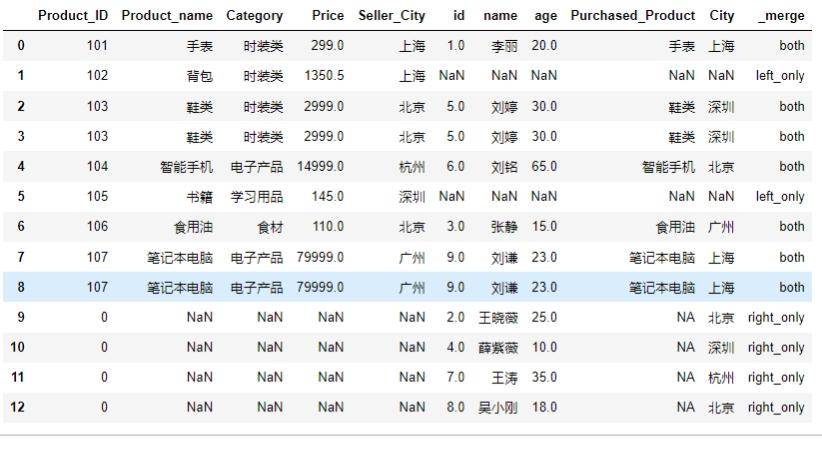
pd.merge(product,customer,on='Product_ID',how='outer',indicator=True)结果如下:
左连接(left join)
如果想获取购买了商品的消费者的信息,可以使用 左连接。左连接和右连接都属于外连接。
pd.merge(product,customer,on='Product_ID',how='left')执行结果如下,
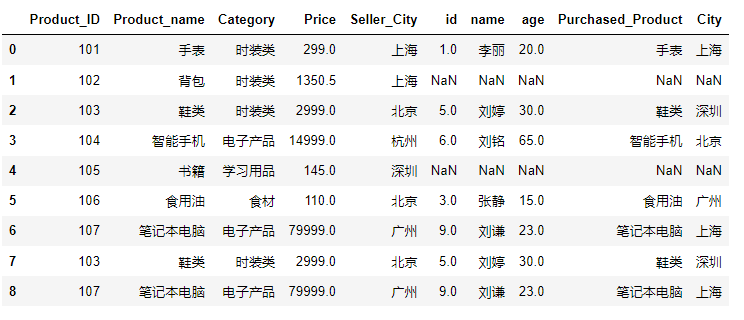
右连接(right join)
如果想得到包括购买商品信息的消费者的数据表,则可以使用右连接,
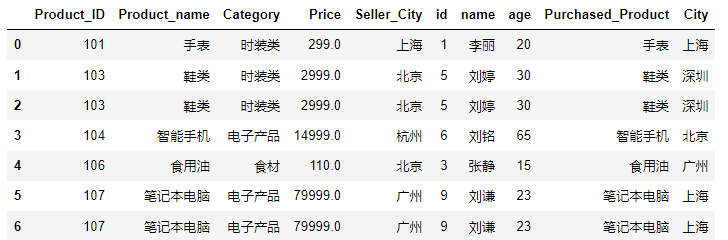
pd.merge(product,customer,on='Product_ID',how='right')结果如下图:

如何处理连接中出现的冗余/重复数据
建立一个product数据的副本,
product_dup=pd.DataFrame({
'Product_ID':[101,102,103,104,105,106,107,103,107],
'Product_name':['手表','背包','鞋类','智能手机','书籍','食用油','笔记本电脑','鞋类','笔记本电脑'],
'Category':['时装类','时装类','时装类','电子产品','学习用品','食材','电子产品','时装类','电子产品'],
'Price':[299.0,1350.50,2999.0,14999.0,145.0,110.0,79999.0,2999.0,79999.0],
'Seller_City':['上海','上海','北京','杭州','深圳','北京','广州','北京','广州']
})执行以下命令:
pd.merge(product_dup,customer,how='inner',on='Product_ID')结果如下图:
可以看到有重复的数据行,解决这一问题,可以在merge函数中使用 validate 参数,可设置为:‘one_to_one’, ‘one_to_many’, ‘many_to_one’, 和 ‘many_to_many’.
pd.merge(product_dup,customer,how='inner',on='Product_ID',validate='many_to_many')运行结果如下:
pandas中dataframe数据表连接的概念,和关系数据库以及SQL语言中的概念具有相同的含义。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76374
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!