
在python做数据分析,都会用到与SQL查询语句一样的操作,SQL语句是针对数据库中的数据表,而python中查询数据一般针对pandas的dataframe数据格式。本文以几个比较复杂的SQL查询语句为例,写出对应的pandas查询数据的命令。


数据为“王斌”和“李丽”两个人最近两年出差的飞行记录。
import pandas as pd
df = pd.DataFrame({'name': ['王斌', '王斌', '王斌', '李丽', '李丽'],
'destination': ['北京', '青岛', '兰州','深圳', '杭州'],
'dep_date': ['2021-02-02', '2021-01-01','2022-01-11', '2021-05-05','2022-01-11'],
'duration': [7, 21, 14, 10, 14]})
df结果如下:
name destination dep_date duration
0 王斌 北京 2021-02-02 7
1 王斌 青岛 2021-01-01 21
2 王斌 兰州 2022-01-11 14
3 李丽 深圳 2021-05-05 10
4 李丽 杭州 2022-01-11 14SQL查询语句1:
针对每个人的每次出行,查询其下一次出行时间(lead1)、下下次出行的时间(lead2),其上一次出行的时间(lag1)以及倒数第三次出行的时间(lag3)。
-- SQL查询语句1:
SELECT name
, destination
, dep_date
, duration
, LEAD(dep_date) OVER(ORDER BY dep_date, name) AS lead1
, LEAD(dep_date, 2) OVER(ORDER BY dep_date, name) AS lead2
, LAG(dep_date) OVER(ORDER BY dep_date, name) AS lag1
, LAG(dep_date, 3) OVER(ORDER BY dep_date, name) AS lag3
FROM df为了在pandas中获得同样的结果,使用shift()函数。
shift函数:LEAD() and LAG()
在pandas中,编写与SQL查询语句1相对应的命令。因为数据操作的逻辑相同,所以先对数据进行排序,这样做更效率更高,避免了多次对数据进行排序,代码如下:
df.sort_values(['dep_date', 'name'], inplace=True)
df.assign(lead1 = df['dep_date'].shift(-1),
lead2 = df['dep_date'].shift(-2),
lag1 = df['dep_date'].shift(),
lag3 = df['dep_date'].shift(3))查询数据结果如下图:
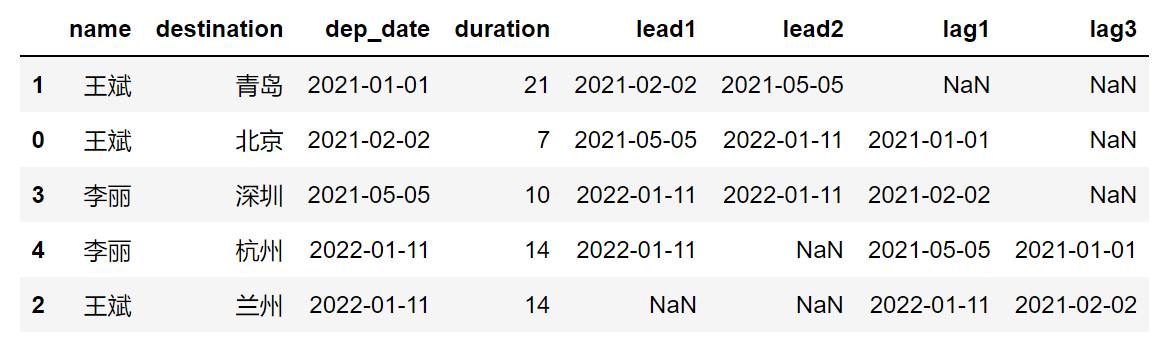
如果写成以下形式,查询效率就要差一些:
df.assign(lead1 = df.sort_values(['dep_date', 'name'])['dep_date'].shift(-1),
lead2 = df.sort_values(['dep_date', 'name'])['dep_date'].shift(-2),
lag1 = df.sort_values(['dep_date', 'name'])['dep_date'].shift(),
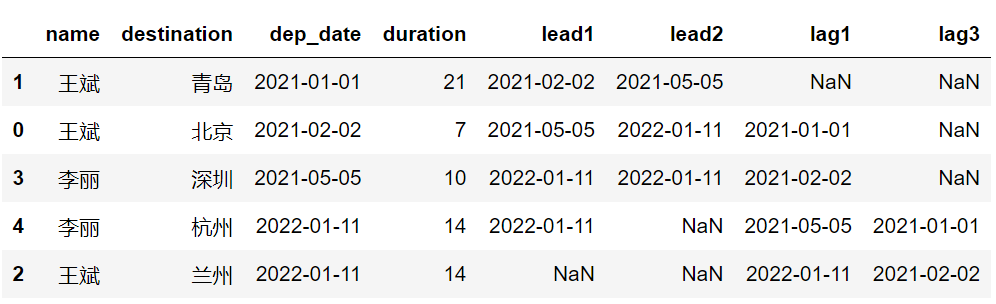
lag3 = df.sort_values(['dep_date', 'name'])['dep_date'].shift(3))结果如下图,其输出结果与前面的写法相同。
Date/datetime函数: DATENAME(), DATEDIFF(), DATEADD()
SQL查询语句2:
SELECT name
, destination
, dep_date
, duration
, DATENAME(WEEKDAY, dep_date) AS day
, DATENAME(MONTH, dep_date) AS month
, DATEDIFF(DAY,
LAG(dep_date) OVER(ORDER BY dep_date, name),
dep_date) AS diff
, DATEADD(DAY, day, dep_date) AS arr_date
FROM df这一查询要得到出行日期所属的星期名称(Sunday、Monday…..)、月份名称(month)、距离前一次飞行有多少天(diff)以及该次出行到达的日期(arr_date)。
先把出行数据中的列数据类型转换为适当的类型:
df['dep_date'] = pd.to_datetime(df['dep_date'])
df['duration'] = pd.to_timedelta(df['duration'], 'D')把dep_date 转换为 datetime 类型, 以便能够用 .dt 方法获得日期的年月日数据,如 df[‘dep_date’].dt.year 可以获得年份数据,这与SQL中的 DATEPART(YEAR, dep_date) 方法相同。
pandas中实现与SQL查询语句2结果相同的代码如下:
df.sort_values(['dep_date', 'name'], inplace=True)
df.assign(day = df['dep_date'].dt.day_name(),
month = df['dep_date'].dt.month_name(),
diff = df['dep_date'] - df['dep_date'].shift(),
arr_date = df['dep_date'] + df['duration'])输出结果如下图:
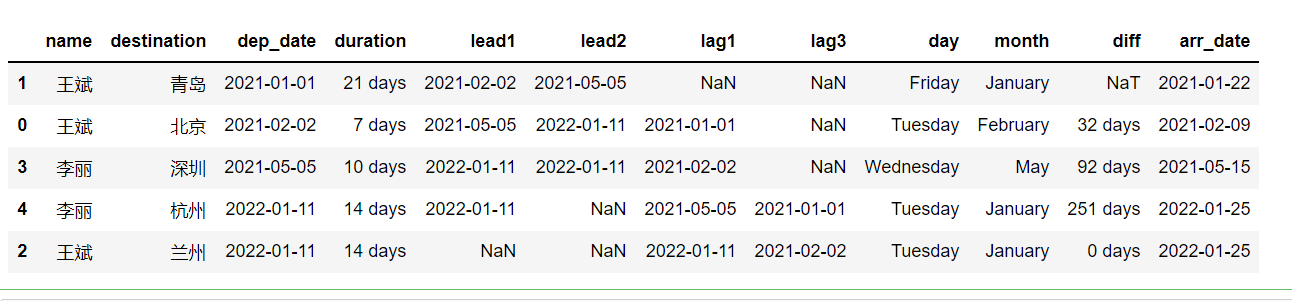
用 dtypes 属性查看一下 dataframe 中的列的类型,代码如下:
df.sort_values(['dep_date', 'name'], inplace=True)
df.assign(day = df['dep_date'].dt.day_name(),
month = df['dep_date'].dt.month_name(),
diff = df['dep_date'] - df['dep_date'].shift(),
arr_date = df['dep_date'] + df['duration']).dtypes结果如下图所示:
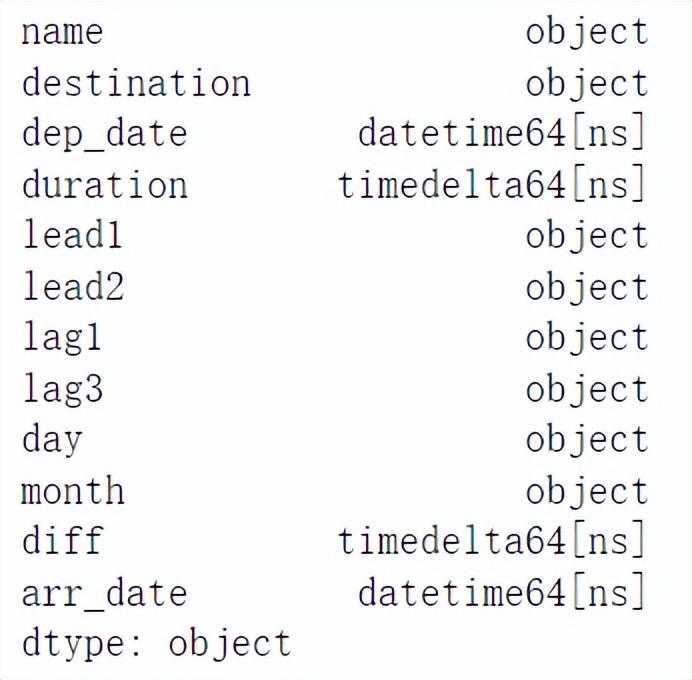
可以看出,两个日期之间的差、飞行时长的数据类型为 timedelta 类型。
排名函数(Ranking): ROW_NUMBER(), RANK(), DENSE_RANK()
在SQL语言中也有类似 ROW_NUMBER(), RANK(), DENSE_RANK() 的函数,其作用也相同,都是对某列数据做先后排名。基于 duration 数据,分别创建对应的列,能方便地使用这三个函数。使用 ROW_NUMBER() 函数 是 dataframe 中数据行的内置编号,这与其他两个函数不一样。
SQL查询语句3:
SELECT name
, destination
, dep_date
, duration
, ROW_NUMBER() OVER(ORDER BY duration, name) AS row_number_d
, RANK() OVER(ORDER BY duration) AS rank_d
, DENSE_RANK() OVER(ORDER BY duration) AS dense_rank_d
FROM df与上述SQL查询语句,可以在pandas 中使用 rank() 函数写成以下代码段:
df.sort_values(['duration', 'name']).assign(
row_number_d = df['duration'].rank(method='first').astype(int),
rank_d = df['duration'].rank(method='min').astype(int),
dense_rank_d = df['duration'].rank(method='dense').astype(int))输出结果如下图:
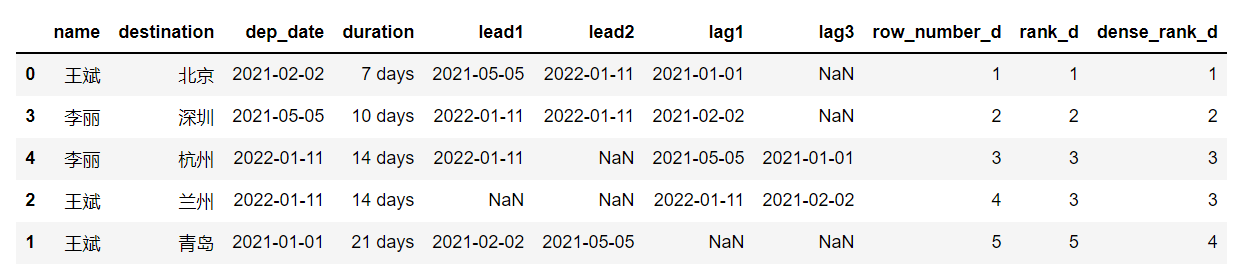
与前面两部分不一样的是,没有对数据进行排序;使用astype(int) 把浮点数表示的排名值转换为整数。
聚合窗口函数和数据切分(Aggregate window functions 和 partitioning)
SQL查询语句4:
SELECT name
, destination
, dep_date
, duration
, MAX(duration) OVER() AS max_dur
, SUM(duration) OVER() AS sum_dur
, AVG(duration) OVER(PARTITION BY name) AS avg_dur_name
, SUM(duration) OVER(PARTITION BY name ORDER BY dep_date
RANGE BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS cum_sum_dur_name
FROM dfwe will create column for the longest trip duration: max_dur, total duration for all trips: sum_dur, average duration of trip per person: avg_dur_name and cumulative sum of trip length for each person: cum_sum_dur_name.
找出飞行时间最长的出行(max_dur)、所有出行的飞行时间合计(sum_dur)、每个人出行的飞行时长均值(avg_dur_name)以及每个人飞行时长的累计时长(cum_sum_dur_name),并创建相应的列。
与之对应的pandas代码如下:
df.assign(max_dur=df['duration'].max(),
sum_dur=df['duration'].sum(),
avg_dur_name=df.groupby('name')['duration']
.transform('mean'),
cum_sum_dur_name=df.sort_values('dep_date')
.groupby('name')['duration']
.transform('cumsum'))输出数据的结果如下图:

以上数据是按 dep_date 排序的。因为pandas的广播属性,添加 max_dur 和 sum_dur 这样的聚合统计数据是很简单的。一般来说,如果在pandas中把一个标量值添加到新的一列,该值对所有行都是有效的;把groupby() 和 transform() 结合起来就可实现 PARTITION BY 的功能。
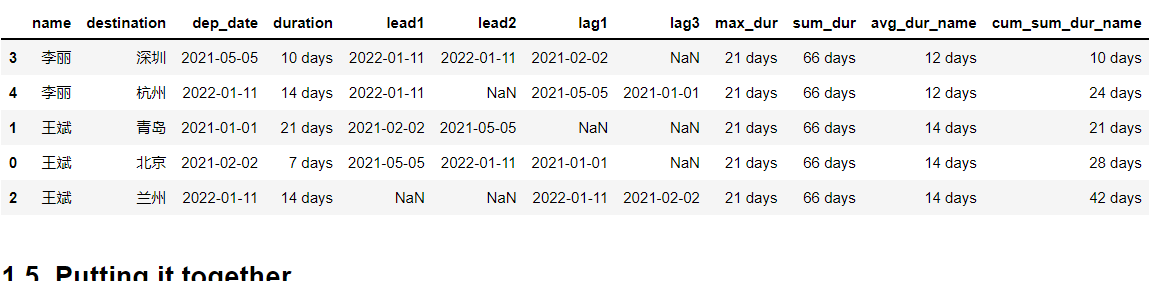
创建了 cum_sum_dur_name 列,可按该数据排序,相应的代码修改如下:
df.sort_values(['name', 'dep_date'], inplace=True)
df.assign(max_dur=df['duration'].max(),
sum_dur=df['duration'].sum(),
avg_dur_name=df.groupby('name')['duration']
.transform('mean'),
cum_sum_dur_name=df.groupby('name')['duration']
.transform('cumsum'))输出结果如下图所示:
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76369
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!