
有一些有意思的结论:
1、金融的信噪比太低,要么不拟合,要么过拟合的概率大。
2、前沿机器模型的能力强,模型不是问题,因些,我们搞AI量化,不需要在模型在发力。
3、目前看,根本不需要折腾深度学习引入复杂性,从统计能力角度,集成树模型足够了。方向应该是找更多数据、更好的因子。
4、基于树的排序学习,值得好好挖掘潜力。(BigQuant内置的StockRanker就是这个)
5、与不少私募对谈,信号策略依然是主流。多因子在尝试,机器学习只能说在观望、跟进及布局,多数没有创造生产力。
6、不少私募年初至今,回报还是很可观的。
7、每周例会,打算邀请一位私募、公募或者相关从业者,做深度交流。会议时间,形式,议题,会提前在星球通知,请大家关注。


下面是StockRanker的源码(基于lightGBM的排序学习):
import numpy as np import pandas as pd from sklearn.model_selection import train_test_split import lightgbm as lgb from lightgbm import log_evaluation, early_stopping callbacks = [log_evaluation(period=100), early_stopping(stopping_rounds=50)] from engine.models.model_base import ModelBase class LGBRanker(ModelBase): def __init__(self, name, load_model, feature_cols=None): super(LGBRanker, self).__init__(name, load_model) self.feature_cols = feature_cols self.label_col = 'label' def _prepare_groups(self, df): df['day'] = df.index group = df.groupby('day')['day'].count() # print(group.values) return group.values def predict(self, data): data = data.copy(deep=True) if self.feature_cols: data = data[self.feature_cols] try: pred = self.ranker.predict(data) except: print('error') pred = [None for _ in range(len(data))] return pred return pred def train(self, df: pd.DataFrame, split_date: str = None): if split_date: df_train = df[df.index < split_date] df_val = df[df.index >= split_date] else: df_train = df df_val = df query_train = self._prepare_groups(df_train.copy(deep=True)) query_val = self._prepare_groups(df_val.copy(deep=True)) ranker = lgb.LGBMRanker() ranker.fit(df_train[self.feature_cols], df_train[self.label_col], group=query_train, eval_set=[(df_val[self.feature_cols], df_val[self.label_col])], eval_group=[query_val], eval_at=[1, 2, 5], callbacks=callbacks) self.ranker = ranker print(ranker.n_features_) print(ranker.feature_importances_) print(ranker.feature_name_) score, names = zip(*sorted(zip(ranker.feature_importances_, ranker.feature_name_), reverse=True)) print(score) print(names)
吾日三省吾身
这两天可能写代码“用力过猛”,导致眼睛有点不舒服。
身体的反应,是一个很好的提醒,也让我“停”下来思考。
看电子书改成听书。听了两本书,都是于心理学,人生与死亡的话题。
当死亡拿出来讨论的时候,人生的格局往往会打开。
第一本书《生命的礼物》,这个礼物,它指的就是死亡。这是每个人的必修课。我们需要面对亲朋好友的离去,直至我们自己也要面对这个课题。
向死而生,人生是一个体验的单程。
另一本书《活出清醒的自我》。让你不再焦虑,愤怒,活出平静和喜乐,专注当下。
人生中,通常有两个情绪困扰,一是恐惧,担心不好的事情发生;二是焦虑,担心想要的迟迟不来。
前者的根源是外界的不确定性,内在的安全感的诉求;后者的根源在于欲望,得不到满足的欲望。
先说恐惧,我们要向内求,让心灵中立,以旁观者的态度,“冷冷”地审视,观察,体验发生的一切。——所谓“允许一切发生”的生活态度。
我们所觉知的,所谓“问题”,可能占不到5%,而且这些问题,99%不会发生。而另外95%我们压根没有意识到,里面有1%,可能会发生。——从概率上讲,你恐惧错了方向。
另外,即便发生了,99%你也能从容应对,就是增加了生命的阅历和谈资罢了。即便像蔡磊遇上的这种不治之症,让他的人生直接180度调头,甚至快要终结,他也留下了《相信》的力量,留下的企业家精神的光辉。
面对未来,不是说躺平,完全放任,无为而治。
就是做好当下能做好的所有事情,然后就不必多想了。像英语考试里的阅读理解,不能过度延伸。
——尽人事,听天命,允许一切发生。
关于第二种焦虑——欲望。一定程度的欲望是好的,这是人类文明向上的最原始的动力。关于欲望,允许想要的可能不发生,或者不那么达到预期(允许想要的东西可能不发生)。
你要如同能得到一样去努力,如同不能得到那般去生活。
做好当下应该做的事情,但行好事,莫问前程。
今天加上tensorflow(keras)的深度神经网络模型。
若是预测5天后的涨跌:训练集能到74.6%,测试集54.3%,比1天的好。
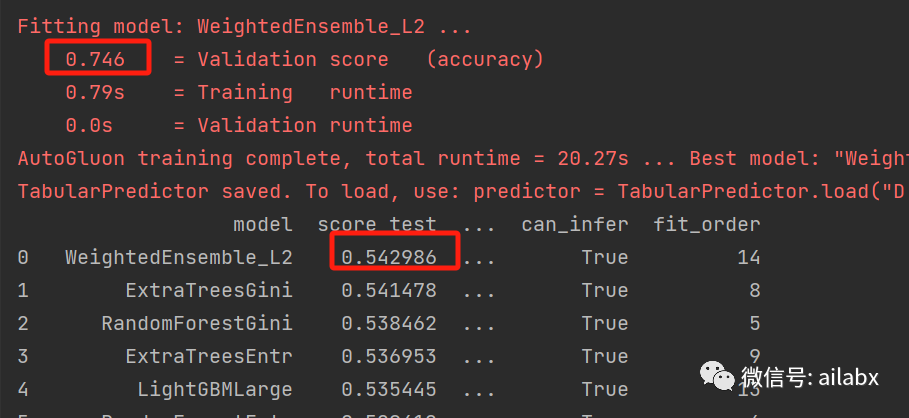
若是10天的收益率,训练集75.5%,测试集是57.6%。
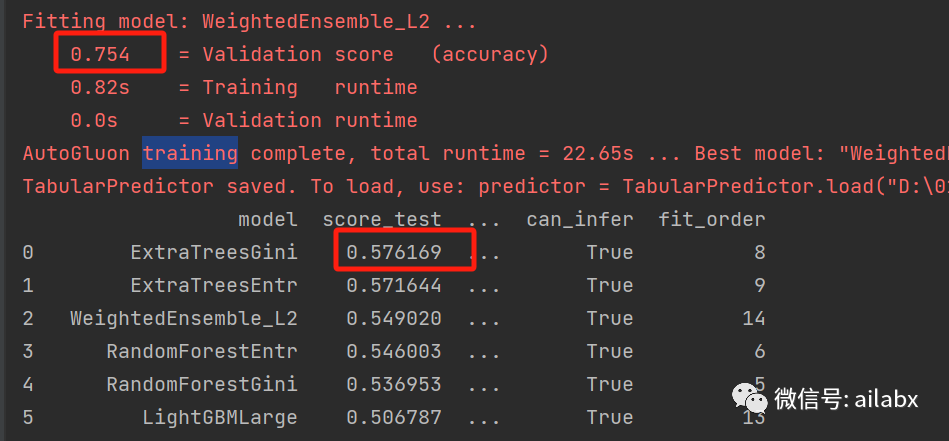
预测20天的收益率,训练集是84.6%,测试集是59.7%。
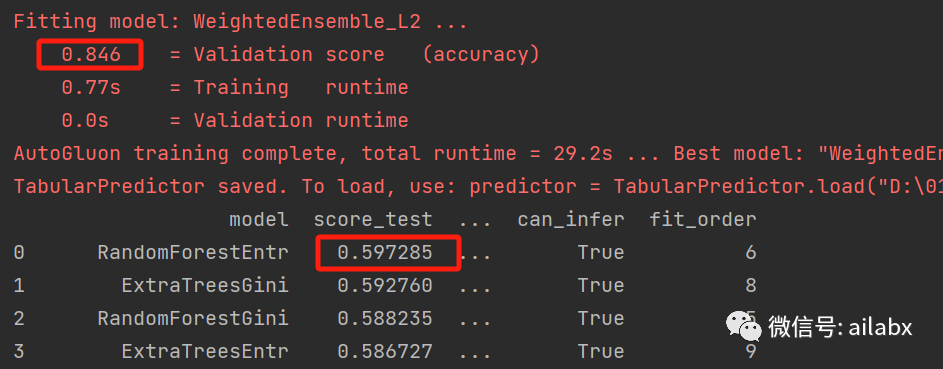
我修改了因子周期,基本也是这个规律。就是:“明天的涨跌很难预测,但一个月后的,准确率还是比较高”的。更远的,可能就很容易出现过拟合。(训练集拟合得特别好,但测试集还不如掷硬币)
再做一组实验,仅使用最原始的OHLCV数据:
预测20天后的收益率,训练集70.8%,测试集62.4%。
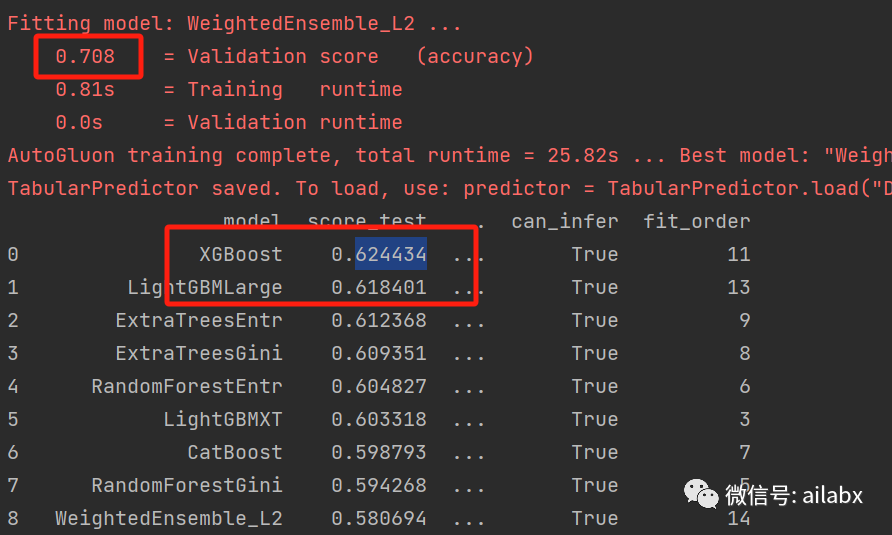
量化的好处之一就是做实验,所以,我“人肉”做了不少实验。
把因子简化到只有一个“收盘价”,相当于用历史收盘价序列,测试未来20天涨跌,测试集准确率还是63%。
我一狠心,使用随机序列测试,你猜怎么着,准备率仍然高达49%。。。
然后在收盘价的基础上,添加volume,准确率基本没变化,若是添加其他 价量因子,比如roc_20,则准确率会下降。。。
使用tensorflow(keras)实现DNN,来看看效果:
class TfModel(ModelBase): def create_model(self, dim, hl=1, hu=128, optimizer=Adam(lr=0.001)): model = Sequential() model.add(Dense(hu, input_dim=dim, activation='relu')) for _ in range(hl): model.add(Dense(hu, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy']) return model def train(self, df_train, df_test, label='label'): cols = list(df_train.columns).copy() cols.remove(label) df_train.dropna(inplace=True) train_data = df_train[cols] mu, std = train_data.mean(), train_data.std() train_ = (train_data - mu) / std print(train_) model = self.create_model(dim=len(cols), hl=1, hu=128) model.fit(train_,df_train[label], epochs=50, verbose=True, class_weight=cw(df_train,label)) print('评估测试集') test_data = df_test[cols] mu, std = test_data.mean(), test_data.std() test_ = (test_data - mu) / std print(model.evaluate(test_, df_test[label]))
测试集准确率是57.3%。
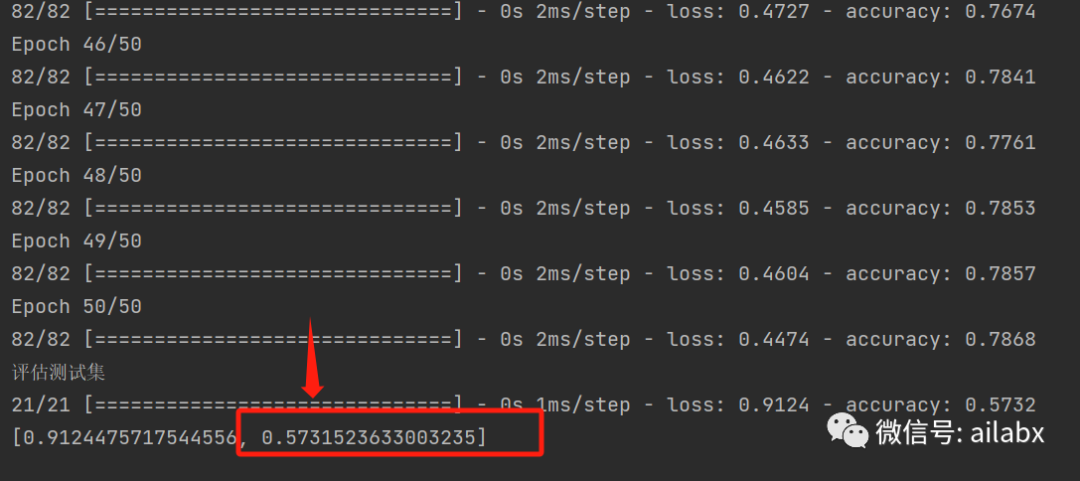
添加正则和Dropout防止过拟合:
def create_model(self,dim, hl=1, hu=128, dropout=False, rate=0.3, regularize=False, reg=l1(0.0005), optimizer=Adam(lr=0.001)): if not regularize: reg = None model = Sequential() model.add(Dense(hu, input_dim=dim, activity_regularizer=reg, activation='relu')) if dropout: model.add(Dropout(rate, seed=100)) for _ in range(hl): model.add(Dense(hu, activation='relu', activity_regularizer=reg)) if dropout: model.add(Dropout(rate, seed=100)) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy']) return model
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103788
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!