
许多A股交易者为了探究A股及其板块和个股的历史走势形态,都需要可靠的A股历史行情数据,一般都从网上找一些免费数据源下载,但是这类下载数据可能有滞后,甚至有些数据是否真实可靠不得而知。
为了克服这些问题,可以使用证券公司提供的客户端程序(有通达信版、同花顺版等)下载历史行情数据,每个交易日收盘15分钟后,即可下载。下载后的数据的格式和长度不一定满足自己的要求,可以用本文提供的python代码,本文也提供了整个操作过程的视频演示。
本文提供的历史行情数据处理的python代码文件,其中使用了多进程工具包 multiprocessing,以便充分发挥多核多线程CPU的能力,提高数据处理的速度。沪深两个交易所现在总共有将近5000只股票,把所有的日线、5分钟线和1分钟线数据都处理一遍,如果用双核CPU电脑,可能需要一个小时。处理数据所耗时间和python代码是否采用多进程多线程方法和CPU的核数都有关系。笔者处理数据使用的电脑是两颗 Intel(R) Xeon(R) CPU E5-2660 v2 @ 2.20GHz 2.20 GHz 处理器,共2*20核,全部数据处理一次只需要 124 秒。
本文提供的python程序,包括三个自定义函数:
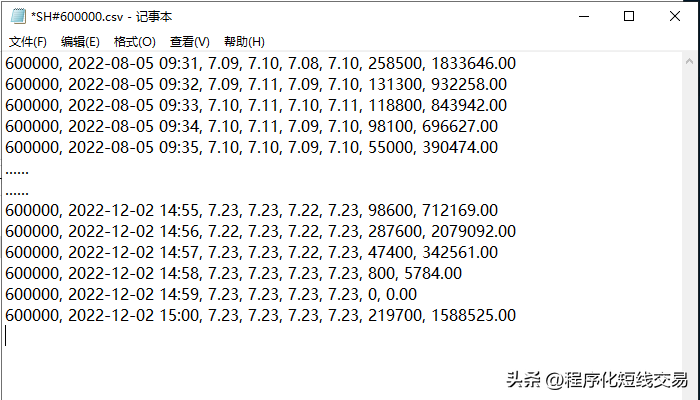
- def preprocess_historymd(path_filename_mdrows),先对下载后的历史行情数据进行预处理,删除行情数据文件的表头和末尾行。未做处理前的行情数据为csv格式,如下图:


- def multiprocess_filteringquotes(quote_watchingsymbol_list),构建多进程池
- def filtering_quotes(onequote_watchingsymbollist), 处理单个的行情数据文件
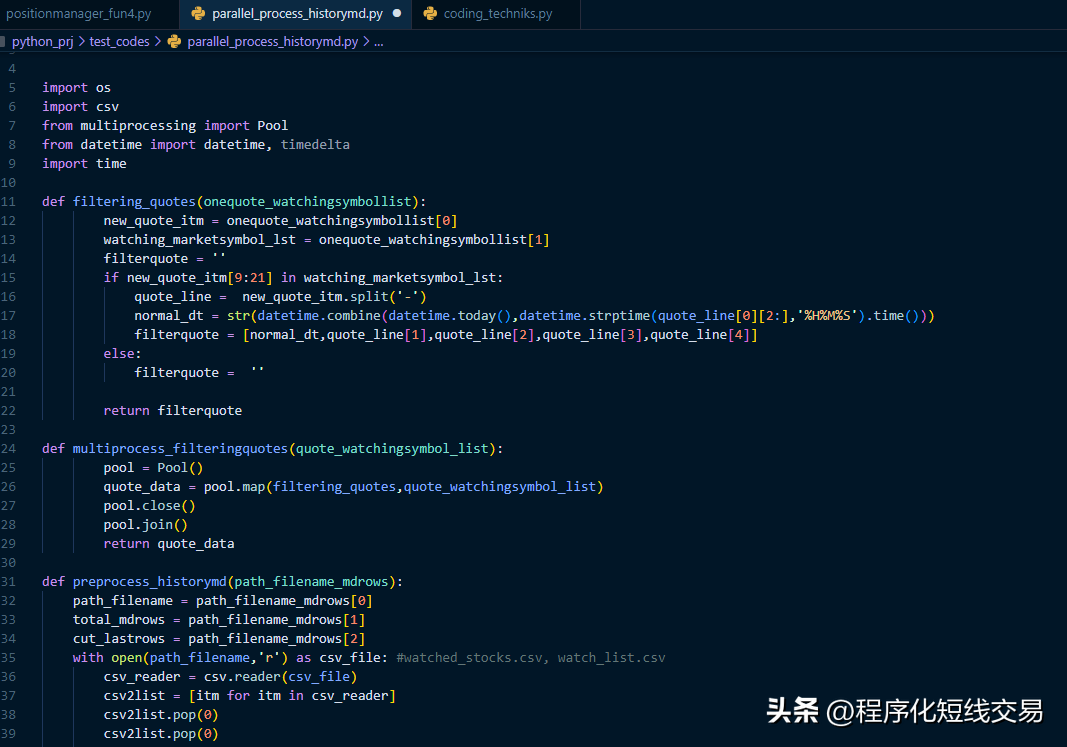
完整代码如下:
'''
按指定行数截取行情数据
'''
import os
import csv
from multiprocessing import Pool
from datetime import datetime, timedelta
import time
def filtering_quotes(onequote_watchingsymbollist):
new_quote_itm = onequote_watchingsymbollist[0]
watching_marketsymbol_lst = onequote_watchingsymbollist[1]
filterquote = ''
if new_quote_itm[9:21] in watching_marketsymbol_lst:
quote_line = new_quote_itm.split('-')
normal_dt = str(datetime.combine(datetime.today(),datetime.strptime(quote_line[0][2:],'%H%M%S').time()))
filterquote = [normal_dt,quote_line[1],quote_line[2],quote_line[3],quote_line[4]]
else:
filterquote = ''
return filterquote
def multiprocess_filteringquotes(quote_watchingsymbol_list):
pool = Pool()
quote_data = pool.map(filtering_quotes,quote_watchingsymbol_list)
pool.close()
pool.join()
return quote_data
def preprocess_historymd(path_filename_mdrows):
path_filename = path_filename_mdrows[0]
total_mdrows = path_filename_mdrows[1]
cut_lastrows = path_filename_mdrows[2]
with open(path_filename,'r') as csv_file: #watched_stocks.csv, watch_list.csv
csv_reader = csv.reader(csv_file)
csv2list = [itm for itm in csv_reader]
csv2list.pop(0)
csv2list.pop(0)
csv2list.pop(-1)
if total_mdrows < len(csv2list):
csv2list_cut = csv2list[len(csv2list)-(total_mdrows+abs(cut_lastrows)):(len(csv2list)+cut_lastrows)]
else:
csv2list_cut = csv2list[0:(len(csv2list)+cut_lastrows)]
csv2list_new = []
for itm in csv2list_cut:
if len(itm) == 7:
csv2list_new.append([path_filename[-10:-4], itm[0].replace('/','-'),itm[1],itm[2],itm[3],itm[4],itm[5],itm[6]])
if len(itm) == 8:
csv2list_new.append([path_filename[-10:-4], itm[0].replace('/','-')+" "+itm[1][0:2]+":"+itm[1][2:4], itm[2],itm[3],itm[4],itm[5],itm[6],itm[7]])
# with open(path_filename,'w') as f: #仅用于测试观察数据
# for i in range(0,len(csv2list_new)):
# x = str(csv2list_new[i]).replace("'","").replace("[","").replace("]","")+'\n'
# # x = csv2list_new[i]
# f.write(x)
print(f"行情文件 {path_filename} 处理完成, 共 { len(csv2list_new)} 行:")
def multiprocess_historymd(historymd_filename_list):
pool = Pool()
historymd_data = pool.map(preprocess_historymd,historymd_filename_list)
pool.close()
pool.join()
return historymd_data
if __name__ == "__main__":
T_start = time.perf_counter()
given_dailymd_path = 'D:\\SecurityData\\MD_daily'
given_min1md_path = 'D:\\SecurityData\\MD_1min'
# given_dailymd_path = 'D:\\SecurityData\\test_dailyMD'
# given_min1md_path = 'D:\\SecurityData\\test_min1MD'
# 选取指定时间段的历史行情,如倒数3个交易日之前的1000个交易日,
# 选取指定时间段的1分钟历史行情,如倒数3个交易日之前的80个交易日,注意倒数几个交易日必须与日线相同
total_days = 1000 #选取 80 个交易日的1分钟数据
total_mindays = 80
#如果截止到当前最后一个交易日,则倒数0个交易日; 如果截止到倒数第3个交易日的数据,downcount_days = -3
downcounter_days = 0
''' 处理通达信历史行情数据文件 - 日线行情 '''
dailyfilename_list = os.listdir(given_dailymd_path)
daily_filename = str(dailyfilename_list)
dailyfilename_split = daily_filename.split(',')
dailymdfiles_list = [given_dailymd_path +'\\' + itm[2:15] for itm in dailyfilename_split]
dailymdrows_total = [total_days]*len(dailymdfiles_list)
if downcounter_days < 0: # 截止到倒数0个交易日的日线
dailymdrows_end = [downcounter_days]*len(dailymdfiles_list)
if downcounter_days == 0: # 截止到最后一个交易日,不用倒数
dailymdrows_end = [0]*len(dailymdfiles_list)
daily_result = multiprocess_historymd(zip(dailymdfiles_list,dailymdrows_total,dailymdrows_end))
''' 处理通达信历史行情数据文件 - 1分钟行情 '''
min1filename_list = os.listdir(given_min1md_path)
min1_filename = str(min1filename_list)
min1filename_split = min1_filename.split(',')
min1mdfiles_list = [given_min1md_path +'\\' + itm[2:15] for itm in min1filename_split]
min1mdrows_total = [240*total_mindays]*len(min1mdfiles_list)
if downcounter_days < 0: # 截止到倒数3个交易日的1分钟线
min1mdrows_end = [downcounter_days*240]*len(min1mdfiles_list)
if downcounter_days == 0: # 截止到最后一个交易日,不用倒数
min1mdrows_end = [0]*len(min1mdfiles_list)
min1_result = multiprocess_historymd(zip(min1mdfiles_list,min1mdrows_total,min1mdrows_end))
T1_end = time.perf_counter()
print(f'\n耗时 {round(T1_end-T_start,2)} 秒\n')
处理后的历史行情数据格式如下图所示:
注意:获取几年的日线数据或分钟数据,与所在电脑上安装和使用通达信客户端程序的时间长短有关,初次安装后,默认可下载3年的日线数据,4个月的1分钟数据。数据导出时可选择下载不复权、前复权或后复权数据。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/76231
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!