
前几天看到一个视频,大意是对比我国和某国最赚钱的前三家公司,我国都是银行最赚钱,某国却是高科技企业最赚钱,视频主由此希望引起观众的一些思考。
对于一个对股市感兴趣的人,我,想到的是:谁是最赚钱的上市公司呢?能否用代码来验证一下?
如果要写代码,我们需要做些什么呢?
1、先要下载财务数据。
2、用代码获取财务数据,提取上市公司的净利润。
3、根据净利润从大到小的顺序对深沪上市公司进行排序,打印出排名前十的上市公司。
一、下载财务数据
1.启动QMT,在主界面点“操作”,再点“数据管理”。
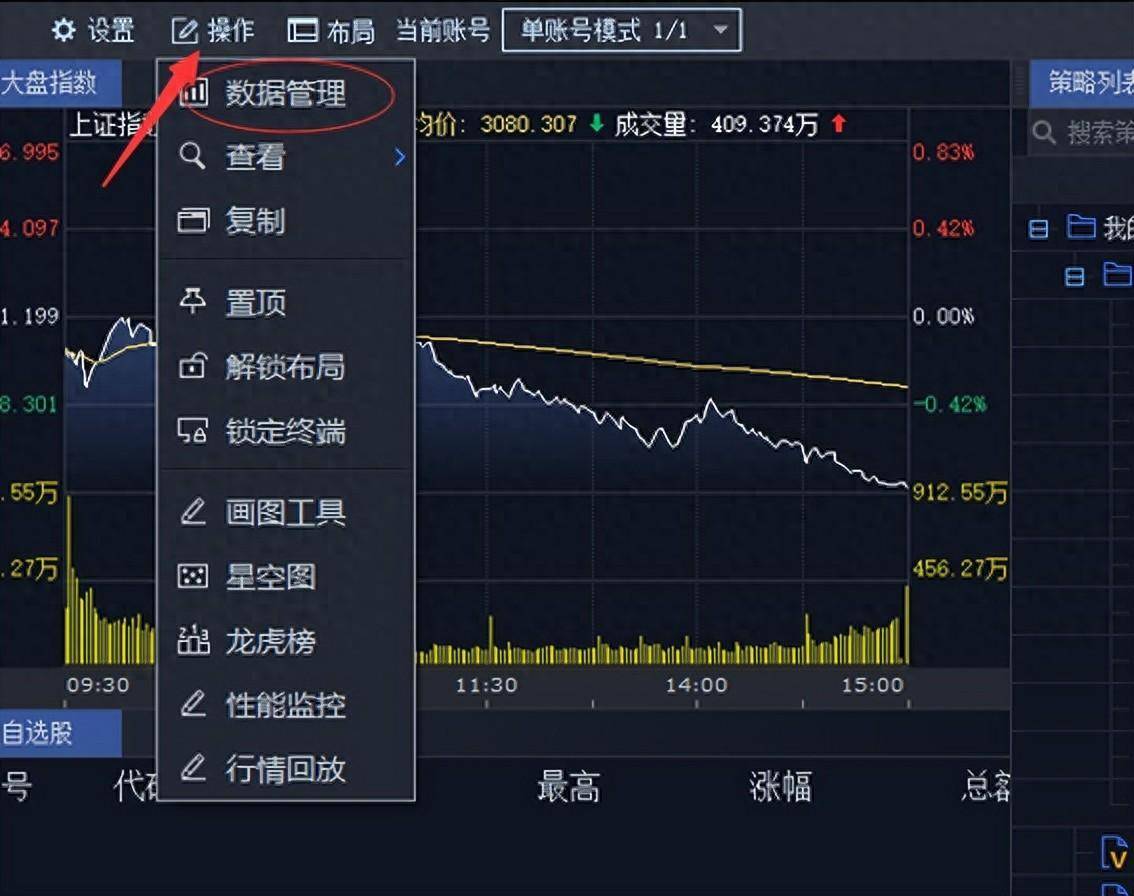

2.在打开的数据管理面板中,找到“数据选项”,选择“财务数据”
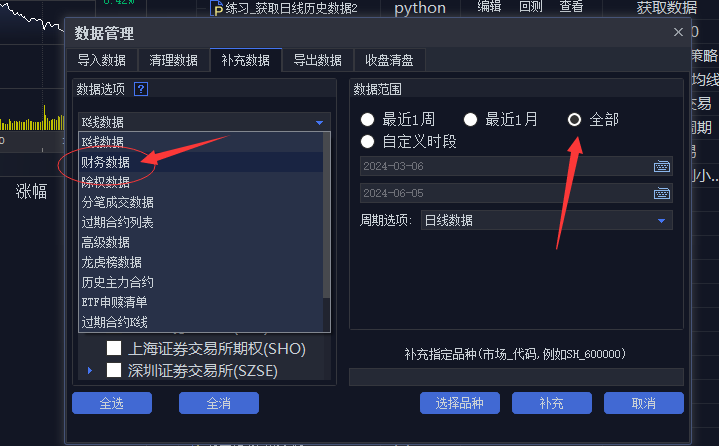
3.在财务数据中勾选“上海证券交易所”和“深圳证券交易所”,在数据范围中可选“全部”。也可以自定义时段,例如“2023-01-01”到“2024-4-30”。
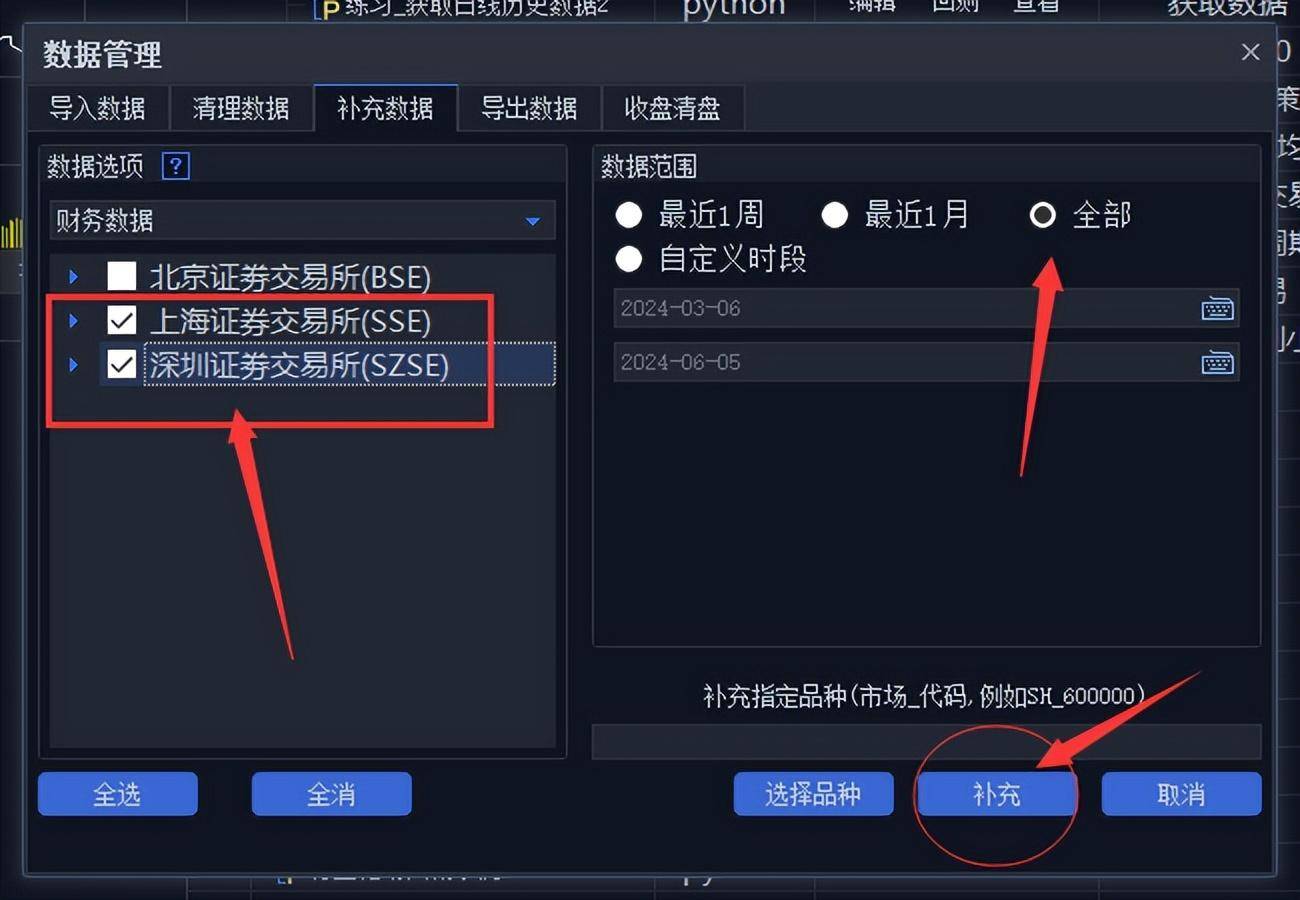
下载数据需要些时间,耐心等等吧。完成数据下载后,我们就可以编写代码了。
二、编写代码
1、导入需要库,pandas 和numpy。
2、定义init()函数,设置需要查询的财务字段、股票列表。
def init(C):
# 初始化操作,例如设置需要查询的财务字段、股票列表等
C.profit_field = 'ASHAREINCOME.net_profit_excl_min_int_inc' # 净利润字段
C.stock_sector = '沪深A股' # 股票板块,例如沪深A股
C.profit_data = [] # 初始化存储财务数据3、编写def handlebar()函数,实现获取财务数据,并根据净利润进行排序和输出结果。
1)跳过历史K线。
if not C.is_last_bar():
return因为在handlebar()函数中,每一根K线,程序都会运行一次,而我们仅仅只需要此程序运行一次,故把所有的历史K线都过滤掉,只留最后的那根K线就行了。
2)创建一个空的DataFrame,稍后用来为存放股票代码、股票名称和净利润这些数据。
df = pd.DataFrame(columns=['股票代码','股票名称','净利润'])3)获取所有的股票代码,稍后我们要按股票代码来获取财务数据。
stock_list = C.get_stock_list_in_sector(C.stock_sector)4)获取财务数据。
# 遍历股票列表,获取每只股票的财务数据
for stock in stock_list:
# 获取指定股票的财务数据
financial_data = C.get_raw_financial_data(
fieldList=C.financial_fields,
stockList=[stock],
startDate='20230101',
endDate='20240430',
report_type = 'announce_time'
)5)在实际获取财务数据的过程中,发现有些股票的历史财务数据是空的,也许它是新股,去年没有发布财务报告,也许是数据源的数据不全。所以我们还要加上一个判断,如果净利润为空,则跳过这支股票。
# 检查财务数据是否获取成功
if financial_data and stock in financial_data:
# 获取净利润数据
net_profit = financial_data[stock][C.profit_field]
if net_profit:
max_time_stamp =max(net_profit.keys()) #字典的健,最大的时间戳
last_profit = net_profit[max_time_stamp] #用健来取值 净利润
else:
print(f"股票 {stock} 的净利润数据为空,跳过该股票。")6)把获取到的数据,股票代码、股票名称和净利润添加到之前我们创建的df中。
df.loc[len(df)] = [stock,stock_info,last_profit]7)按净利润从大到小进行排序。
df_sorted = df.sort_values(by = "净利润",ascending=False) 参数ascending=True 是升序排到,即从小到大排序,ascending=False是降序排列,即从大到小排列。
8)打印最后的排序结果。有两种方式,简单点就是 print(df_sorted.head(10)) 这一句就够了,也可以多写几行,凑凑字数,或许打印的结果更好看一些。
print("2023年净利润排名前十的上市公司:")
i=1
for index, row in df_sorted.head(10).iterrows():
print(f"排名 {i}: 股票代码 {row['股票代码']},股票名称 {row['股票名称']},净利润 {row['净利润']}")
i=i+1三,打印结果
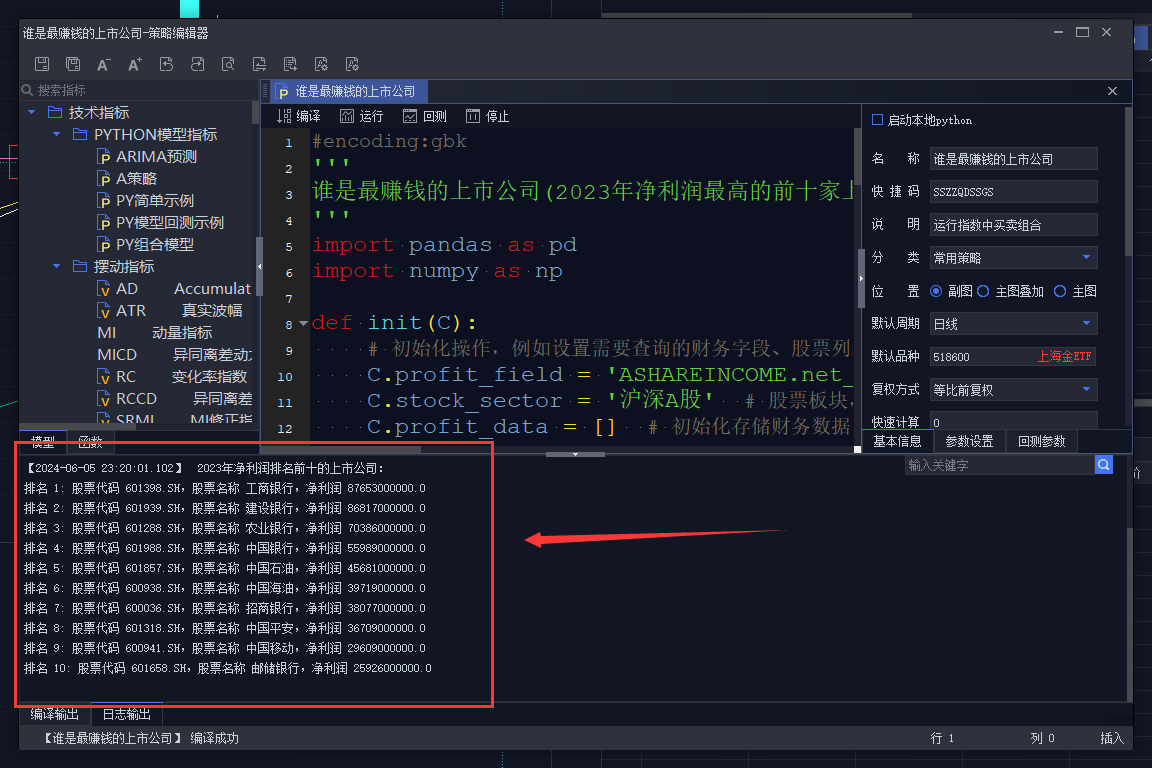
想看看谁是去年最赚钱的上市公司吗?如下图所示。(目前只有去年的年报,今年还没过完,今年谁赚钱,谁知道呢!)
四、完整代码
#encoding:gbk
'''
谁是最赚钱的上市公司(2023年净利润最高的前十家上市公司)
'''
import pandas as pd
import numpy as np
def init(C):
# 初始化操作,例如设置需要查询的财务字段、股票列表等
C.profit_field = 'ASHAREINCOME.net_profit_excl_min_int_inc' # 净利润字段
C.stock_sector = '沪深A股' # 股票板块,例如沪深A股
C.profit_data = [] # 初始化存储财务数据
def handlebar(C):
# 跳过历史k线
if not C.is_last_bar():
return
df = pd.DataFrame(columns=['股票代码','股票名称','净利润'])
# 定义获取财务数据的字段列表
C.financial_fields = [C.profit_field]
# 获取股票列表
stock_list = C.get_stock_list_in_sector(C.stock_sector)
# 遍历股票列表,获取每只股票的财务数据
for stock in stock_list:
# 获取指定股票的财务数据
financial_data = C.get_raw_financial_data(
fieldList=C.financial_fields,
stockList=[stock],
startDate='20230101',
endDate='20240430',
report_type = 'announce_time'
)
# 检查财务数据是否获取成功
if financial_data and stock in financial_data:
# 获取净利润数据
net_profit = financial_data[stock][C.profit_field]
if net_profit:
max_time_stamp =max(net_profit.keys()) #字典的健,最大的时间戳
last_profit = net_profit[max_time_stamp] #用健来取值 净利润
else:
print(f"股票 {stock} 的净利润数据为空,跳过该股票。")
stock_info_dic = C.get_instrumentdetail(stock)
stock_info = stock_info_dic['InstrumentName']
df.loc[len(df)] = [stock,stock_info,last_profit]
else:
print(f"股票 {stock} 的财务数据未能成功获取,跳过该股票。")
df_sorted = df.sort_values(by = "净利润",ascending=False) # 按净利润从大到小排序
# print(df_sorted.head(10))
print("2023年净利润排名前十的上市公司:")
i=1
for index, row in df_sorted.head(10).iterrows():
print(f"排名 {i}: 股票代码 {row['股票代码']},股票名称 {row['股票名称']},净利润 {row['净利润']}")
i=i+1五、总结
今天我们学会了如何去获取财务数据,并对数据进行排序。对财务数据进行获取和分析,对于喜欢进行价值投资的人是有益的。
六、思考
如果我们想知道去年哪十家公司亏钱最多该怎么办呢?聪明的你,把答案留在评论区吧。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/73458
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!