
Pandas基础:Series 和 DataFrame
上节我们介绍了Python的变量、条件、循环、函数,这节我们介绍Pandas库的Series和DataFrame这两种数据类型。
Pandas 是 Python 中广泛应用于数据处理和分析的库,它提供了强大而灵活的工具。在 Pandas 中,数据通常以 Series (系列)或 DataFrame (数据框)的形式存在。本文对Series和DataFrame的基础操作进行介绍。
01
Series简介
- 什么是 Series
Series 是 Pandas 中的一种基本数据结构,它是一个一维的带标签的数组。Series 可以存储任何数据类型,包括整数、浮点数、字符串、Python 对象等。它由数据和索引两部分组成。 - 如何创建 Series
创建 Series 的基本方法是调用 pandas.Series() 函数。你可以将列表、字典、元组或其他一维数据传递给这个函数。例如:
import pandas as pd
#使用列表创建 Series
s = pd.Series([1, 2, 3])
print(s)
这里,我们创建了一个包含 1 到 3 的整数的 Series。注意,Pandas 为我们自动创建了索引,从 0 开始。输出结果如下:
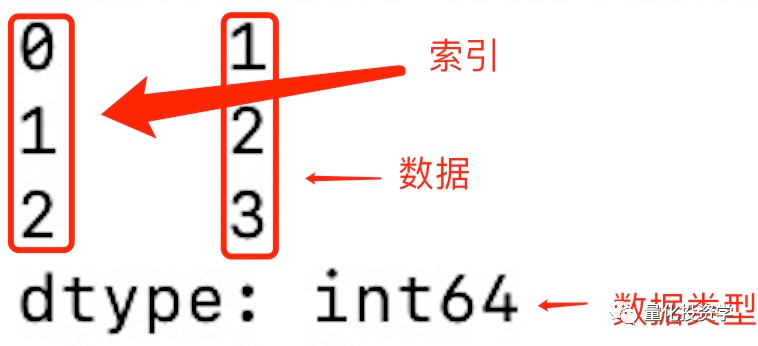

(注:上图来自“菜鸟教程 runoob.com”)
- 访问 Series 中的元素
你可以使用索引来访问 Series 中的元素,就像访问 Python 列表中的元素一样:
print(s[2]) # 输出:3
Series大部份的使用方法跟DataFrame相同,可以参照下文中DataFrame的介绍。
02
DataFrame简介
- 什么是 DataFrame
在Pandas中,DataFrame 是最常用的数据结构,适合处理各种类型的数据。DataFrame 是二维数据结构,可以看作是一个表格,包含行索引和列索引。DataFrame 可以存储各种类型的数据,如数字、字符串、Python 对象等。
DataFrame 既有行索引也有列索引,DataFrame 的每一列可以被看一个 Series (共同用一个索引):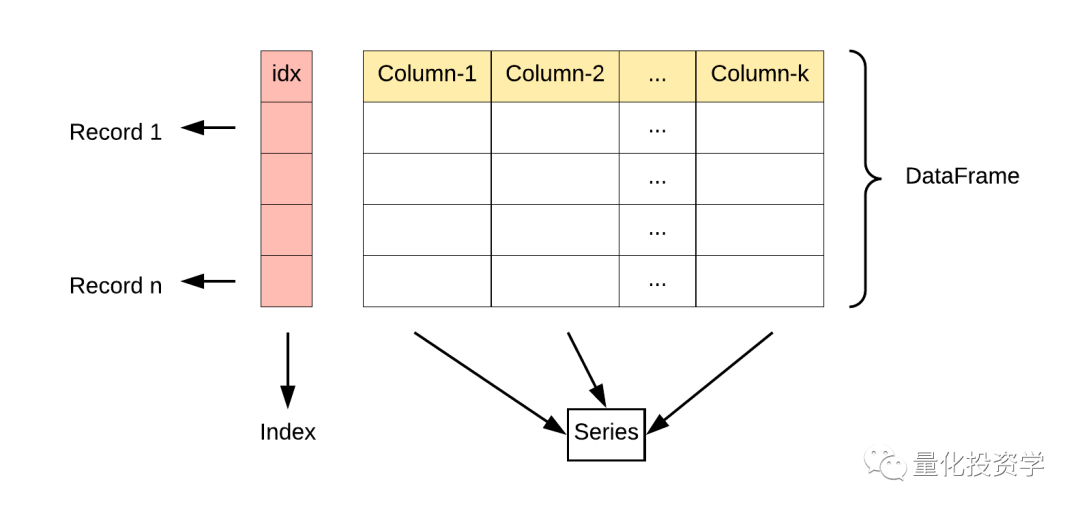
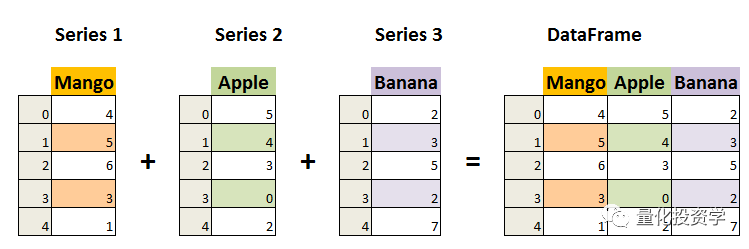
(注:上图来自“菜鸟教程 runoob.com”) - 创建 Pandas DataFrame
在 Pandas 中,有多种方法可以创建 DataFrame,以下是一些常见的创建 DataFrame 的方法:
1)从字典创建 DataFrame
最常见的方法是使用字典创建 DataFrame。在这种情况下,字典的键将成为列名,字典的值将成为相应列的值。例如:
import pandas as pd
data = {
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’],
‘age’: [25, 30, 35],
‘city’: [‘New York’, ‘Los Angeles’, ‘London’]
}
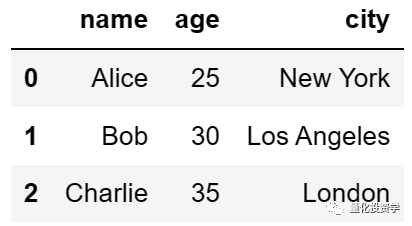
df = pd.DataFrame(data)
print(df)
输出:
(2)从列表创建 DataFrame
你也可以使用列表创建 DataFrame。在这种情况下,每个列表将成为 DataFrame 中的一行。例如:
data = [
[‘Alice’, 25, ‘New York’],
[‘Bob’, 30, ‘Los Angeles’],
[‘Charlie’, 35, ‘London’]
]
df = pd.DataFrame(data, columns=[‘name’, ‘age’, ‘city’])
print(df)
输出将与上一个示例相同。
(3)从其他 DataFrame 创建 DataFrame
你还可以使用一个 DataFrame 来创建一个新的 DataFrame。这在你希望创建一个现有 DataFrame 的子集时非常有用。例如:
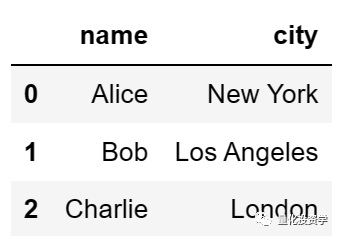
df2 = df[[‘name’, ‘city’]] # 创建一个只包含 ‘name’ 和 ‘city’ 列的新 DataFrame
print(df2)
输出:
以上就是创建 DataFrame 的一些常见方法。根据你的需求,可能还有其他方法,例如从 CSV 文件、数据库或外部 API 创建 DataFrame。不论你选择哪种方法,关键是理解 DataFrame 的结构,以便你可以有效地处理你的数据。
- DataFrame 索引和数据访问
在 Pandas 的 DataFrame 中,索引是用于定位和引用数据的关键。每个 DataFrame 都有一个行索引和一个列索引。下面是如何通过索引访问数据的一些方法。
(1)列索引
通过 DataFrame 的列名(即列索引)可以直接访问整列数据。例如:
import pandas as pd
data = {
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’],
‘age’: [25, 30, 35],
‘city’: [‘New York’, ‘Los Angeles’, ‘London’]
}
df = pd.DataFrame(data)
print(df[‘name’])
这将输出 ‘name’ 列的所有值,输出结果为一个Series:
0 Alice
1 Bob
2 Charlie
Name: name, dtype: object
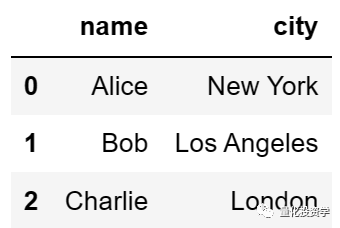
如果你想要访问多列,可以传递一个列名列表,注意,此时的输出结果为一个DataFrame:
print(df[[‘name’, ‘city’]])
输出结果如下:
(2)行索引
默认情况下,DataFrame 的行索引是从 0 开始的整数,但你也可以自定义行索引。
(3)通过索引访问数据
访问行数据的主要方法是使用 .loc 和 .iloc 属性。.loc 是基于标签的数据选择方法,它意味着我们要传入的是行或列的名字。而 .iloc 则是基于行数和列数的索引方法,其参数必须是行或列的位置。
例如,要访问索引为 1 的行,你可以这样做:
print(df.loc[1]) # 使用标签索引,这里的1为行名
print(df.iloc[1]) # 使用位置索引,这里的1为行的索引
切片:
你还可以使用切片操作来访问一系列的行:
print(df[1:3]) # 获取索引为 1 和 2 的行
注意,这种方式得到的是闭开区间,即包含起始索引,不包含结束索引。
(4)布尔索引
此外,你还可以使用布尔索引来根据条件选择数据。例如,下面的代码将选择年龄大于 25 的所有人:
print(df[df[‘age’] > 25])
以上就是 DataFrame 索引和数据访问的基本概念和方法。理解和熟练应用这些方法,将有助于你高效地处理和分析数据。
- DataFrame 的增删行列操作
在 Pandas DataFrame 中,我们经常需要添加或删除行和列,以下是一些常用的方法。
(1)增加列
在 DataFrame 中,增加新的列非常简单。你只需要定义一个新的列名,并为它赋值。例如,假设我们有以下DataFrame:
import pandas as pd
data = {
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’],
‘age’: [25, 30, 35],
}
df = pd.DataFrame(data)
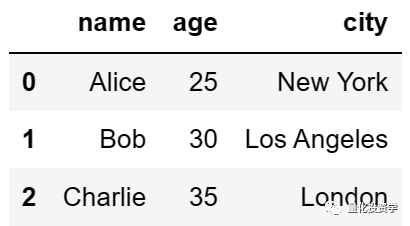
我们想要增加一个 ‘city’ 列,只需这样做:
df[‘city’] = [‘New York’, ‘Los Angeles’, ‘London’]
现在,DataFrame 包含了 ‘city’ 列:
(2)删除列
删除 DataFrame 中的列可以使用 drop 方法,并设置 axis=1(表示列)。例如,要删除刚刚添加的 ‘city’ 列,你可以这样做:
df.drop(‘city’, axis=1, inplace=True)
inplace=True表示在原DataFrame上进行修改。如果不设置inplace=True,drop方法会返回一个新的DataFrame,原 DataFrame 不会改变。
(3)增加行
增加行可以使用 append 方法。假设我们有一个新的人员数据,我们可以创建一个新的 DataFrame,并将其添加到原 DataFrame:
new_person = pd.DataFrame({
‘name’: [‘David’],
‘age’: [40]
})
df = df.append(new_person, ignore_index=True)
ignore_index=True 会重置索引。如果你想保留原索引,可以不设置 ignore_index。
(4)删除行
和删除列类似,删除行可以使用 drop 方法,并设置 axis=0(表示行)。例如,要删除索引为 0 的行,你可以这样做:
df.drop(0, axis=0, inplace=True)
以上就是 DataFrame 增删行列的基本操作,通过这些操作,你可以灵活地处理你的数据。
- DataFrame 的转置
在 Pandas DataFrame 中,”转置”操作可以将行和列进行交换,这与线性代数中矩阵的转置操作是一样的。DataFrame 的转置非常简单,只需使用 T 属性即可。
例如,假设我们有以下 DataFrame:
import pandas as pd
data = {
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’],
‘age’: [25, 30, 35],
‘city’: [‘New York’, ‘Los Angeles’, ‘London’]
}
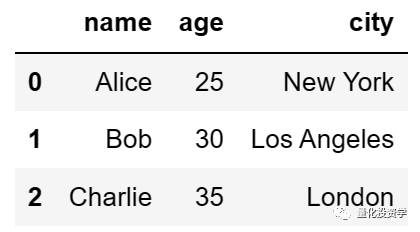
df = pd.DataFrame(data)
print(df)
这将输出:
然后,我们可以使用 T 属性来转置这个 DataFrame:
df_transposed = df.T
print(df_transposed)
输出:
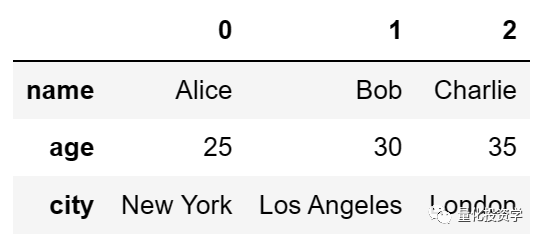
你可以看到,原来的行标签(0, 1, 2)现在变成了列标签,原来的列标签(’name’, ‘age’, ‘city’)现在变成了行标签,而且数据也进行了相应的交换。
需要注意的是,转置操作不会改变原 DataFrame,而是返回一个新的 DataFrame。如果你想在原 DataFrame 上进行转置,可以这样做:
df = df.T
以上就是 DataFrame 转置的基本操作。在某些场景下,例如数据预处理或可视化时,转置操作可能会非常有用。
- DataFrame 的排序
在 Pandas DataFrame 中,我们可以根据不同的列或行进行排序。这是通过使用 sort_values() 和 sort_index() 方法实现的。
(1)sort_values()
sort_values() 方法用于根据一列或多列的值对 DataFrame 进行排序。例如,假设我们有以下 DataFrame:
import pandas as pd
data = {
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’],
‘age’: [35, 30, 25]
}
df = pd.DataFrame(data)
我们可以按 ‘age’ 列进行排序:
df.sort_values(by=’age’, inplace=True)
print(df)
这将输出:
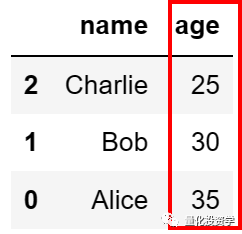
默认情况下,排序是按升序进行的。如果你想按降序排序,可以设置 ascending=False:
df.sort_values(by=’age’, inplace=True, ascending=False)
如果你想按多列排序,可以传入一个列名的列表:
df.sort_values(by=[‘age’, ‘name’], inplace=True)
(2)sort_index()
sort_index() 方法用于根据行索引排序。例如:
df.sort_index(inplace=True)
这将按行索引进行排序。同样,你可以设置 ascending=False 来进行降序排序。
以上就是 DataFrame 排序的基本操作。在数据分析中,排序是一种常用的操作,可以帮助我们更好地理解和观察数据。
- DataFrame 的排名
在 Pandas DataFrame 中,rank() 方法可以为每个元素生成排名。该方法不会改变数据的排序,而是为每个元素添加一个排名。
默认情况下,rank() 方法是按升序进行排名的,即较小的值有较低的排名(较小的排名数字)。并列的元素会有相同的排名,而下一个有效的排名则会跳过相应的数字。例如,如果有两个并列的元素排在第一位,那么下一个元素的排名将是 3 而不是 2。
例如,假设我们有以下 DataFrame:
import pandas as pd
data = {
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’],
‘age’: [35, 30, 35]
}
df = pd.DataFrame(data)
我们可以对 ‘age’ 列进行排名:
df[‘age_rank’] = df[‘age’].rank()
print(df)
这将输出:
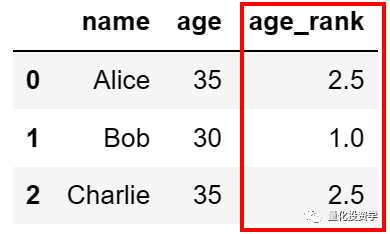
你可以看到,’Alice’ 和 ‘Charlie’ 的年龄相同,都是 35,所以他们的排名是相同的,且都是 2.5。
排名与排序的区别
排名和排序虽然在某种程度上相似,但它们有一些关键的区别:
排序会改变数据的顺序,而排名则会保持数据的原始顺序不变。
排序的结果是重新排列的数据,而排名的结果是每个元素的排名。
排序只关注元素的位置,而排名则关注元素的位置和值。在排名中,相等的值会有相同的排名。
- DataFrame 的缺失值处理
在 Pandas DataFrame 中,缺失值通常表示为 NaN。处理这些缺失值是数据预处理的重要部分,因为它们可能会对数据分析和机器学习模型的结果产生影响。
以下是一些常见的处理缺失值的方法:
(1)检测缺失值
首先,我们需要知道 DataFrame 中哪些值是缺失的。可以使用 isnull() 或 isna() 方法来检测缺失值:
import pandas as pd
import numpy as np
data = {
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’, None],
‘age’: [25, 30, np.nan, 35],
}
df = pd.DataFrame(data)
print(df.isnull())
这将返回一个同样大小的 DataFrame,其中的值为 True 或 False,表示对应的位置是否为缺失值:

(2)删除缺失值
一种处理缺失值的简单方法是直接删除含有缺失值的行或列。可以使用 dropna() 方法来实现:
df.dropna(inplace=True) # 删除所有含有缺失值的行
你也可以设置 axis=1 来删除所有含有缺失值的列:
df.dropna(axis=1, inplace=True) # 删除所有含有缺失值的列
但是请注意,这种方法可能会删除大量的数据。
(3)填充缺失值
另一种处理缺失值的方法是通过某种方式填充它们,例如使用固定值、平均值、中位数等。可以使用 fillna() 方法来实现:
df.fillna(0, inplace=True) # 使用 0 填充所有缺失值
或者使用 ‘age’ 列的平均值来填充它的缺失值:
df[‘age’].fillna(df[‘age’].mean(), inplace=True)
以上就是 DataFrame 缺失值处理的基本操作。在实际的数据分析中,你可能需要结合实际的情况和需求来选择合适的处理方式。
- 合并多个 DataFrame
在 Pandas 中,有多种方法可以合并多个 DataFrame,包括 concat(), merge(), 和 join()。下面我们介绍每种方法。
(1)使用 concat()
concat() 是最简单的合并方法,它将 DataFrame 按照某个轴进行拼接。例如:
import pandas as pd
df1 = pd.DataFrame({‘A’: [‘A0’, ‘A1’, ‘A2’],
‘B’: [‘B0’, ‘B1’, ‘B2’]},
index=[0, 1, 2])
df2 = pd.DataFrame({‘A’: [‘A3’, ‘A4’, ‘A5’],
‘B’: [‘B3’, ‘B4’, ‘B5’]},
index=[3, 4, 5])
result = pd.concat([df1, df2])
print(result)
以上代码会输出:

(2)使用 merge()
merge() 方法可以根据一列或多列的值将 DataFrame 进行合并。这和 SQL 语言中的 JOIN 操作是类似的。例如:
df1 = pd.DataFrame({‘key’: [‘A’, ‘B’, ‘C’, ‘D’],
‘value’: range(4)})
df2 = pd.DataFrame({‘key’: [‘B’, ‘D’, ‘D’, ‘E’],
‘value’: range(4, 8)})
result = pd.merge(df1, df2, on=’key’)
print(result)
以上代码会输出:
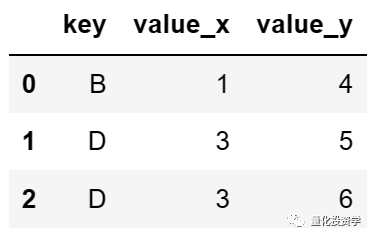
你可以看到,merge() 方法会根据 ‘key’ 列的值将 df1 和 df2 进行合并。如果某个 ‘key’ 值在一个 DataFrame 中存在,但在另一个 DataFrame 中不存在,那么这个 ‘key’ 值在结果中就不会出现。
(3)使用 join()
join() 方法可以根据索引将 DataFrame 进行合并。例如:
df1 = pd.DataFrame({‘A’: [‘A0’, ‘A1’, ‘A2’]},
index=[‘a’, ‘b’, ‘c’])
df2 = pd.DataFrame({‘B’: [‘B0’, ‘B1’, ‘B2’]},
index=[‘a’, ‘b’, ‘d’])
result = df1.join(df2, how=’outer’)
print(result)
以上代码会输出:

你可以看到,join() 方法会根据索引将 df1 和 df2 进行合并。how=’outer’ 参数表示执行外连接,即保留两个 DataFrame 中的所有索引。
以上就是在 Pandas 中合并多个 DataFrame 的基本方法。在实际的数据分析中,你可能需要结合实际的情况和需求来选择合适的合并方式。
- DataFrame 的分组聚合
在 Pandas 中,可以使用 groupby() 方法对 DataFrame 进行分组,然后对每个分组进行聚合操作,如计算平均值、最大值、最小值等。
例如:
import pandas as pd
data = {
‘city’: [‘Beijing’, ‘Shanghai’, ‘Beijing’, ‘Shanghai’, ‘Beijing’],
‘year’: [2016, 2016, 2017, 2017, 2018],
‘population’: [2100, 2300, 2150, 2400, 2200]
}
df = pd.DataFrame(data)
grouped = df.groupby(‘city’)
print(grouped[‘population’].mean())
以上代码会输出每个城市的平均人口:
city
Beijing 2150.0
Shanghai 2350.0
Name: population, dtype: float64
- 时间重采样
Pandas 提供了 resample() 方法,可以对时间序列数据进行重采样,即改变数据的频率。例如,可以将每日数据重采样为每月数据。
例如:
import pandas as pd
idx = pd.date_range(‘2023-01-25′, periods=10, freq=’D’)
series = pd.Series(range(10), index=idx)
print(series.resample(‘M’).mean())
以上代码会输出每个月的平均值:
2023-01-31 3.0
2023-02-28 8.0
Freq: M, dtype: float64
- 移动窗口计算
Pandas 提供了 rolling() 方法,可以进行移动窗口计算,即在固定大小的窗口上进行滑动并计算,如计算滑动平均值。
例如:
import pandas as pd
s = pd.Series([1, 2, 3, 4, 5])
print(s.rolling(3).mean())
以上代码会输出滑动窗口大小为 3 的滑动平均值:
0 NaN
1 NaN
2 2.0
3 3.0
4 4.0
dtype: float64
你可以看到,前两个值为 NaN,因为窗口大小为 3,所以前两个值的窗口内没有足够的值。
这篇文章介绍了Pandas的一些常用操作,这些操作在实际的数据分析和处理中非常重要,可以处理各种复杂的数据问题。但是,这些只是Pandas功能的冰山一角,Pandas作为一个强大的数据分析库,还有许多其他功能和操作,如数据转换、数据透视、绘制图表等等。如果你想更深入地了解 Pandas的功能,建议阅读Pandas的官方文档,或者查阅相关的教程和书籍。
关注后可发消息
人划线
发布者:爱吃肉的小猫,转载请注明出处:https://www.95sca.cn/archives/45365
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!