
用一个量化实例来初识Python(附程序代码)
01
导入需要的库
Python 拥有大量的库,这些库是已经打包好的可重复使用的 Python 函数或模块,直接调用这些现成的库就能完成相应的工作,而不需要从零开始写代码。使用库可以大大提高开发效率,降低开发难度。
本例需要使用 pandas 和 akshare 这两个库,首先我们要导入这两个库:
import pandas as pd
import akshare as ak
02
从AKShare获取数据
数据是量化的基础,我们先要获取相关的数据,然后才能进行分析和计算。获取数据的途径很多,这里我们使用了akshare库,akshare是一个免费的数据源,提供非常丰富的金融数据,调用akshare中的数据获取函数就能获取相应的数据。
- 获取股票池
我们先要选取一个股票池,为简化起见,这里选择上证超大盘指数(000043)的成分股作为股票池,这个股票池包含了沪市市值最大的20只股票,你当然也可以选择其他指数的成分股或者市场里的全部股票作为股票池。
用akshare的index_stock_cons函数可以获取指数的成分股信息:
stocks_df = ak.index_stock_cons(symbol=”000043″) # 参数symbol为指数代码
print(stocks_df) # 打印查看
将获取结果打印出来查看: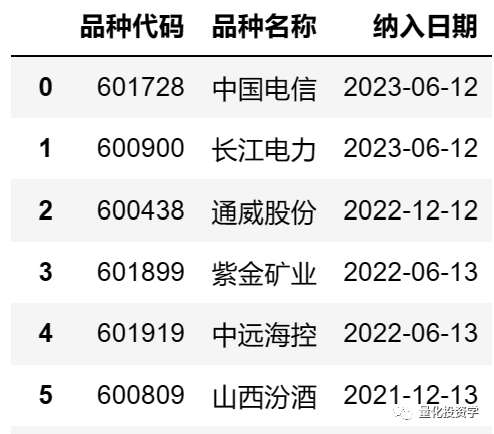

获取的数据是一个DataFrame结构,DataFrame是一个由行和列组成的二维表格,本例中表格的每一行为一只股票,表格的列为股票的信息。
在Python中有多种内建的数据结构,常用的有列表、字典、集合等,另外第三方库pandas的DataFrame和Series也是常用的数据结构,这些数据结构的基本操作需要熟练掌握。
接下来在指数成分股信息DataFrame中提取股票代码列表:
stock_list = stocks_df[‘品种代码’].tolist() # 获取股票代码列表,数据结构为列表(list) - 获取历史行情数据
我们需要获取这个股票代码列表里每只股票的行情数据,由于akshare不支持一次性获取全部股票的行情数据,我们需要一只一只股票的获取,这里就要用到一个循环,将获取数据的命令放在循环模块中,这样就不用为每只股票都写一次获取数据的命令。可以用akshare的stock_zh_a_hist函数获取历史行情数据:
data_list = [] # 用于存放每次获取的数据
for stock_code in stock_list: # for循环,逐个股票获取行情数据
df = ak.stock_zh_a_hist(symbol=stock_code, start_date=”20191201″, end_date=’20230630′, adjust=”qfq”)
df[‘股票代码’] = stock_code # 增加一列“股票代码”
data_list.append(df) # 将获取的数据存放在data_list中
对上述代码进行解释:
上述代码有2个地方用到了列表(list)的数据结构:
一个是定义了data_list这个列表,data_list用来存放每次获取的数据。列表中的元素类型是多样的,可以是数字、字符串、另一个列表、字典、集合、DataFrame、Series等等,在本例中每次获取的数据是DataFrame类型,然后把这些DataFrame作为列表元素存放在data_list中。
另一个用到列表的地方是“for stock_code in stock_list:”语句,这里用for语句和列表结合构成一个循环,意思是为stock_list中的每个stock_code执行循环操作。
ak.stock_zh_a_hist函数是akshare的历史行情获取函数,该函数有这么几个参数:
symbol为股票代码;
start_date为数据开始日期;
end_date为数据结束日期;
adjust为数据的复权类型,在本例中取”qfq”(前复权)。
获取得到的数据是DataFrame类型,如下: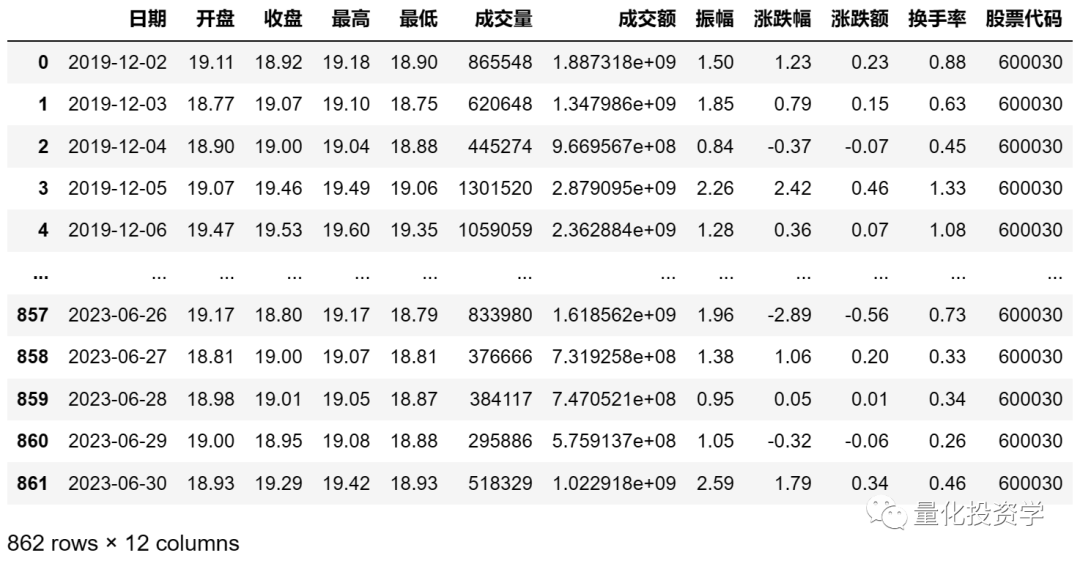
每只股票都包含多个日期的开盘、收盘、最高、最低等数据,这样的一只股票的数据称作时间序列数据,其中每个数据点都与一个时间关联。 - 合并各个股票的数据
我们使用pandas的concat函数来将多个DataFrame合并为1个DataFrame,然后对数据进行排序:
data_df = pd.concat(data_list) # 合并DataFrame
data_df = data_df.sort_values(by=[‘日期’,’股票代码’], ignore_index=True) # 按照’日期’和’股票代码’进行排序
合并后的数据如下: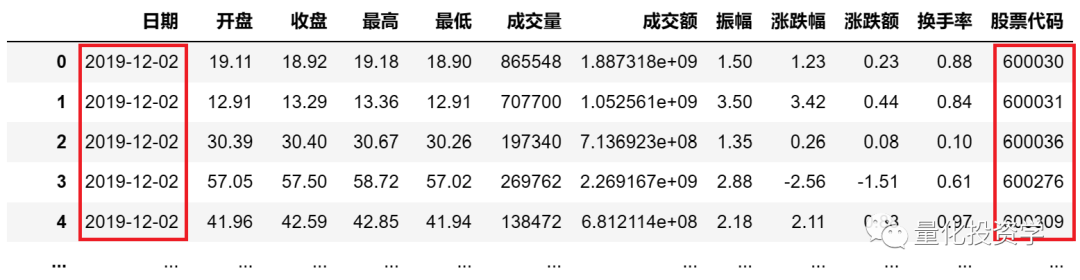
合并后的DataFrame包括多个日期的多只股票的行情数据,这种数据我们称之为面板数据。
03
用DataFrame分析计算
- 计算每只股票的日收益率
DataFrame提供了强大的数据计算和分析功能,我们可以用DataFrame的pct_change函数计算日收益率,pct_change函数可以计算DataFrame每列或每行的数据相对上一个数据的百分比变化:
data_df[‘日收益率’] = data_df.groupby(‘股票代码’)[‘收盘’].pct_change()
上述代码在data_df这个DataFrame中增加“日收益率”这一列。pct_change()函数用于计算“收盘”这列数据相对于上一个日期的百分比变化,即日收益率。
“groupby(‘股票代码’)”这个函数的作用是按“股票代码”进行分组,因为data_df是一个面板数据,包含了多个日期的多只股票的行情数据,因此要先按股票代码分组再进行计算。 - 计算每日的涨跌比
用DataFrame的功能来实现统计每日上涨股票数量和下跌股票数量,并计算日涨跌比:
date_list = set(data_df[‘日期’])
date_list = sorted(list(date_list))
count_df = pd.DataFrame(index=date_list)
count_df[‘上涨股票数量’] = data_df.loc[data_df[‘日收益率’]>0].groupby(‘日期’)[‘日收益率’].count()
count_df[‘下跌股票数量’] = data_df.loc[data_df[‘日收益率’]<0].groupby(‘日期’)[‘日收益率’].count() count_df[‘日涨跌比’] = count_df[‘上涨股票数量’] / count_df[‘下跌股票数量’] 上述代码的解释如下: (1)date_list = set(data_df[‘日期’]) 这里先从data_df这个DataFrame中取出’日期’这一整列,然后用set()函数转化为集合。因为集合内不允许有重复元素,这样可以自动滤除日期列中的重复日期。(2) date_list = sorted(list(date_list)) 接着将上一步得到的集合转化为有序列表,并用sorted()按日期顺序排序。 (3)count_df = pd.DataFrame(index=date_list) 创建一个空的DataFrame count_df,其索引为上一步得到的有序日期列表。 (4)count_df[‘上涨股票数量’] = data_df.loc[data_df[‘日收益率’]>0].groupby(‘日期’)[‘日收益率’].count()
先筛选出data_df中日收益率>0的行,然后按’日期’列进行分组,统计每组中’日收益率’列的非空值数量,即上涨的股票数量。计算结果储存在count_df的新列’上涨股票数量’中。
(5)count_df[‘下跌股票数量’] = data_df.loc[data_df[‘日收益率’]<0].groupby(‘日期’)[‘日收益率’].count()
同理,可以计算下跌股票数量。
(6)count_df[‘日涨跌比’] = count_df[‘上涨股票数量’] / count_df[‘下跌股票数量’]
最后,计算’上涨股票数量’列除以’下跌股票数量’列,得到每日的涨跌比,储存在’日涨跌比’这一列。
这样,通过对DataFrame进行分组、计数和运算,实现了每日上涨下跌股票分析。结果如下: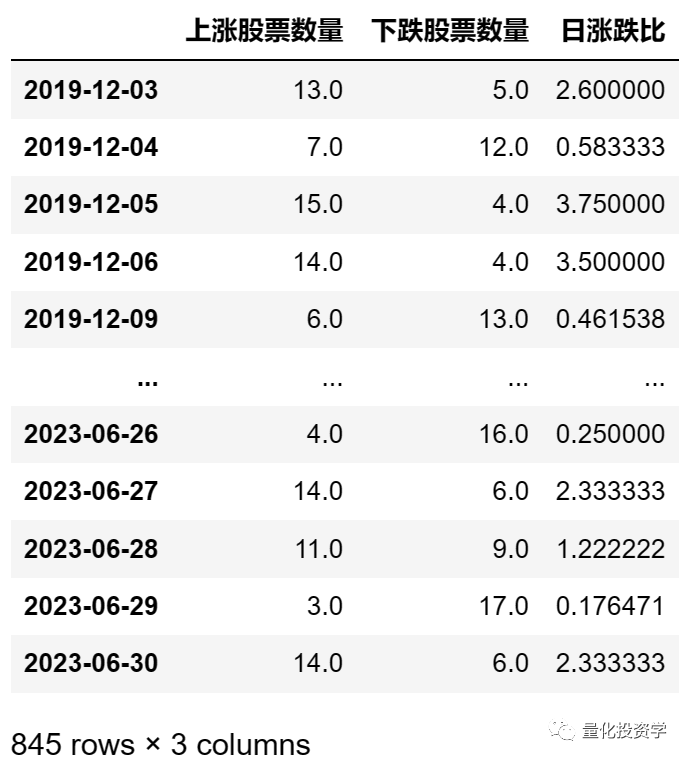
- 通过上面的代码示例,我们实现了一个简单的股票涨跌分析。虽然仅仅几行代码,却运用了Python中的关键数据分析工具pandas的许多功能,如数据过滤、分组、运算等,可见pandas的强大之处。
Python以其简洁易用、生态完善而成为量化交易的首选语言,在后续的文章中我们会接着介绍如何用Python进行量化实践,如果你对本文展示的案例感兴趣,那就让我们一起继续后面的学习。
发布者:爱吃肉的小猫,转载请注明出处:https://www.95sca.cn/archives/45256
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!