
本文利用股价日内走势和大盘走势的相关性,构建选股因子:
- 七年回测中,简单多头策略年化收益率28.3%,阿尔法14.3%,信息比率1.50
2. 因子计算
本文中因子构建的核心是股价日内走势和大盘的相关性,下面给出具体步骤:
- 取股票s在交易日t的日内分钟线股价走势曲线,和当日的中证500指数走势计算相关系数为 r(s, t),并对相关系数求绝对值;
- 对于股票s,将其过去两个月的 r(s, t) 序列进行纵向标准化,得到因子 f(s, t),标准化的目的是方便截面比对,即
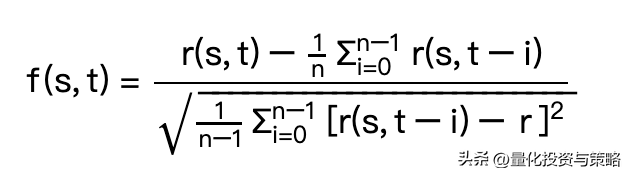

- f(s, t) 求三日平均,得到本文中的选股因子;
from datetime import datetime, timedeltaimport matplotlib.pyplot as pltfrom matplotlib import rcrc('mathtext', default='regular')import seaborn as snssns.set_style('white')from matplotlib import datesimport numpy as npimport pandas as pdimport statsmodels.api as smimport timeimport scipy.stats as stfrom CAL.PyCAL import * # CAL.PyCAL中包含font3. 因子截面特征
3.1 加载数据文件
# 提取数据factor_data = pd.read_csv('AbnormalMA_FullA.csv') # 选股因子factor_data['tradeDate'] = map(Date.toDateTime, map(DateTime.parseISO, factor_data['tradeDate']))factor_data = factor_data[factor_data.columns[:]].set_index('tradeDate')mkt_value_data = pd.read_csv('MarketValues_FullA.csv') # 市值数据mkt_value_data['tradeDate'] = map(Date.toDateTime, map(DateTime.parseISO, mkt_value_data['tradeDate']))mkt_value_data = mkt_value_data[mkt_value_data.columns[1:]].set_index('tradeDate')forward_5d_return_data = pd.read_csv('ForwardReturns_W5_FullA.csv') # 未来5天收益率 forward_5d_return_data['tradeDate'] = map(Date.toDateTime, map(DateTime.parseISO, forward_5d_return_data['tradeDate']))forward_5d_return_data = forward_5d_return_data[forward_5d_return_data.columns[1:]].set_index('tradeDate')backward_20d_return_data = pd.read_csv('BackwardReturns_W20_FullA.csv') # 过去20天收益率 backward_20d_return_data['tradeDate'] = map(Date.toDateTime, map(DateTime.parseISO, backward_20d_return_data['tradeDate']))backward_20d_return_data = backward_20d_return_data[backward_20d_return_data.columns[1:]].set_index('tradeDate')factor_data[factor_data.columns[0:5]].tail()3.2 因子截面特征
# 因子历史表现n_quantile = 10# 统计十分位数cols_mean = ['meanQ'+str(i+1) for i in range(n_quantile)]cols = cols_meancorr_means = pd.DataFrame(index=factor_data.index, columns=cols)# 计算相关系数分组平均值for dt in corr_means.index: qt_mean_results = [] # 相关系数去掉nan tmp_factor = factor_data.ix[dt].dropna() pct_quantiles = 1.0/n_quantile for i in range(n_quantile): down = tmp_factor.quantile(pct_quantiles*i) up = tmp_factor.quantile(pct_quantiles*(i+1)) mean_tmp = tmp_factor[(tmp_factor<=up) & (tmp_factor>=down)].mean() qt_mean_results.append(mean_tmp) corr_means.ix[dt] = qt_mean_results# ------------- 因子历史表现作图 ------------------------fig = plt.figure(figsize=(12, 6))ax1 = fig.add_subplot(111)lns1 = ax1.plot(corr_means.index, corr_means.meanQ1, label='Q1')lns2 = ax1.plot(corr_means.index, corr_means.meanQ5, label='Q5')lns3 = ax1.plot(corr_means.index, corr_means.meanQ10, label='Q10')lns = lns1+lns2+lns3labs = [l.get_label() for l in lns]ax1.legend(lns, labs, bbox_to_anchor=[0.5, 0.1], loc='', ncol=3, mode="", borderaxespad=0., fontsize=12)ax1.set_ylabel(u'因子', fontproperties=font, fontsize=16)ax1.set_xlabel(u'日期', fontproperties=font, fontsize=16)ax1.set_title(u"因子历史表现", fontproperties=font, fontsize=16)ax1.grid()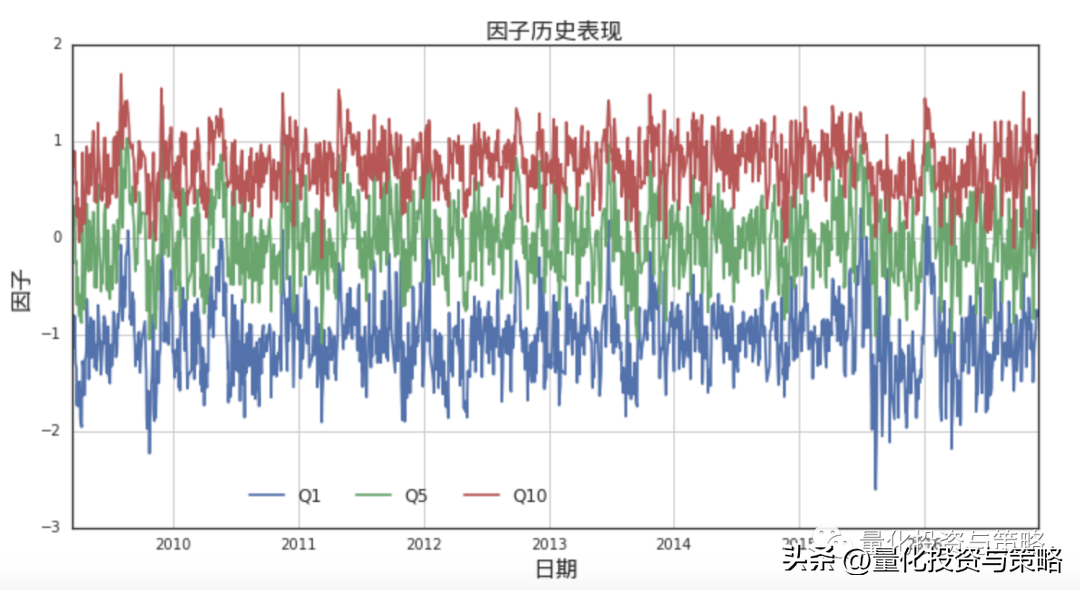
3.3 因子预测能力初探
接下来,我们计算了每一天的因子和之后5日收益的秩相关系数
# 计算了每一天的**因子**和**之后5日收益**的秩相关系数
ic_data = pd.DataFrame(index=factor_data.index, columns=['IC','pValue'])
# 计算相关系数
for dt in ic_data.index:
if dt not in forward_5d_return_data.index:
continue
tmp_factor = factor_data.ix[dt]
tmp_ret = forward_5d_return_data.ix[dt]
fct = pd.DataFrame(tmp_factor)
ret = pd.DataFrame(tmp_ret)
fct.columns = ['fct']
ret.columns = ['ret']
fct['ret'] = ret['ret']
fct = fct[~np.isnan(fct['fct'])][~np.isnan(fct['ret'])]
if len(fct) < 5:
continue
ic, p_value = st.spearmanr(fct['fct'],fct['ret']) # 计算秩相关系数 RankIC
ic_data['IC'][dt] = ic
ic_data['pValue'][dt] = p_value
ic_data.dropna(inplace=True)
print 'mean of IC: ', ic_data['IC'].mean(), ';',
print 'median of IC: ', ic_data['IC'].median()
print 'the number of IC(all, plus, minus): ', (len(ic_data), len(ic_data[ic_data.IC>0]), len(ic_data[ic_data.IC<0]))
# 每一天的**因子**和**之后5日收益**的秩相关系数作图
fig = plt.figure(figsize=(16, 6))
ax1 = fig.add_subplot(111)
lns1 = ax1.plot(ic_data[ic_data>0].index, ic_data[ic_data>0].IC, '.r', label='IC(plus)')
lns2 = ax1.plot(ic_data[ic_data<0].index, ic_data[ic_data<0].IC, '.b', label='IC(minus)')
lns3 = ax1.plot(pd.rolling_mean(ic_data.IC, window=21), 'green', label='IC(month mean)')
lns = lns1+lns2+lns3
labs = [l.get_label() for l in lns]
ax1.legend(lns, labs, bbox_to_anchor=[0.6, 0.1], loc='', ncol=3, mode="", borderaxespad=0., fontsize=12)
ax1.set_ylabel(u'相关系数', fontproperties=font, fontsize=16)
ax1.set_xlabel(u'日期', fontproperties=font, fontsize=16)
ax1.set_title(u"因子和之后5日收益的秩相关系数", fontproperties=font, fontsize=16)
ax1.set_ylim(-0.35, 0.35)
ax1.grid()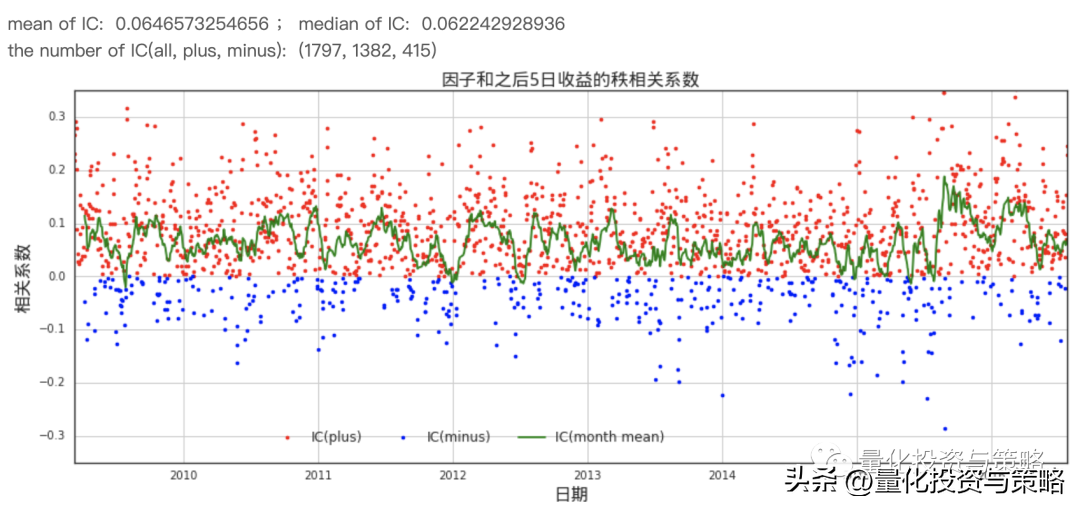
从上面计算结果可知,该因子和之后5日收益的秩相关系数在大部分时间为正,因子对之后5日收益有预测性
4. 历史回测概述
本节使用2009年以来的数据对于该选股因子进行回测,进一步简单涉及几个风险因子暴露情况
4.1 该因子选股的分组超额收益(月度)
n_quantile = 10
# 统计十分位数
cols_mean = [i+1 for i in range(n_quantile)]
cols = cols_mean
excess_returns_means = pd.DataFrame(index=factor_data.index, columns=cols)
# 计算因子分组的超额收益平均值
for dt in excess_returns_means.index:
if dt not in forward_5d_return_data.index:
continue
qt_mean_results = []
tmp_factor = factor_data.ix[dt].dropna()
tmp_return = forward_5d_return_data.ix[dt].dropna()
tmp_return = tmp_return[tmp_return<4.0]
tmp_return_mean = tmp_return.mean()
pct_quantiles = 1.0/n_quantile
for i in range(n_quantile):
down = tmp_factor.quantile(pct_quantiles*i)
up = tmp_factor.quantile(pct_quantiles*(i+1))
i_quantile_index = tmp_factor[(tmp_factor<=up) & (tmp_factor>=down)].index
mean_tmp = tmp_return[i_quantile_index].mean() - tmp_return_mean
qt_mean_results.append(mean_tmp)
excess_returns_means.ix[dt] = qt_mean_results
excess_returns_means.dropna(inplace=True)
# 因子分组的超额收益作图
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(111)
excess_returns_means_dist = excess_returns_means.mean()
excess_dist_plus = excess_returns_means_dist[excess_returns_means_dist>0]
excess_dist_minus = excess_returns_means_dist[excess_returns_means_dist<0]
lns2 = ax1.bar(excess_dist_plus.index, excess_dist_plus.values, align='center', color='r', width=0.35)
lns3 = ax1.bar(excess_dist_minus.index, excess_dist_minus.values, align='center', color='g', width=0.35)
ax1.set_xlim(left=0.5, right=len(excess_returns_means_dist)+0.5)
# ax1.set_ylim(-0.008, 0.008)
ax1.set_ylabel(u'超额收益', fontproperties=font, fontsize=16)
ax1.set_xlabel(u'十分位分组', fontproperties=font, fontsize=16)
ax1.set_xticks(excess_returns_means_dist.index)
ax1.set_xticklabels([int(x) for x in ax1.get_xticks()], fontproperties=font, fontsize=14)
ax1.set_yticklabels([str(x*100)+'0%' for x in ax1.get_yticks()], fontproperties=font, fontsize=14)
ax1.set_title(u"因子选股分组超额收益", fontproperties=font, fontsize=16)
ax1.grid()可以看到,该因子选股不同分位数组合的超额收益呈很好的单调性;因子空头收益更显著
4.2 因子选股的市值分布特征
检查因子的小市值暴露情况。因为很多策略因为小市值暴露在A股市场表现优异。
# 计算因子分组的市值分位数平均值
def quantile_mkt_values(signal_df, mkt_df):
n_quantile = 10
# 统计十分位数
cols_mean = [i+1 for i in range(n_quantile)]
cols = cols_mean
mkt_value_means = pd.DataFrame(index=signal_df.index, columns=cols)
# 计算相关系数分组的市值分位数平均值
for dt in mkt_value_means.index:
if dt not in mkt_df.index:
continue
qt_mean_results = []
# 相关系数去掉nan和绝对值大于0.97的
tmp_factor = signal_df.ix[dt].dropna()
tmp_mkt_value = mkt_df.ix[dt].dropna()
tmp_mkt_value = tmp_mkt_value.rank()/len(tmp_mkt_value)
pct_quantiles = 1.0/n_quantile
for i in range(n_quantile):
down = tmp_factor.quantile(pct_quantiles*i)
up = tmp_factor.quantile(pct_quantiles*(i+1))
i_quantile_index = tmp_factor[(tmp_factor<=up) & (tmp_factor>=down)].index
mean_tmp = tmp_mkt_value[i_quantile_index].mean()
qt_mean_results.append(mean_tmp)
mkt_value_means.ix[dt] = qt_mean_results
mkt_value_means.dropna(inplace=True)
return mkt_value_means.mean()
# 计算因子分组的市值分位数平均值
origin_mkt_means = quantile_mkt_values(factor_data, mkt_value_data)
# 因子分组的市值分位数平均值作图
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(111)
width = 0.3
lns1 = ax1.bar(origin_mkt_means.index, origin_mkt_means.values, align='center', width=width)
ax1.set_ylim(0.3,0.6)
ax1.set_xlim(left=0.5, right=len(origin_mkt_means)+0.5)
ax1.set_ylabel(u'市值百分位数', fontproperties=font, fontsize=16)
ax1.set_xlabel(u'十分位分组', fontproperties=font, fontsize=16)
ax1.set_xticks(origin_mkt_means.index)
ax1.set_xticklabels([int(x) for x in ax1.get_xticks()], fontproperties=font, fontsize=14)
ax1.set_yticklabels([str(x*100)+'0%' for x in ax1.get_yticks()], fontproperties=font, fontsize=14)
ax1.set_title(u"因子分组市值分布特征", fontproperties=font, fontsize=16)
ax1.grid()上图展示,该选股因子并没有明显的小市值暴露
4.3 因子分组选股的一个月反转分布特征
n_quantile = 10
# 统计十分位数
cols_mean = [i+1 for i in range(n_quantile)]
cols = cols_mean
hist_returns_means = pd.DataFrame(index=factor_data.index, columns=cols)
# 因子分组的一个月反转分布特征
for dt in hist_returns_means.index:
if dt not in backward_20d_return_data.index:
continue
qt_mean_results = []
# 去掉nan
tmp_factor = factor_data.ix[dt].dropna()
tmp_return = backward_20d_return_data.ix[dt].dropna()
tmp_return_mean = tmp_return.mean()
pct_quantiles = 1.0/n_quantile
for i in range(n_quantile):
down = tmp_factor.quantile(pct_quantiles*i)
up = tmp_factor.quantile(pct_quantiles*(i+1))
i_quantile_index = tmp_factor[(tmp_factor<=up) & (tmp_factor>=down)].index
mean_tmp = tmp_return[i_quantile_index].mean() - tmp_return_mean
qt_mean_results.append(mean_tmp)
hist_returns_means.ix[dt] = qt_mean_results
hist_returns_means.dropna(inplace=True)
# 一个月反转分布特征作图
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(111)
ax2 = ax1.twinx()
hist_returns_means_dist = hist_returns_means.mean()
lns1 = ax1.bar(hist_returns_means_dist.index, hist_returns_means_dist.values, align='center', width=0.35)
lns2 = ax2.plot(excess_returns_means_dist.index, excess_returns_means_dist.values, 'o-r')
ax1.legend(lns1, ['20 day return(left axis)'], loc=2, fontsize=12)
ax2.legend(lns2, ['excess return(right axis)'], fontsize=12)
ax1.set_xlim(left=0.5, right=len(hist_returns_means_dist)+0.5)
ax1.set_ylabel(u'历史一个月收益率', fontproperties=font, fontsize=16)
ax2.set_ylabel(u'超额收益', fontproperties=font, fontsize=16)
ax1.set_xlabel(u'十分位分组', fontproperties=font, fontsize=16)
ax1.set_xticks(hist_returns_means_dist.index)
ax1.set_xticklabels([int(x) for x in ax1.get_xticks()], fontproperties=font, fontsize=14)
ax1.set_yticklabels([str(x*100)+'%' for x in ax1.get_yticks()], fontproperties=font, fontsize=14)
ax2.set_yticklabels([str(x*100)+'0%' for x in ax2.get_yticks()], fontproperties=font, fontsize=14)
ax1.set_title(u"因子选股一个月历史收益率(一个月反转因子)分布特征", fontproperties=font, fontsize=16)
ax1.grid()可以看出,因子和反转因子的相关性较强
5. 因子历史回测净值表现
5.1 简单做多策略
接下来,考察因子的选股能力的回测效果。历史回测的基本设置如下:
- 回测时段为2009年3月1日至2016年11月29日
- 股票池为A股全部股票,剔除上市未满60日的新股(计算因子时已剔除);
- 组合每5个交易日调仓,交易费率设为双边千分之二
- 调仓时,涨停、停牌不买入,跌停、停牌不卖出;
- 每次调仓时,选择股票池中**因子最大的10%**的股票;
start = '2009-03-01' # 回测起始时间
end = '2016-11-29' # 回测结束时间
benchmark = 'ZZ500' # 策略参考标准
universe = set_universe('A') # 证券池,支持股票和基金
capital_base = 10000000 # 起始资金
freq = 'd' # 策略类型,'d'表示日间策略使用日线回测
refresh_rate = 5 # 调仓频率,表示执行handle_data的时间间隔
factor_data = pd.read_csv('AbnormalMA_FullA.csv') # 读取因子数据
factor_data = factor_data[factor_data.columns[:]].set_index('tradeDate')
factor_dates = factor_data.index.values
quantile_ten = 10 # 选取股票的因子十分位数,1表示选取股票池中因子最小的10%的股票
commission = Commission(0.001, 0.001) # 交易费率设为双边千分之二
def initialize(account): # 初始化虚拟账户状态
pass
def handle_data(account): # 每个交易日的买入卖出指令
pre_date = account.previous_date.strftime("%Y-%m-%d")
if pre_date not in factor_dates: # 因子只在每个月底计算,所以调仓也在每月最后一个交易日进行
return
# 拿取调仓日前一个交易日的因子,并按照相应十分位选择股票
q = factor_data.ix[pre_date].dropna()
q_min = q.quantile((quantile_ten-1)*0.1)
q_max = q.quantile(quantile_ten*0.1)
my_univ = q[q>=q_min][q<q_max].index.values
# 调仓逻辑
univ = [x for x in my_univ if x in account.universe]
if len(univ) < 10:
return
# 不在目标股票池中的,卖出
for s in account.valid_secpos:
if s not in univ:
order_to(s, 0)
# 在目标股票池中的,等权买入
buylist = {}
v = account.referencePortfolioValue * 1.05 / len(univ)
for s in univ:
buylist[s] = v / account.reference_price[s] - account.valid_secpos.get(s, 0)
for s in sorted(buylist, key=buylist.get):
order(s, buylist[s])fig = plt.figure(figsize=(12,5))fig.set_tight_layout(True)ax1 = fig.add_subplot(111)ax2 = ax1.twinx()ax1.grid()bt_quantile_ten = btdata = bt_quantile_ten[[u'tradeDate',u'portfolio_value',u'benchmark_return']]data['portfolio_return'] = data.portfolio_value/data.portfolio_value.shift(1) - 1.0data['portfolio_return'].ix[0] = data['portfolio_value'].ix[0]/ 10000000.0 - 1.0data['excess_return'] = data.portfolio_return - data.benchmark_returndata['excess'] = data.excess_return + 1.0data['excess'] = data.excess.cumprod()data['portfolio'] = data.portfolio_return + 1.0data['portfolio'] = data.portfolio.cumprod()data['benchmark'] = data.benchmark_return + 1.0data['benchmark'] = data.benchmark.cumprod()# ax.plot(data[['portfolio','benchmark','excess']], label=str(qt))ax1.plot(data['tradeDate'], data[['portfolio']], label='portfolio(left)')ax1.plot(data['tradeDate'], data[['benchmark']], label='benchmark(left)')ax2.plot(data['tradeDate'], data[['excess']], label='hedged(right)', color='r')ax1.legend(loc=2)ax2.legend(loc=0)ax2.set_ylim(bottom=1.0, top=3)ax1.set_ylabel(u"净值", fontproperties=font, fontsize=16)ax2.set_ylabel(u"对冲指数净值", fontproperties=font, fontsize=16)ax2.set_ylabel(u"对冲指数净值", fontproperties=font, fontsize=16)ax1.set_title(u"因子最大的10%股票周度调仓走势", fontproperties=font, fontsize=16)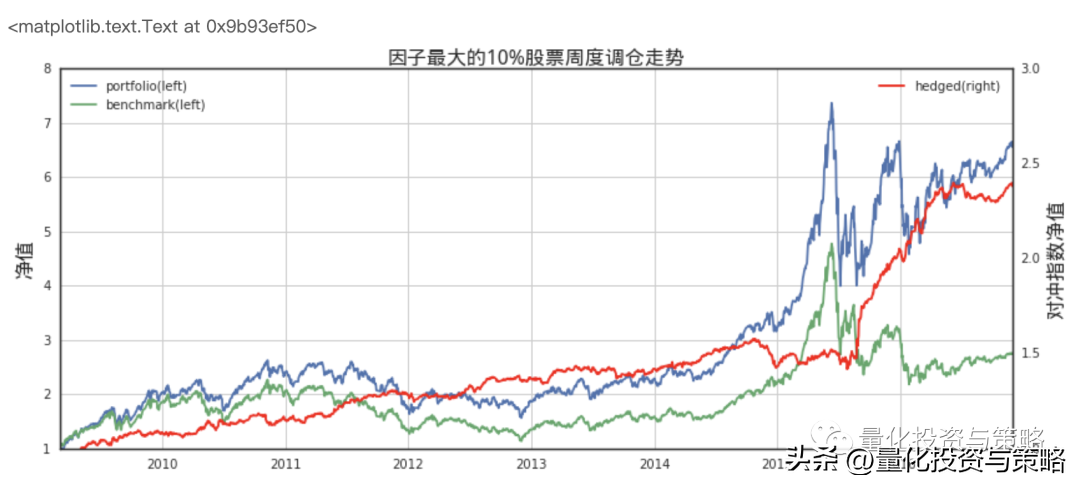
上图显示了简单做多因子最大的10%的股票之后的对冲净值走势,需要注意这里对冲基准为中证500指数
5.2 因子选股 —— 不同五分位数组合回测走势比较
# 可编辑部分与 strategy 模式一样,其余部分按本例代码编写即可
# -----------回测参数部分开始,可编辑------------
start = '2009-03-01' # 回测起始时间
end = '2016-10-12' # 回测结束时间
benchmark = 'ZZ500' # 策略参考标准
universe = set_universe('A') # 证券池,支持股票和基金
capital_base = 10000000 # 起始资金
freq = 'd' # 策略类型,'d'表示日间策略使用日线回测
refresh_rate = 5 # 调仓频率,表示执行handle_data的时间间隔
factor_data = pd.read_csv('AbnormalMA_FullA.csv') # 读取因子数据
factor_data = factor_data[factor_data.columns[:]].set_index('tradeDate')
q_dates = factor_data.index.values
quantile_five = 1 # 选取股票的因子十分位数,1表示选取股票池中因子最小的10%的股票
commission = Commission(0.0005,0.0005) # 交易费率设为双边千分之一
# ---------------回测参数部分结束----------------
# 把回测参数封装到 SimulationParameters 中,供 quick_backtest 使用
sim_params = quartz.SimulationParameters(start, end, benchmark, universe, capital_base)
# 获取回测行情数据
idxmap, data = quartz.get_daily_data(sim_params)
# 运行结果
results = {}
# 调整参数(选取股票的Q因子五分位数),进行快速回测
for quantile_five in range(1, 6):
# ---------------策略逻辑部分----------------
refresh_rate = 5
commission = Commission(0.0005,0.0005)
def initialize(account): # 初始化虚拟账户状态
pass
def handle_data(account): # 每个交易日的买入卖出指令
pre_date = account.previous_date.strftime("%Y-%m-%d")
if pre_date not in q_dates: # 因子只在每个月底计算,所以调仓也在每月最后一个交易日进行
return
# 拿取调仓日前一个交易日的因子,并按照相应十分位选择股票
q = factor_data.ix[pre_date].dropna()
# q = q[q>0]
q_min = q.quantile((quantile_five-1)*0.2)
q_max = q.quantile(quantile_five*0.2)
my_univ = q[q>=q_min][q<q_max].index.values
# 调仓逻辑
univ = [x for x in my_univ if x in account.universe]
if len(univ) < 10:
return
# 不在目标股票池中的,卖出
for s in account.valid_secpos:
if s not in univ:
order_to(s, 0)
# 在目标股票池中的,等权买入
buylist = {}
v = account.referencePortfolioValue * 1.05 / len(univ)
for s in univ:
buylist[s] = v / account.reference_price[s] - account.valid_secpos.get(s, 0)
for s in sorted(buylist, key=buylist.get):
order(s, buylist[s])
# ---------------策略逻辑部分结束----------------
# 把回测逻辑封装到 TradingStrategy 中,供 quick_backtest 使用
strategy = quartz.TradingStrategy(initialize, handle_data)
# 回测部分
bt, acct = quartz.quick_backtest(sim_params, strategy, idxmap, data, refresh_rate=refresh_rate, commission=commission)
# 对于回测的结果,可以通过 perf_parse 函数计算风险指标
perf = quartz.perf_parse(bt, acct)
# 保存运行结果
tmp = {}
tmp['bt'] = bt
tmp['annualized_return'] = perf['annualized_return']
tmp['volatility'] = perf['volatility']
tmp['max_drawdown'] = perf['max_drawdown']
tmp['alpha'] = perf['alpha']
tmp['beta'] = perf['beta']
tmp['sharpe'] = perf['sharpe']
tmp['information_ratio'] = perf['information_ratio']
results[quantile_five] = tmp
print str(quantile_five),
print 'done'warning: get_daily_data is depreciated, please use get_backtest_data instead
1 2 3 4 5 done
fig = plt.figure(figsize=(10,8))
fig.set_tight_layout(True)
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212)
ax1.grid()
ax2.grid()
for qt in results:
bt = results[qt]['bt']
data = bt[[u'tradeDate',u'portfolio_value',u'benchmark_return']]
data['portfolio_return'] = data.portfolio_value/data.portfolio_value.shift(1) - 1.0 # 总头寸每日回报率
data['portfolio_return'].ix[0] = data['portfolio_value'].ix[0]/ 10000000.0 - 1.0
data['excess_return'] = data.portfolio_return - data.benchmark_return # 总头寸每日超额回报率
data['excess'] = data.excess_return + 1.0
data['excess'] = data.excess.cumprod() # 总头寸对冲指数后的净值序列
data['portfolio'] = data.portfolio_return + 1.0
data['portfolio'] = data.portfolio.cumprod() # 总头寸不对冲时的净值序列
data['benchmark'] = data.benchmark_return + 1.0
data['benchmark'] = data.benchmark.cumprod() # benchmark的净值序列
results[qt]['hedged_max_drawdown'] = max([1 - v/max(1, max(data['excess'][:i+1])) for i,v in enumerate(data['excess'])]) # 对冲后净值最大回撤
results[qt]['hedged_volatility'] = np.std(data['excess_return'])*np.sqrt(252)
results[qt]['hedged_annualized_return'] = (data['excess'].values[-1])**(252.0/len(data['excess'])) - 1.0
# data[['portfolio','benchmark','excess']].plot(figsize=(12,8))
# ax.plot(data[['portfolio','benchmark','excess']], label=str(qt))
ax1.plot(data['tradeDate'], data[['portfolio']], label=str(qt))
ax2.plot(data['tradeDate'], data[['excess']], label=str(qt))
ax1.legend(loc=0)
ax2.legend(loc=0)
ax1.set_ylabel(u"净值", fontproperties=font, fontsize=16)
ax2.set_ylabel(u"对冲净值", fontproperties=font, fontsize=16)
ax1.set_title(u"因子不同五分位数分组选股净值走势", fontproperties=font, fontsize=16)
ax2.set_title(u"因子不同五分位数分组选股对冲中证500指数后净值走势", fontproperties=font, fontsize=16)
# results 转换为 DataFrame
import pandas
results_pd = pandas.DataFrame(results).T.sort_index()
results_pd = results_pd[[u'alpha', u'beta', u'information_ratio', u'sharpe',
u'annualized_return', u'max_drawdown', u'volatility',
u'hedged_annualized_return', u'hedged_max_drawdown', u'hedged_volatility']]
for col in results_pd.columns:
results_pd[col] = [np.round(x, 3) for x in results_pd[col]]
cols = [(u'风险指标', u'Alpha'), (u'风险指标', u'Beta'), (u'风险指标', u'信息比率'), (u'风险指标', u'夏普比率'),
(u'纯股票多头时', u'年化收益'), (u'纯股票多头时', u'最大回撤'), (u'纯股票多头时', u'收益波动率'),
(u'对冲后', u'年化收益'), (u'对冲后', u'最大回撤'),
(u'对冲后', u'收益波动率')]
results_pd.columns = pd.MultiIndex.from_tuples(cols)
results_pd.index.name = u'五分位组别'
results_pd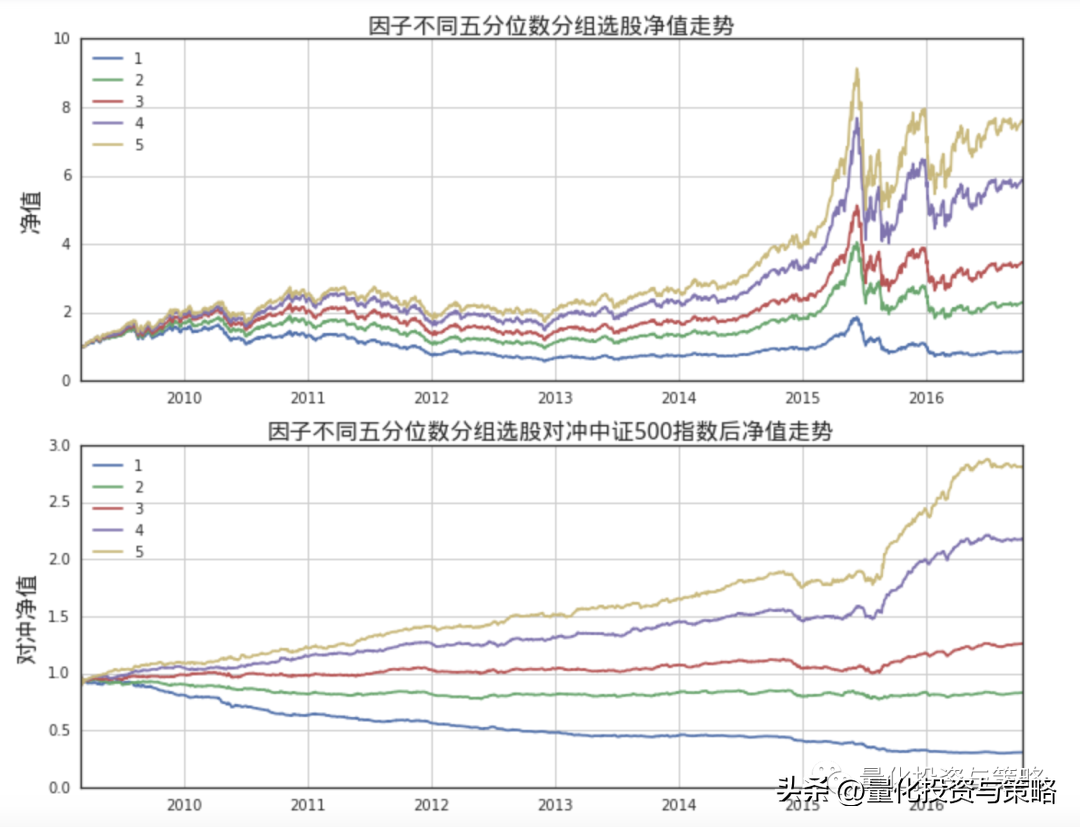
上图显示出,因子选股不同五分位构建等权组合,在uqer进行真实回测的净值曲线;显示出因子的选股能力,不同五分位组合净值曲线随时间推移逐渐散开。
总结
- 本文中,因子最大的股票具有超额收益,实际上这些股票特征为股票近期日内走势和大盘的相关性绝对值很大;
- 这个因子换手率巨高!
- 后面,可以研究日内走势的极端情况,比如逆市涨或者逆势跌的情况。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/321272
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!