
时间序列预测是量化交易领域的经典问题。所谓时间序列,指的是按照时间、空间或其他定义好的顺序形成的一条序列数据。由于时间的连续性,不难想像,时间序列数据会随着时间动态变化。特别地,时间序列的一些统计信息 (例如均值、方差等)会随着时间动态变化。统计学通常将此类时间序列称为非平稳时间序列 (Non-stationary Time Series)。怎样依赖历史的股票、期货数据,预测未来走势,是量化交易算法优劣的关键。


时间序列数据预测
这篇论文介绍了一种新的时间序列预测方法——AdaRNN,它可以解决分布偏移问题。AdaRNN包括两个模块:Temporal Distribution Characterization (TDC)和Temporal Distribution Matching (TDM)。TDC模块旨在自适应地建模时间序列,并捕捉时间依赖性。TDM模块旨在自适应地匹配两个时间段之间的分布,同时捕捉时间依赖性。通过结合这两个模块,AdaRNN可以提高时间序列预测的准确性,并适应不同的时间序列数据集。此外,AdaRNN对于RNN结构和分布匹配距离都是不可知的,可以扩展到Transformer架构中,进一步提高其性能。
AdaRNN可以应用于各种时间序列预测任务,包括但不限于以下领域:
1. 活动识别:通过对人体运动的时间序列进行建模,可以识别人体的不同活动,如步行、跑步、骑车等。
2. 空气质量预测:通过对空气质量的时间序列进行建模,可以预测未来的空气质量,帮助人们做好健康防护。
3. 家庭用电量预测:通过对家庭用电量的时间序列进行建模,可以预测未来的用电量,帮助人们更好地管理家庭用电。
4. 股票价格预测:通过对股票价格的时间序列进行建模,可以预测未来的股票价格,帮助投资者做出更明智的投资决策。
在本文中,作者通过实验验证了AdaRNN在这些领域的应用效果,并与现有方法进行了比较。结果表明,AdaRNN在分类任务的准确性上比现有方法提高了2.6%,在回归任务的RMSE上比现有方法提高了9.0%。因此,AdaRNN可以作为一种通用的时间序列预测方法,适用于各种领域的应用。
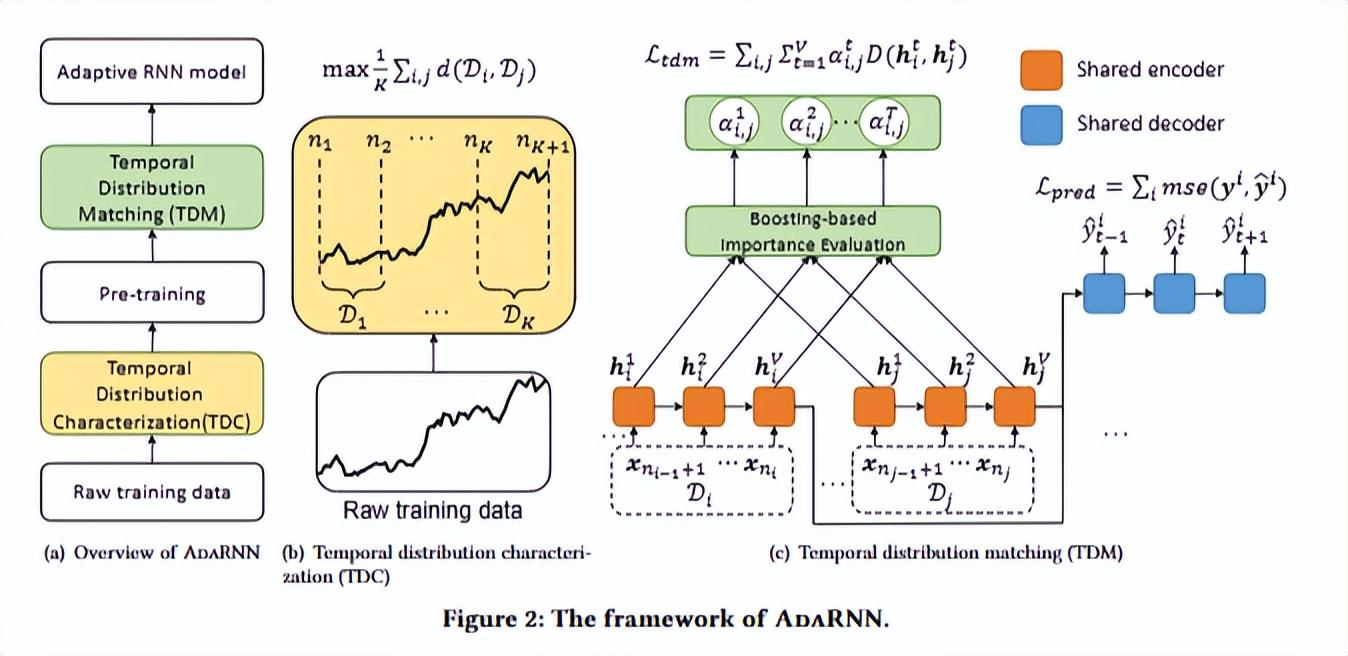
AdaRNN框架
上图示意了算法的流程和框架结构。主流程:输入初始训练数据->时间分布表征化(TDC)->预训练->时间分布匹配->RNN模型。
TDC(Temporal Distribution Characterization)是AdaRNN框架中的第一个模块,用于将时间序列数据划分为K个最不相似的时间段。TDC的计算过程如下:
1. 首先,将时间序列数据划分为K个时间段,每个时间段包含相同数量的数据点。
2. 对于每个时间段,计算其数据分布的熵,即使用公式(1)计算: H(Di) = -∑p(x)logp(x) (1) 其中,Di表示第i个时间段的数据分布,p(x)表示数据点x在Di中出现的概率。
3. 对于每对时间段Di和Dj,计算它们之间的分布距离,即使用公式(2)计算: d(Di, Dj) = H(Di) + H(Dj) – 2H(Di, Dj) (2) 其中,H(Di, Dj)表示Di和Dj的联合分布熵。
4. 使用公式(3)计算K个时间段的最大距离: max{d(Di, Dj)},其中1 ≤ i < j ≤ K
5. 使用公式(4)计算K个时间段的最小距离: min{d(Di, Dj)},其中1 ≤ i < j ≤ K
6. 使用公式(5)计算K个时间段的平均距离: avg{d(Di, Dj)},其中1 ≤ i < j ≤ K
7. 使用公式(6)计算K个时间段的方差: var{d(Di, Dj)},其中1 ≤ i < j ≤ K
8. 最后,使用公式(7)计算每个时间段的权重: wi = (dmax – di) / (dmax – dmin) (7) 其中,dmax和dmin分别是K个时间段的最大距离和最小距离,di是第i个时间段的距离最小值,wi表示第i个时间段的权重。这个权重表示了每个时间段的相似度,越相似的时间段权重越大,越不相似的时间段权重越小。这个权重将被用于AdaRNN的第二个模块TDM(Temporal Distribution Matching)中,以减少时间序列数据的分布差异。
AdaRNN的第二个模块是Temporal Distribution Matching (TDM),旨在自适应地匹配两个时间段之间的分布,同时捕捉时间依赖性。TDM模块包括两个部分:预训练和增强。以下是TDM模块的详细计算过程:
1. 预训练:预训练过程旨在学习一个映射函数,可以将一个时间段的分布转换为另一个时间段的分布。具体而言,预训练过程包括两个步骤: a. 计算源时间段和目标时间段中每个RNN单元的分布的均值和方差。b. 训练一个前馈神经网络,将源时间段的均值和方差映射到目标时间段的均值和方差。
2. 增强:增强过程旨在优化预训练过程中学习的映射函数。具体而言,增强过程包括两个步骤: a. 计算源时间段和目标时间段的预测分布之间的残差误差。 b. 训练一个前馈神经网络,将残差误差映射到更新后的映射函数。
3. 最终的映射函数是通过将预训练过程中学习的映射函数和增强过程中学习的更新映射函数相结合得到的。
4. TDM模块的损失函数定义为源时间段和目标时间段的预测分布之间的均方误差和正则化项之和,其中正则化项是预测分布和目标分布之间的Kullback-Leibler散度。
实验效果
论文作者使用了一个大型的私人金融数据集来评估AdaRNN在股票价格预测方面的性能。该数据集包含超过2.8M个样本,其中包括360个金融因素作为特征。作者将数据集分成三个部分:训练集、验证集和测试集。具体而言,作者使用了2007年1月至2014年12月数据作为训练集,2015年1月至2016年12月的数据作为验证集,以及2017年1月至2019年12月的数据作为测试集。

股票预测指标对比
对比的算法包括有LightGBM, GRU, Transformer等经典算法。指标使用信息系数(IC)和信息比率(IR)作为评估指标,这些指标是现有工作中常用的指标。结果表明,AdaRNN在测试集上的IC和IR分别为0.032和0.045,比现有方法表现更好。此外,作者还比较了AdaRNN和其他方法在预测截面数据上的表现,结果表明,AdaRNN在预测截面数据上的RMSE比其他方法低。
总的来说,这些实验结果表明,AdaRNN在股票价格预测方面具有很好的性能,可以作为一种有效的时间序列预测方法。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/289025
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!