
未来几周,我们会做的几件事情:
1、数据方面:
基础量价数据自动更新,目前计划三类数据:指数、ETF、期货。(日线),期货是主连合约日线。
其他如果大家有需要,或者有好的数据源,请提供。
自动dump到csv供回测引擎使用,自动更新网站上策略的结果,产生交易信号。
basic信息,instruments列表信息。
2、整合单因子分析框架,主要是alphalens分析框架。
结合因子表达式,对单因子进行分析。
3、单因子回测策略。
4、因子挖掘整合进来——主要使用deap(也许会纳入gplearn这个看需要)。
5、StockRanker——基于lightGBM,多因子排序。
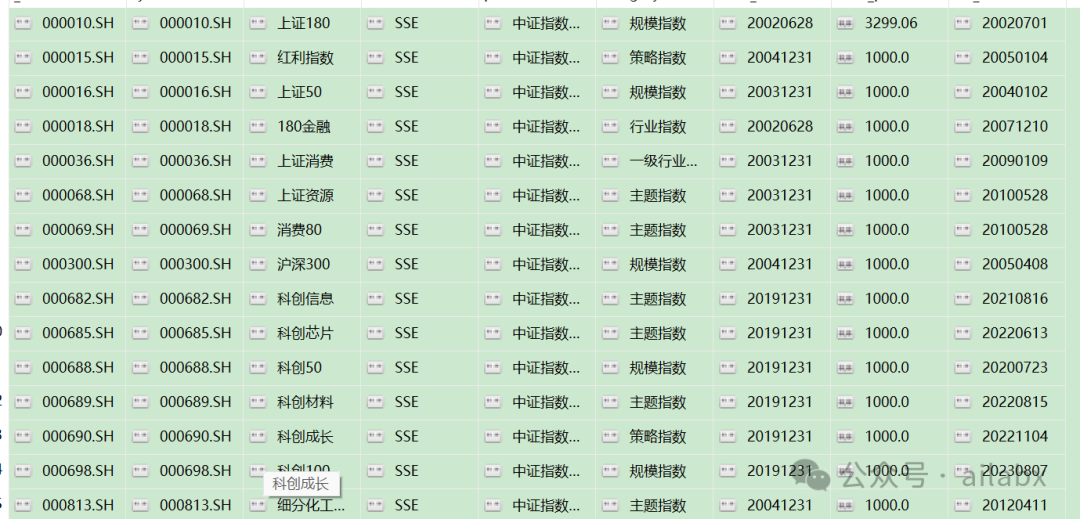
A股的指数,我同步了126支,至少有一支ETF基金的指数,也就是说,这个指数是可以交易的。
ETF排重之后(像沪深300指数的ETF有几十支)有150多支,从量化的角度,我们选择交易量最大的,通常也是规模最大的一支即可。——像黄金ETF,不方便同步指数数据的,直接使用ETF数据。
大家可以会好奇,为何不直接使用ETF,使用ETF自然是方便,但有些ETF的上市时间很短,所以数据很有限。而指数则会从更早的时间开始。
因此,我们把两份数据都提供。
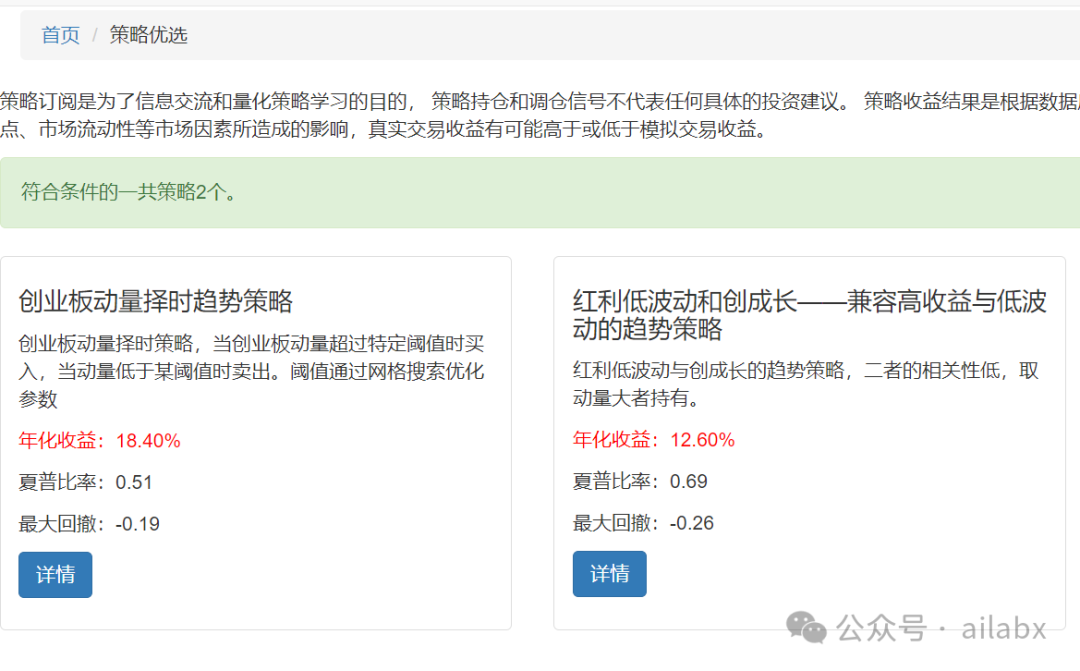
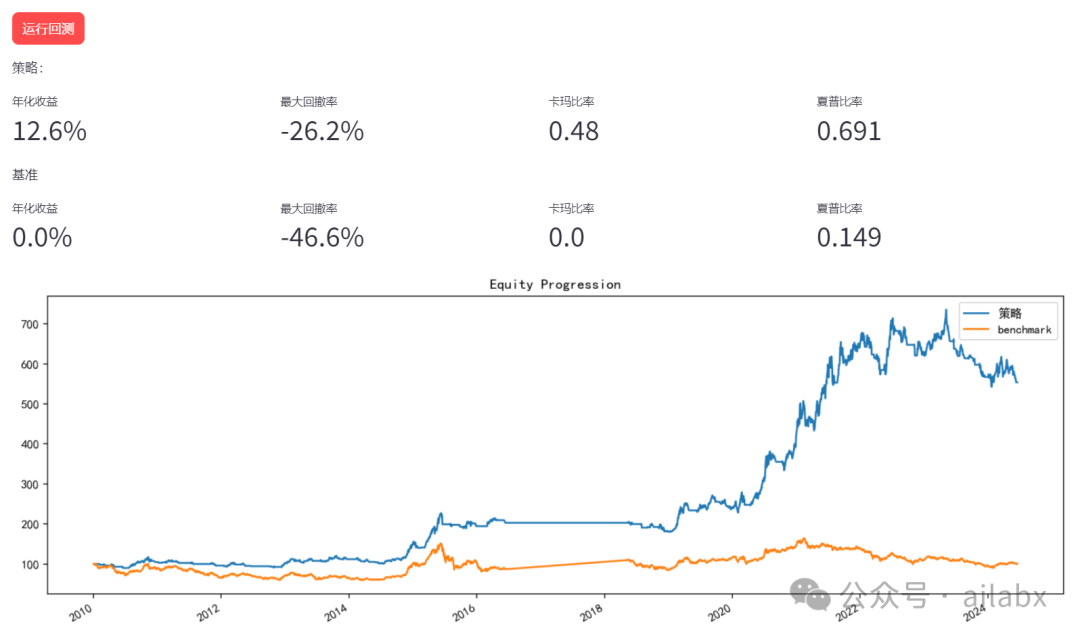
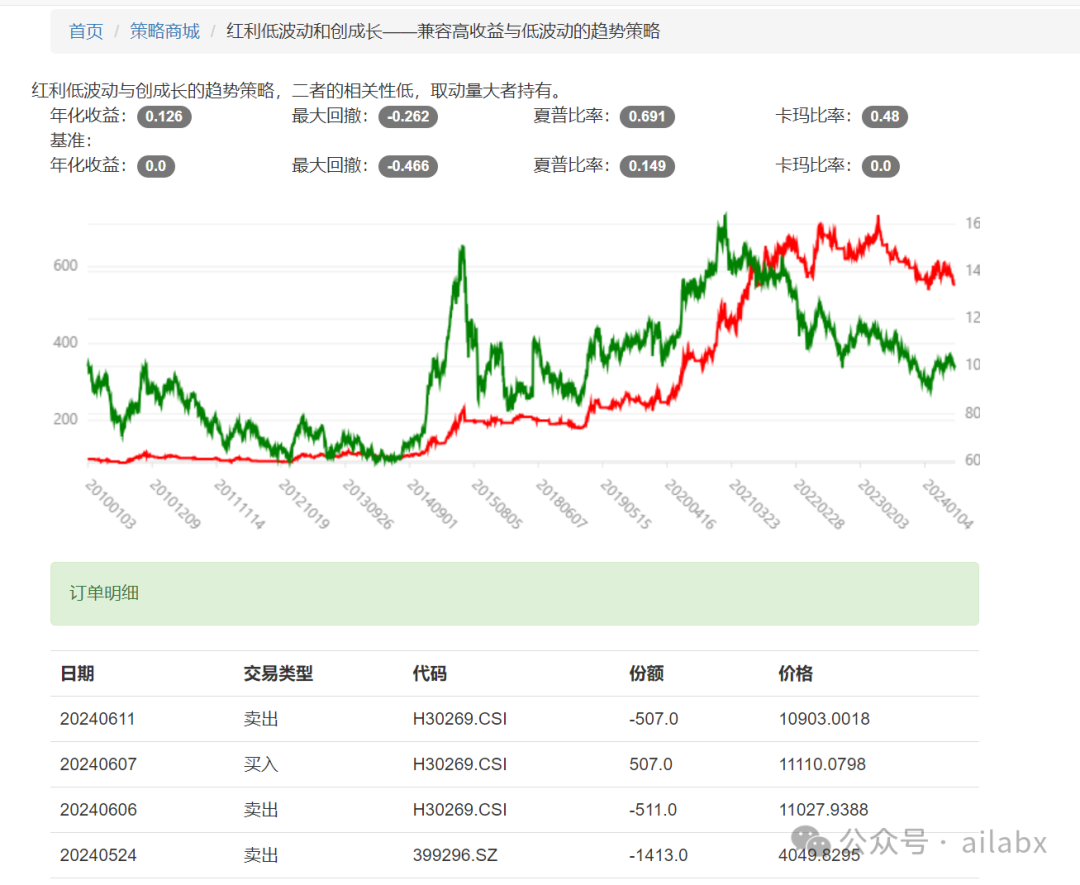
昨天有同学留言,说希望提升因子挖掘的优先级,安排。
在因子挖掘之前,还是要新增单因子分析功能,否则你如何知道单个因子是好或不好。
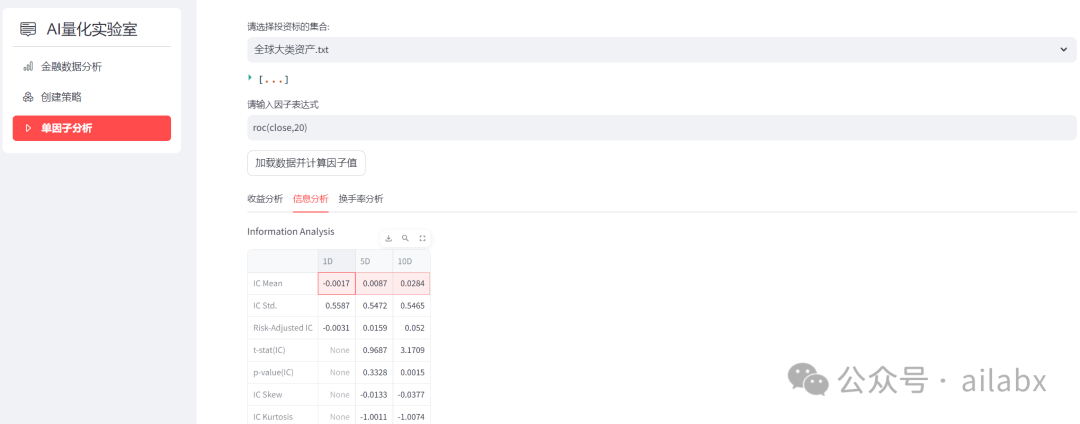
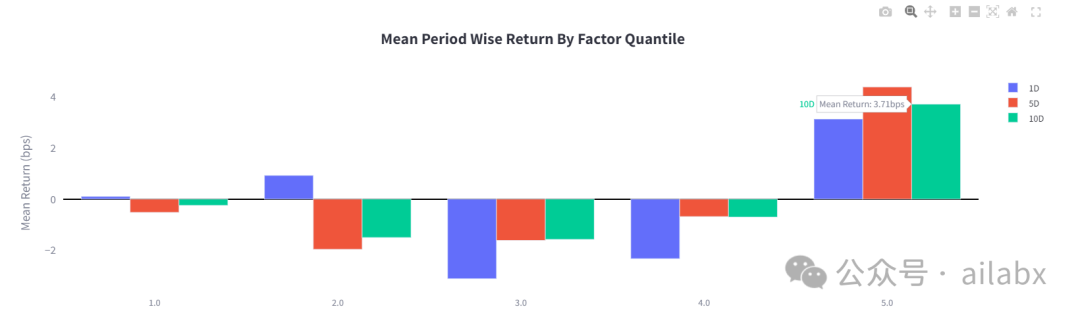
在大类资产上,两周(10天)的动量IC值是明显的,因此,我们之前的周调仓,应该优化成两周调仓。
因子单调性一般:
单因子分析的代码如下——其实形式上与notebook还是streamlit无关——streamlit可以做交互,比如大家自己一选就可以直接查看结果,而notebook需要修改一点代码:
import streamlit as st def build_page(): from config import DATA_DIR instru = DATA_DIR.joinpath('instruments') import os files = os.listdir(instru.resolve()) filename = st.selectbox('请选择投资标的集合:', options=files) with open(instru.joinpath(filename).resolve(), 'r') as f: symbols = f.readlines() symbols = [s.replace('\n', '') for s in symbols] st.write(symbols) factor_expr = st.text_input('请输入因子表达式', value='roc(close,20)') if st.button('加载数据并计算因子值'): with st.spinner('回测进行中,请稍后...'): from datafeed.dataloader import CSVDataloader loader = CSVDataloader() df = loader.get_df(symbols=symbols, set_index=True) df = loader.calc_expr(df, fields=[factor_expr], names=['factor_name']) # df.set_index(['date', 'symbol'], inplace=True) factor_df = df[['factor_name','symbol']] factor_df.set_index([factor_df.index, 'symbol'], inplace=True) close_df = loader.get_col_df(df, col='close') from alpha.alphalens.utils import get_clean_factor_and_forward_returns results = get_clean_factor_and_forward_returns(factor_df, close_df) # st.write(results) from alpha.alphalens.streamit_tears import create_full_tear_sheet create_full_tear_sheet(results)
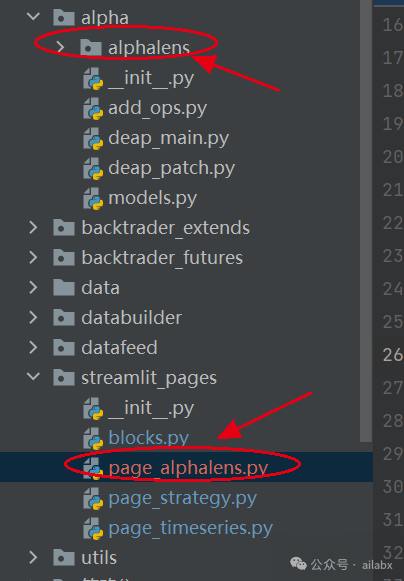
代码位置如下:
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/134180
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!
![[通达信指标]收藏的起爆副图公式](https://95sca.cn/2024/08/07/AibKibsVz2KOUlw1722997347.3937511.jpg?imageMogr2/thumbnail/!480x300r|imageMogr2/gravity/center/crop/480x300)




