
一 GBDT模型存在的问题
GBDT是一种被广泛应用于各个领域的机器学习模型,但在特征选择和过拟合方面存在偏差问题。当涉及到特征选择时,传统的GBDT模型存在一些偏差问题。具体来说,传统的GBDT模型对特征的重要性评估可能存在一定的偏差。这种偏差可能导致对某些重要特征的低估或对某些不重要特征的高估,从而影响了特征选择的准确性和可靠性。另外,GBDT模型在处理过拟合时也存在一些偏差问题。过拟合是指模型在训练数据上表现很好,但在新数据上表现较差的现象。传统的GBDT模型在训练过程中容易过度拟合训练数据,导致模型在新数据上的泛化能力下降。这主要是因为传统的GBDT模型在构建每棵树时没有充分考虑泛化性能,可能导致过于复杂的树结构,进而导致过拟合问题。
二 UnbiasedGBM的算法介绍
过去的方法主要关注计算无偏特征重要性和重新设计分裂算法的新树构建算法,但这些方法大多适用于随机森林,无法推广到GBDT。考虑到现有的GBDT实现在表格数据建模中的主导地位,有必要解决GBDT中由偏差引起的解释性和过拟合问题。
本文旨在提出一种无偏的GBDT方法(UnbiasedGBM)来解决这些问题。这个方法与传统的GBDT模型不同,它使用总体分布而非经验分布进行训练,以便更好地理解和检查模型中的偏差。为了解决偏差问题,UnbiasedGBM方法进行了详细的分析,并确定了GBDT模型中的偏差来源。作者发现,增益估计中存在系统偏差,同时分割查找算法也存在偏差。为了解决这些问题,他们引入了一种新的特征重要性度量,称为无偏增益,并将无偏性属性纳入分割查找算法中。UnbiasedGBM算法通过选择具有不同基数的特征,并评估每个分割的泛化性能来减轻过拟合问题。换句话说,算法会尝试使用不同数量的特征来构建每棵树,并评估每个特征分割的效果,以找到最佳的分割点。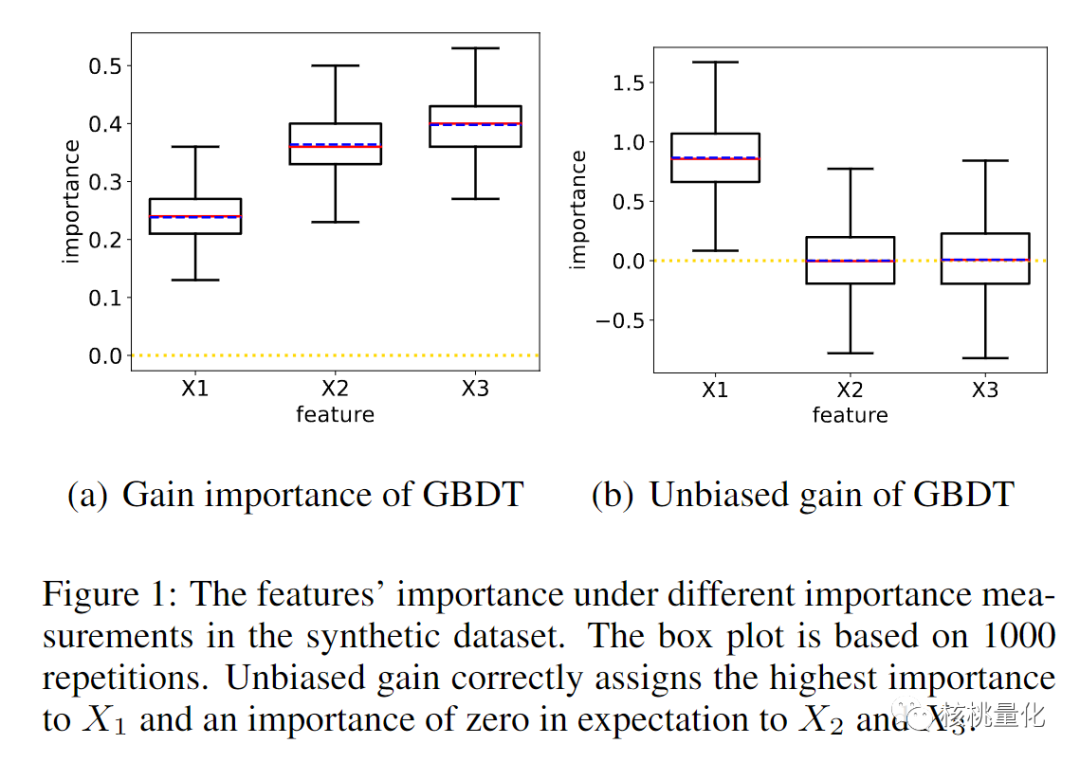

三 与GBDT模型进行实验对比
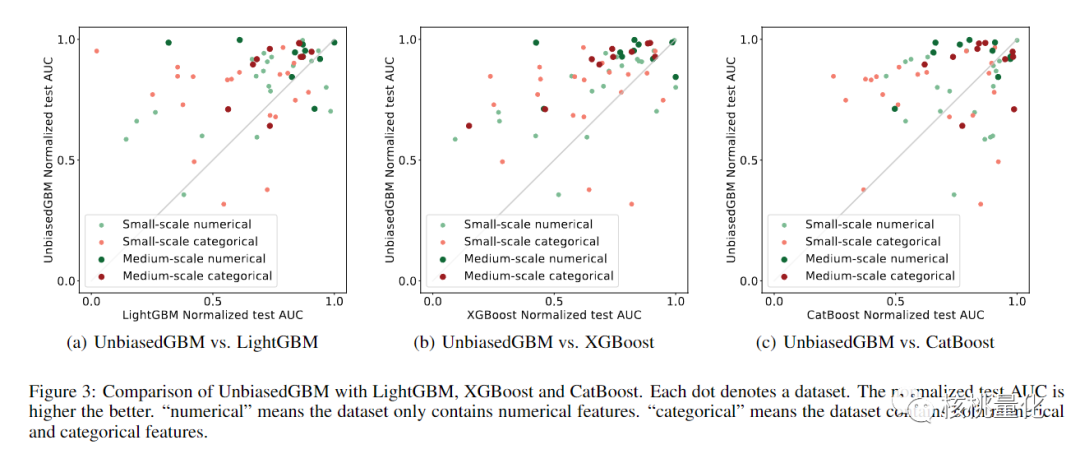
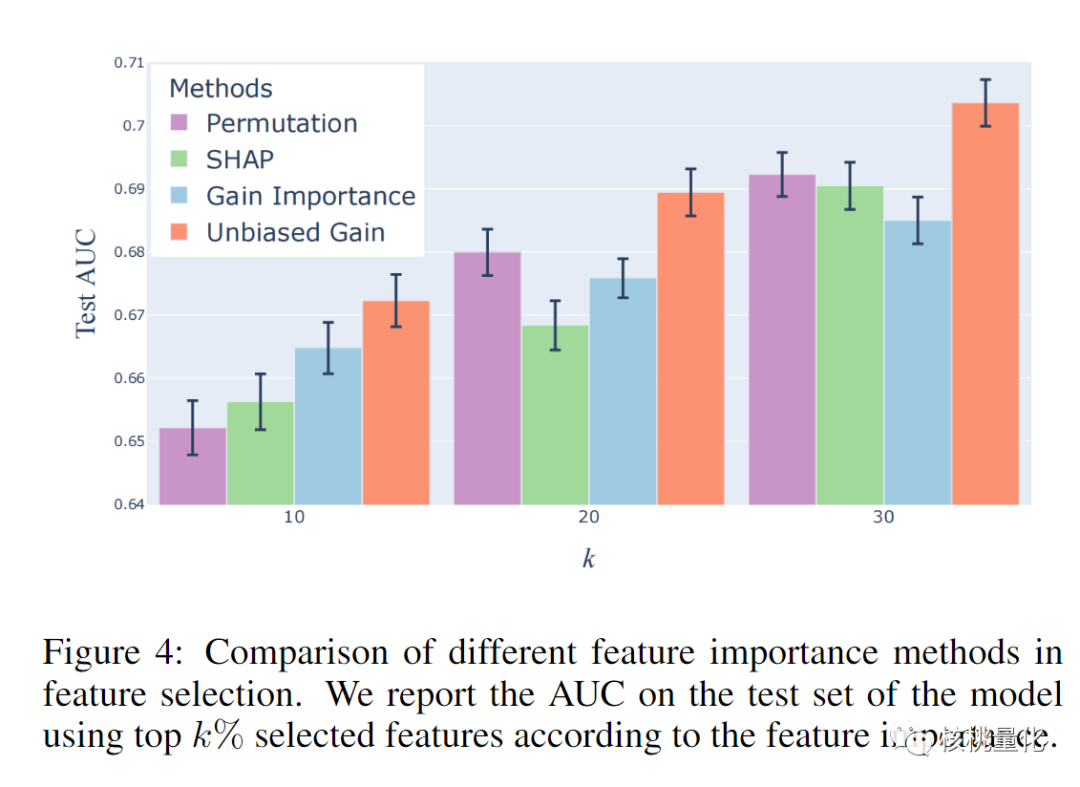
为了评估UnbiasedGBM方法的性能,作者进行了大规模的实证研究,使用包含60个数据集的测试集。研究结果显示,UnbiasedGBM在平均性能上优于其他流行的GBDT实现,如LightGBM、XGBoost和Catboost。此外,无偏增益在特征选择方面的性能也优于其他特征重要性方法。
四 UnbiasedGBM的使用示例
使用UnbiasedGBM训练模型
from UnbiasedGBM import UnbiasedBoost
...
model = UnbiasedBoost('logloss', params['n_est'], params['min_leaf'], params['thresh'], 3, params['lr'], 1)
score, pred = model.fit(X_train, y_train, testset=(metric, X_test, y_test.values), mono_h=1, large_leaf_reward=params['power'], score_type='advance')
支持XGBoost和LightGBM
seed = 998244353
model = (lgb.LGBMRegressor if task=='regression' else lgb.LGBMClassifier)(random_state=seed, learning_rate=1, n_estimators=5)
model.fit(X_train, y_train.values)
pred = model.predict(X_test) if task=='regression' else model.predict_proba(X_test)[:,1]
print(model.feature_importances_)
losstool = UnbiasedGain.MSE_tool() if task=='regression' else UnbiasedGain.logloss_tool()
UnbiasedGain.calc_gain(model, X_train, y_train, X_test, y_test, losstool)
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111105
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!