
一. 什么是在线机器学习
在线机器学习是一种机器学习的方法,其中模型通过逐个处理数据流中的样本来进行训练和更新。与传统的批处理方式相比,在线机器学习可以在数据流不断到达的情况下实时地进行模型训练和预测。这种方法对于需要快速适应变化的数据和环境的应用场景非常有用。在线机器学习的关键特点如下:
-
面向数据流:在线机器学习操作的对象是数据流,即由一系列单个元素(样本或观察结果)组成的序列。每个样本包含一堆特征,可以遵循固定的结构,但随着时间的推移,功能可能会出现和消失。数据流可以分为被动式和主动式两种类型。被动数据流是不受控制地向您发送数据的数据流,而主动数据流是您可以控制的数据流。 -
在线进行模型学习:在线处理是一次处理一个数据流的行为,即通过逐个样本的方式训练模型,而不是一次在整批数据上进行训练。在线模型是有状态的动态对象,可以在不重新访问过去数据的情况下不断学习和更新。
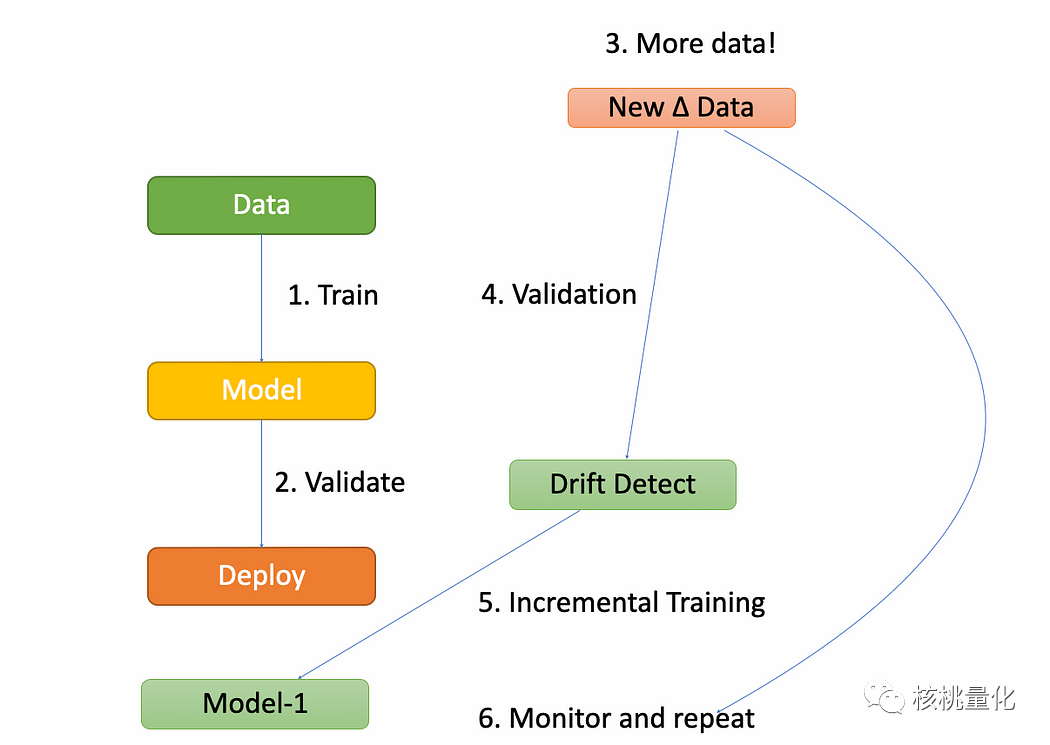

在线机器学习的主要优点包括:
-
实时性:在线机器学习可以在数据到达时立即进行模型更新,实现实时预测和决策。这对于需要快速响应和适应变化的应用非常重要,如金融交易、广告投放和智能推荐系统等。 -
资源效率:由于在线学习只需要处理当前的数据样本,而不需要保留整个训练数据集,因此可以节省存储和计算资源。这对于大规模数据集和资源受限的环境非常有益。 -
自适应性:在线机器学习可以适应数据分布的变化和概念漂移,因为它可以在每个新样本到达时更新模型。这使得模型能够持续适应新的数据模式和趋势,提高模型的鲁棒性和准确性。
二. River是什么
River是一个用于构建在线机器学习模型的Python库。River提供了一组用于在线机器学习的工具和算法,使得在处理数据流时可以实时学习和适应新的数据。它支持各种机器学习任务,并使用字典作为基本构建块,以提供高效的处理能力。River库的主要特点如下:
-
支持被动式和主动式数据流:River可以处理来自各种数据源的数据流,无论是被动数据流还是主动数据流。被动数据流是无法控制的,例如用户访问网站时产生的数据。而主动数据流是可以被控制的,例如从文件中读取数据。 -
在线加工:River支持在线处理,即一次处理一个数据样本。与传统的批量处理不同,在线处理是动态的,模型可以实时学习并适应新的数据。这种方式避免了重新训练整个模型的开销。 -
支持各种机器学习任务:River致力于成为一个通用的机器学习库,支持各种任务,包括分类、回归、异常检测、时间序列预测等。它提供了不同任务的在线算法实现,并且与批量处理的机器学习算法具有相似的功能。 -
使用字典作为基本构建块:River使用Python中的字典作为基本数据结构,用于表示和处理数据。字典可以方便地命名和存储特征,适用于在线处理的场景。此选择是为了避免使用数值处理库带来的额外开销,使得River在性能上更高效。
三. 安装和使用
River 适用于 Python 3.8 及更高版本。可以通过以下方式完成安装pip:
pip install river
下面是使用river进行癌症预测的使用示例:
from sklearn import datasets
from sklearn import metrics
from sklearn import model_selection
from sklearn import pipeline
from sklearn import preprocessing
from river import linear_model
from river import optim
from river import stream
# 创建数据预处理器
scaler = preprocessing.StandardScaler()
# 创建优化器
optimizer = optim.SGD(lr=0.01)
# 创建逻辑回归模型
log_reg = linear_model.LogisticRegression(optimizer)
# 存储真实标签和预测标签
y_true = []
y_pred = []
# 加载乳腺癌数据集
dataset = datasets.load_breast_cancer()
# 创建数据流迭代器并随机打乱数据
stream_dataset = stream.iter_sklearn_dataset(dataset, shuffle=True, seed=42)
# 遍历数据流
for xi, yi in stream_dataset:
# 特征缩放
xi_scaled = scaler.learn_one(xi).transform_one(xi)
# 在新的“未观察到”样本上测试当前模型
yi_pred = log_reg.predict_proba_one(xi_scaled)
# 使用新样本训练模型
log_reg.learn_one(xi_scaled, yi)
# 存储真实标签和预测标签
y_true.append(yi)
y_pred.append(yi_pred[True])
# 计算ROC AUC指标并打印结果
roc_auc = metrics.roc_auc_score(y_true, y_pred)
print(f'ROC AUC: {roc_auc:.3f}')
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111103
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!