
赛马是一项古老而受欢迎的运动,涉及赛马和骑手之间的竞争,通常在马场上进行,赛马会在预定的赛道上奔跑一定距离。比赛的胜利者通常是第一个到达终点线的赛马。预测赛马排名和预测股票排名在某些方面非常相似。这两个问题都是排名问题,需要对一组数据进行排序。在预测赛马排名中,需要对赛马进行排序,以预测哪匹赛马最有可能获胜。在预测股票排名中,需要对股票进行排序,以预测哪些股票可能会获得更高的收益。
在预测赛马排名中,需要考虑赛马的历史成绩、属性、赛道和天气等因素。在预测股票排名中,需要考虑股票的基本面和技术面因素,以及整个市场和经济环境等因素。因此,预测赛马排名和预测股票排名都需要综合考虑多个因素,并对这些因素进行分析和建模。这些问题的解决方案通常都是使用机器学习技术,例如监督学习中的“学习排名”(Learning to Rank)技术。
排名算法和其他机器学习方法的不同之处在于它们的目标和方法:
-
排名算法的目标是对一组数据进行排序,以提供更好的用户体验,而其他机器学习方法的目标可能是分类、回归、聚类等。 -
排名算法通常使用排序度量来评估模型的性能,例如NDCG、MAP等,而其他机器学习方法通常使用分类准确率、均方误差等指标来评估模型的性能。 -
排名算法通常需要考虑多个因素来进行排序,例如文本相似度、关键词匹配度、历史点击记录等,而其他机器学习方法可能只需要考虑一个或几个因素。 -
排名算法通常使用监督学习中的学习排名(Learning to Rank)技术来训练模型,例如RankNet、LambdaRank、ListNet和ListMLE等,而其他机器学习方法可能使用其他类型的算法,例如决策树、神经网络、支持向量机等。
XGBRanker是XGBoost库中用于排名问题的特定模型。它是一种监督学习算法,使用梯度提升树方法来学习如何对一组项目进行排序。下面展示如何使用XGBRanker进行排序算法的预测。
数据准备
对于XGBRanker,数据准备步骤与其他监督学习算法存在一些不一样的地方,但是需要特别注意以下几点:
-
XGBRanker需要指定每个样本所属的组ID,以确保在训练和测试过程中,所有属于同一组或查询的样本都被分配到同一组中; -
每个数据的label应该是组内的排序结果; -
数据拆分需要使用GroupShuffleSplit方法进行拆分,以确保同一组或查询的样本不会被分配到训练集和测试集的不同组中。
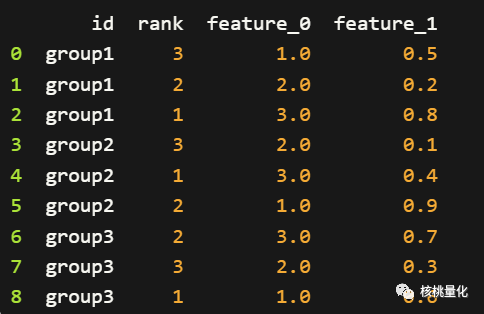
一个示例的排序数据如下图所示,id列是组ID列,rank列是组内排序结果,feature_0和feature_1是特征。

使用下面代码对数据进行训练集和验证集的划分:
import pandas as pd
from sklearn.model_selection import GroupShuffleSplit
df = pd.read_csv('horse_race_data.csv')
gss = GroupShuffleSplit(test_size=.40, n_splits=1, \
random_state=7).split(df, groups=df['id'])
# 生成训练集和验证集的索引
X_train_inds, X_test_inds = next(gss)
train_data= df.iloc[X_train_inds]
X_train = train_data.loc[:, ~train_data.columns.isin(['id','rank'])]
y_train = train_data.loc[:, train_data.columns.isin(['rank'])]
test_data= df.iloc[X_test_inds]
X_test = test_data.loc[:, ~test_data.columns.isin(['rank'])]
y_test = test_data.loc[:, test_data.columns.isin(['rank'])]
使用XGBRanker训练排序模型:
import xgboost as xgb
model = xgb.XGBRanker(
tree_method='auto',
booster='gbtree',
objective='rank:pairwise',
random_state=42,
learning_rate=0.1,
colsample_bytree=0.9,
eta=0.05,
max_depth=6,
n_estimators=110,
subsample=0.75
)
# 训练排序模型
model.fit(X_train, y_train, group=groups, verbose=True)
使用训练得到的模型进行分组预测:
def predict(model, df):
return model.predict(df.loc[:, ~df.columns.isin(['id'])])
predictions = (data.groupby('id').apply(lambda x: predict(model, x)))
下面是一个马匹排名的预测结果,每个列表包含按预测排名降序排列的每匹马的起始编号。数据来源于Solvala 2021-02-23的V64比赛。
预测排名:
实际的第一名: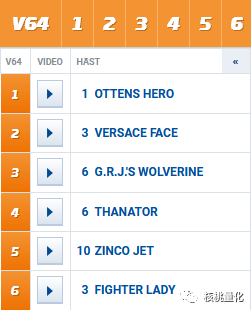
可以看到,6场比赛中,该模型可以在3场中正确预测出第一名,如果放宽到前两名的预测,有五场比赛是正确预测的。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111098
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!