
过去几年来,深度学习模型在图像识别和自然语言处理等领域得到了广泛应用。然而,最近研究人员开始探索将深度学习应用于表格数据的可能性。表格数据通常以结构化形式存在,如CSV表格,具有行和列的结构。本研究通过对比一些常见基准模型在表格任务上的表现,发现ResNet架构在处理表格任务时表现良好。此外,本文还提出了FT-Transformer结构,它在大多数任务上优于其他深度学习解决方案,并且与GBDT等树模型相比也表现出色。
基准模型
模型1 :MLP
MLP是一种基本的前馈神经网络模型。它由一个或多个隐藏层组成,每个隐藏层包含多个神经元节点。MLP模型的输入通过层与层之间的连接传递,并通过激活函数进行非线性转换。

模型2: ResNet
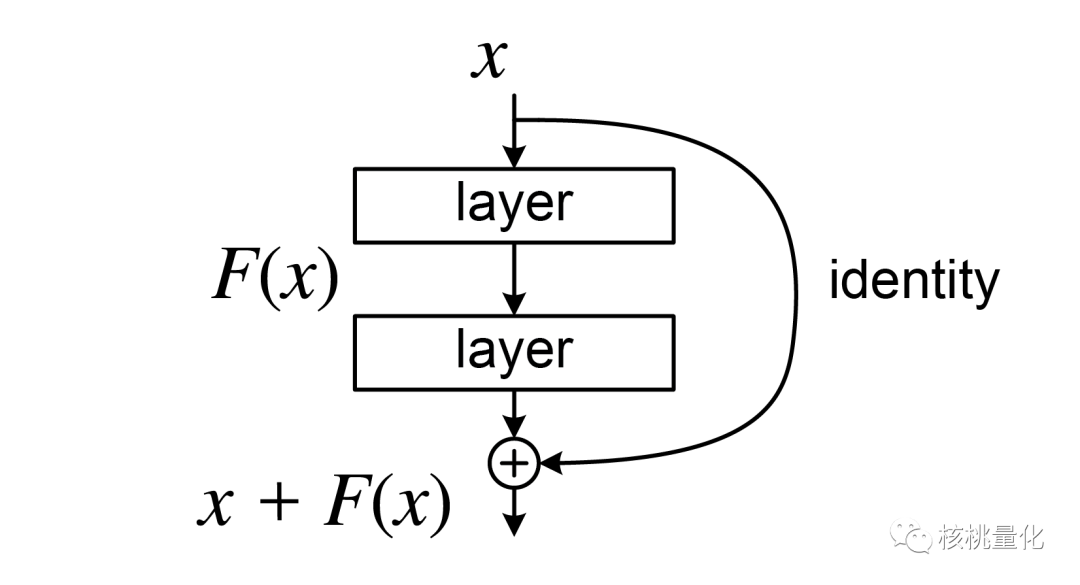
ResNet(Residual Neural Network)是一种深度残差网络模型,由微软研究院的Kaiming He等人于2015年提出。它在深度学习中扮演着重要的角色,并在图像识别和计算机视觉任务中取得了显著的成果。
传统的深度神经网络随着层数的增加,存在梯度消失或梯度爆炸的问题,导致训练困难。ResNet通过引入残差连接(residual connection)解决了这个问题。残差连接允许信息直接跳过某些层,从而保持梯度流动。这样做的好处是即使在网络变得非常深时,也可以更轻松地训练模型。ResNet的基本组建块是Residual Block(残差块)。每个残差块包含了两个主要的部分:一个恒等映射(identity mapping)和一个残差映射(residual mapping)。恒等映射将输入直接传递到输出,而残差映射则对输入进行转换并添加到恒等映射上。这样,输出可以通过学习残差来适应输入。
模型3:FT-Transformer
FT-Transformer是一种将Transformer架构应用于表格数据的方法。该方法可以在处理tabular数据时利用Transformer的优势。
首先,原始输入是表格数据。通过使用Feature Tokenizer对每个特征进行升维处理,并生成对应的权重向量。这些权重向量可以捕捉到特征之间的关系和重要性。数值特征被处理为:将数值特征的每个维度与相应的权重向量进行元素级乘法,并加上偏置项。这样可以对数值特征进行编码,保留了其信息。类别特征被处理为:对于类别特征,首先进行独热编码,然后将编码后的向量与权重矩阵相乘,并加上偏置项。这样可以将类别特征转换为连续的向量表示。
经过特征处理后,所有转换后的向量被堆叠在一起,形成最终的特征表示。然后,这些特征向量被输入到多个Transformer块中进行变换。每个Transformer块由自注意力机制和前馈神经网络组成,用于学习特征之间的依赖关系和提取高级特征表示。
最后,通过Transformer块中最后一个位置的[CLS] token对应的嵌入向量,产生最终的输出。这个输出可以用于回归、分类或其他任务。
FT-Transformer的核心思想是将表格数据转换为特征向量,并使用Transformer模块对这些向量进行变换。这样的设计使得FT-Transformer能够更好地处理表格数据,并提取出有用的特征表示,以进一步提高表格数据的建模和预测能力。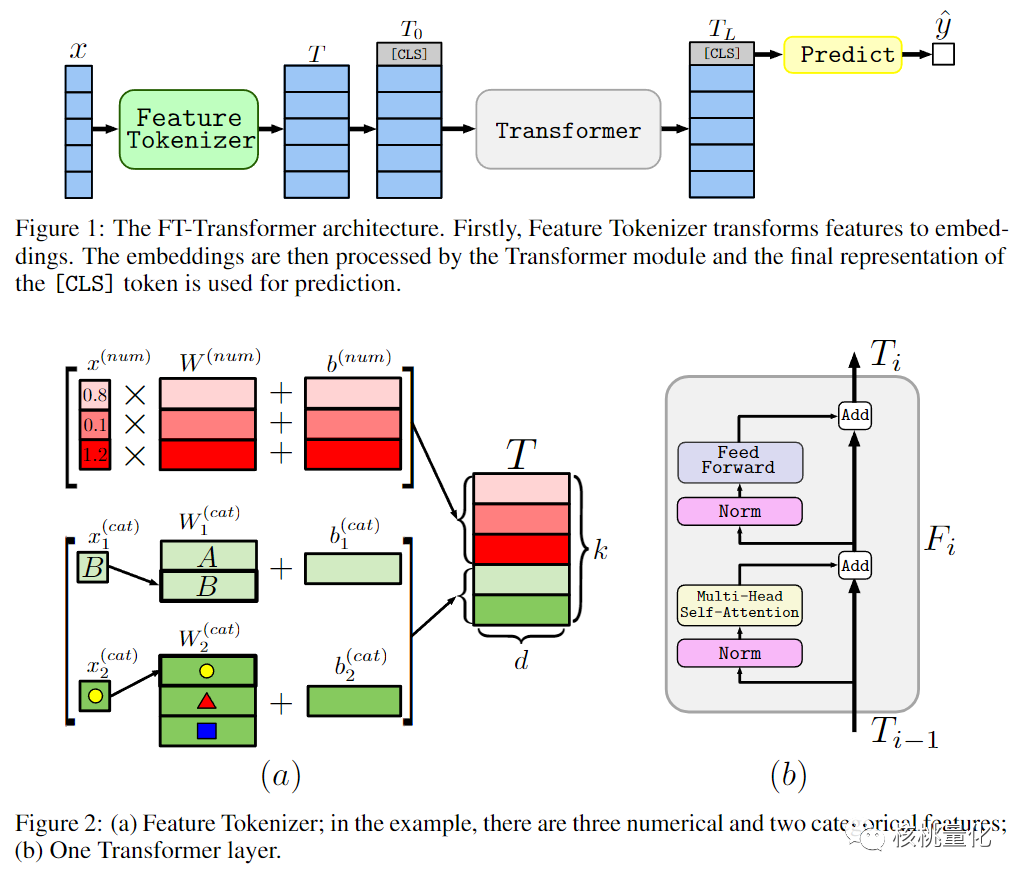
模型4:SNN (Stochastic Neural Networks)
SNN这是一种类似于多层感知器(MLP)的架构,使用SELU激活函数来实现训练更深层次的模型。SELU激活函数具有自标准化的特性,可以帮助缓解梯度消失和爆炸问题。
模型5: NODE (Network of Oblivious Decision Ensembles)
NODE这是一种可微集成的决策树模型。它将多个无意识决策树(oblivious decision trees)组合在一起,通过学习权重来进行集成预测。
模型6: TabNet
TabNet是一种循环架构,它通过动态重新加权特征和传统的前馈模块交替进行操作。TabNet在处理表格数据时,能够有效地选择和利用关键特征,并提供较好的性能。
模型7: GrowNet
GrowNet这是一种使用渐进增强的弱MLP(Multi-Layer Perceptron)的模型。
模型8: DCN V2 (Deep & Cross Network Version 2)
DCN V2由类似于MLP的模块和特征交叉模块组成。特征交叉模块结合了线性层和乘法操作,用于学习特征之间的交互关系。
模型9:AutoInt (Automatic Feature Interaction)
AutoInt将特征转换为嵌入向量,并应用一系列基于注意力机制的转换来处理这些嵌入向量。AutoInt能够自动学习特征之间的交互关系。
模型10: XGBoost
XGBoost是目前最流行的梯度提升决策树(Gradient Boosted Decision Trees)实现之一。它在集成学习中使用了梯度提升算法,能够有效地处理各种类型的问题。
实验对比
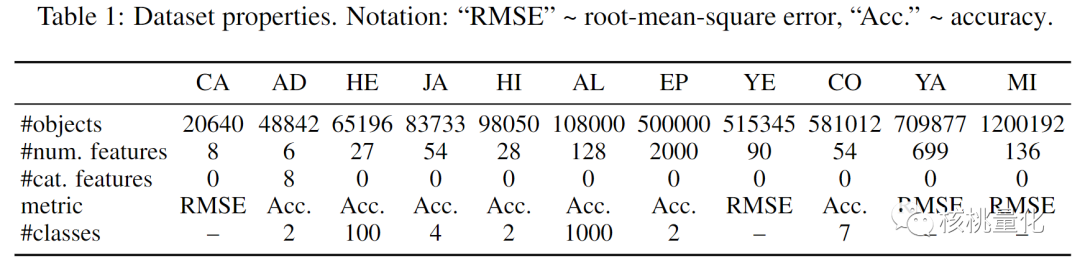
实验部分使用了11个多样化的公共数据集,每个数据集都进行训练-验证-测试集划分。这些数据集涵盖了不同领域的数据,包括房地产、收入估计、匿名数据、模拟物理粒子、图像、音频特征、森林特征和搜索查询等。表1对数据集的属性进行了总结。
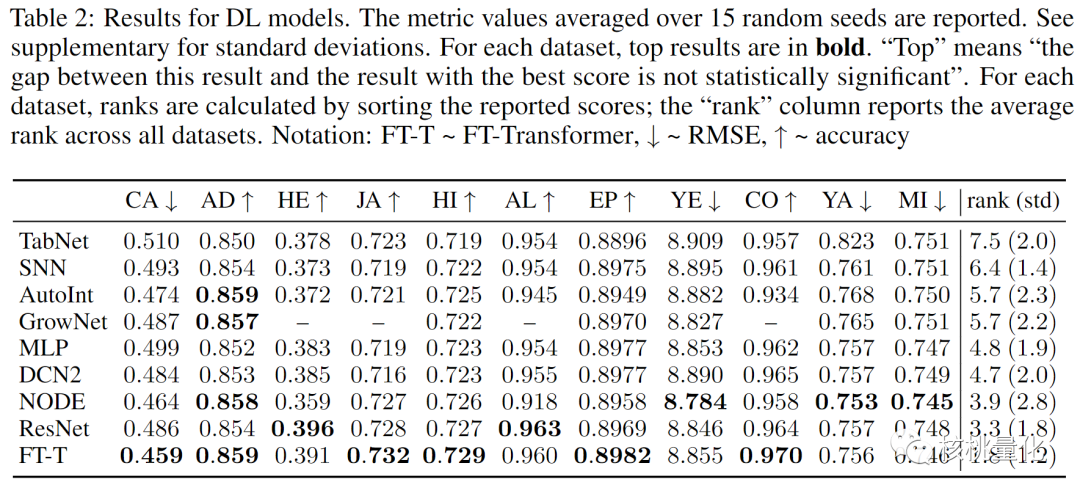
下面的实验结果现实ResNet是一个有效的基准模型,竞争对手无法持续超越它。在大多数任务中,FT-Transformer表现最佳,成为该任务的一种强大解决方案,即使与XGBoost和CatBosst等树模型相比仍然有更好的表现。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/111097
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!