
论文 | Meta contrastive label correction for financial time series
3.1 数据预处理
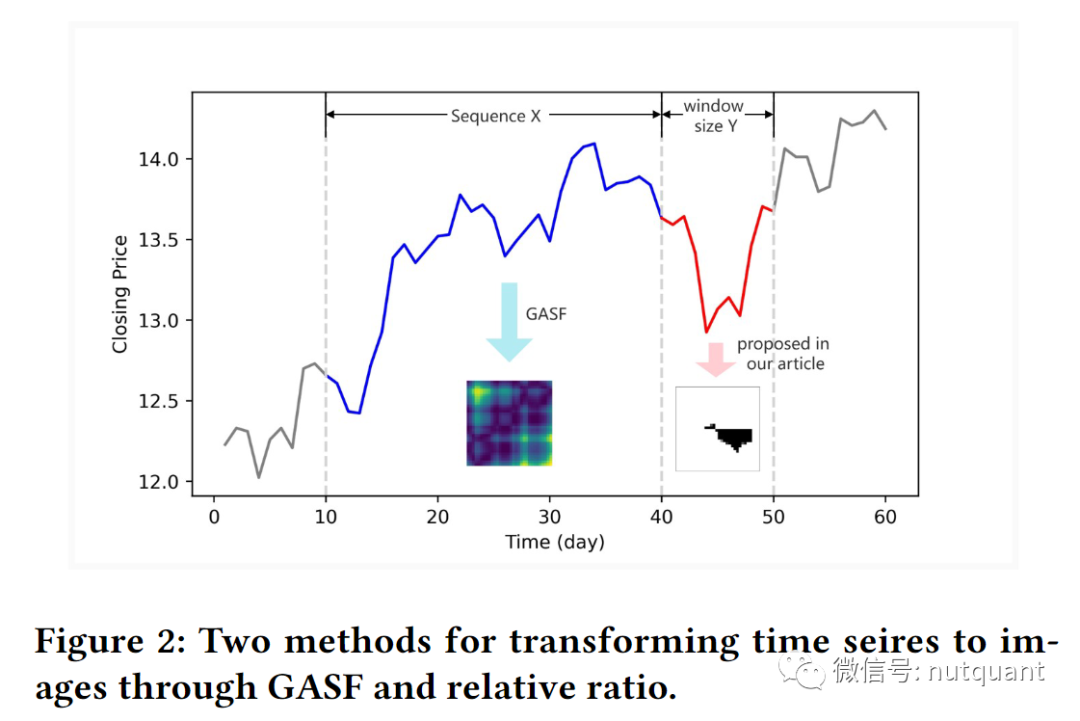

通常股票趋势预测会直接将历史价格数据作为训练样本X,后续一段时间的股票价格涨跌作为对应的标签Y。但是单变量时间序列很难反映数据之间潜在的共性和特征。本文X和Y分别进行了预处理,将其转换为图像。
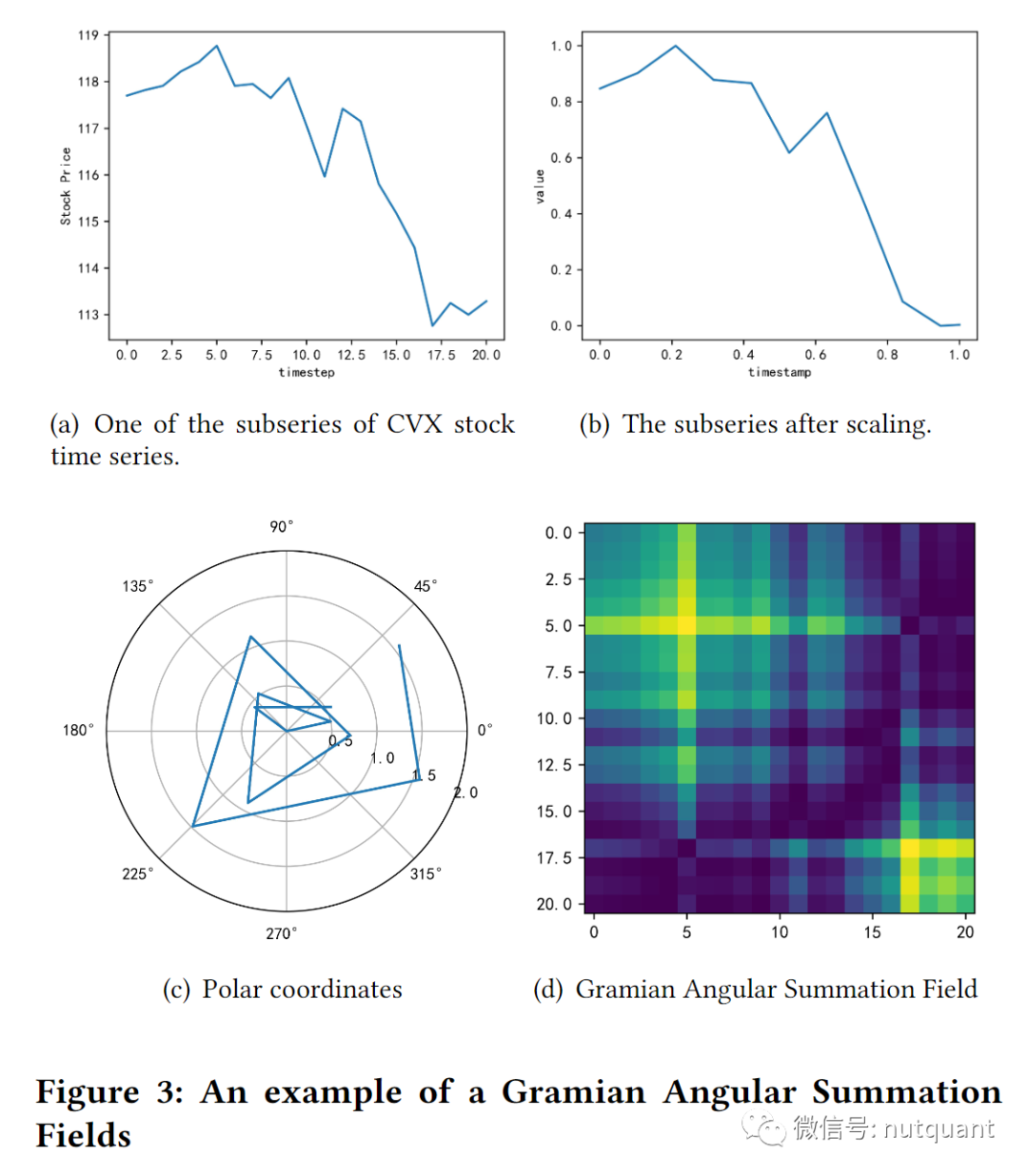
对X使用GASF方法进行转换为图像,具体包括下面3个步骤:
-
通过窗口滑动将原始时间序列拆分为多个片段。 -
用分段聚合近似方法对原始时间序列中的子序列进行预处理,以清除数据中的噪声,并用Min-MaxScaler方法将数据映射到[0,1]。 -
通过GASF方法将序列转换为图像。
使用相对比例构建Y的图像。假设数据集的样本中包括N个价格序列作为标注,分别计算后N-1个价格相对第一个价格的涨跌比例,然后通过绘制一个序列折线图并对折线图和Y轴之间进行着色。
上面的步骤科研将时间序列转换为图像,使用U-net作为编码器来再次提取基于时间信息的空间特征,以实现空间和时间信息的融合。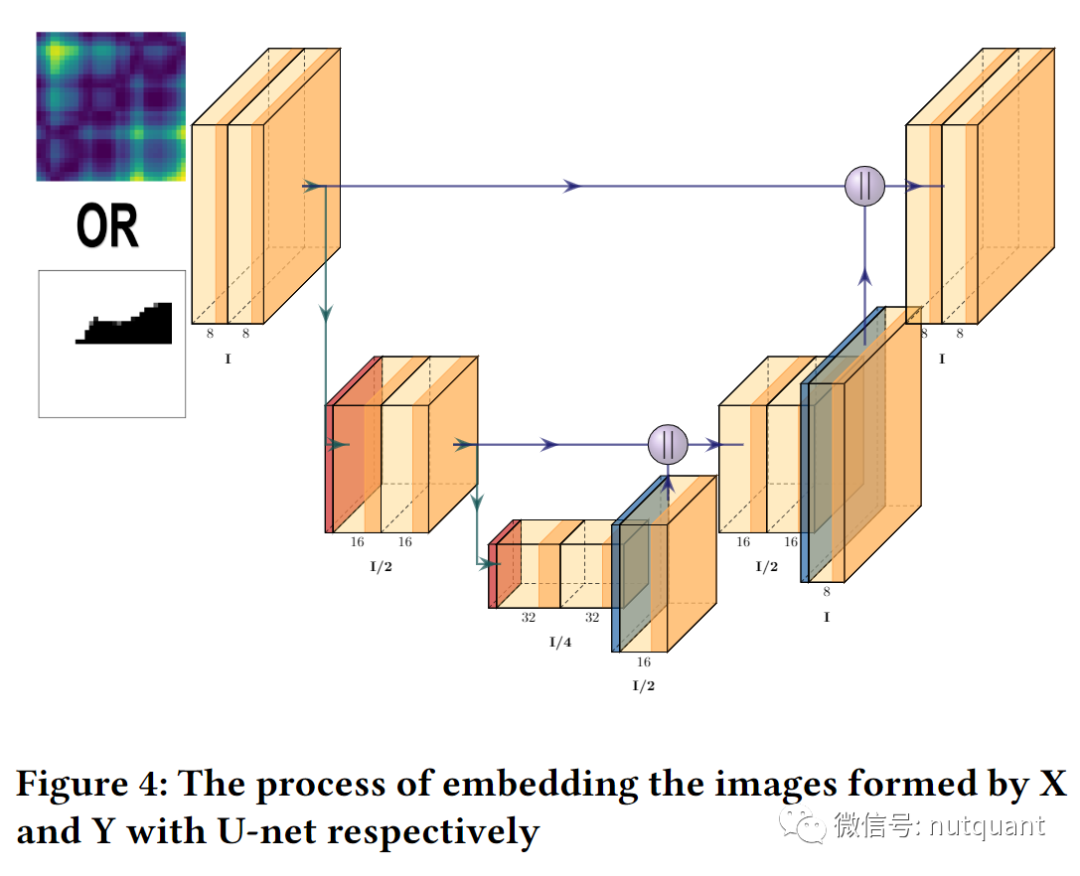
3.2 标签生成器
MCLC们需要两个神经网络,分别负责基于Y的图像信息进行标记和基于X的图像信息进行分类。从大量的嘈杂金融数据中选择干净数据是一项复杂的任务。本文采用手动标注方法来帮助我们选择少量干净数据。手动标注方法被选择为三重障碍方法,在获取到三重障碍方法的标签之后,我分别观察不同类别的图像数据的模式。然后使用通过模式得到的图像来计算与同一类别的相似度。最后选择具有最高相似度的前100个图像作为干净数据(𝒟_𝑐𝑙𝑒𝑎𝑛)。具体细节如下:
-
对于数据集中的所有样本使用以下公式构建手动标签,将数据集分为三个类别,其中v是预设的边界。
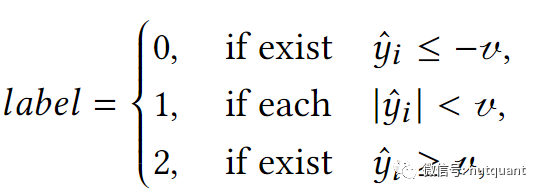
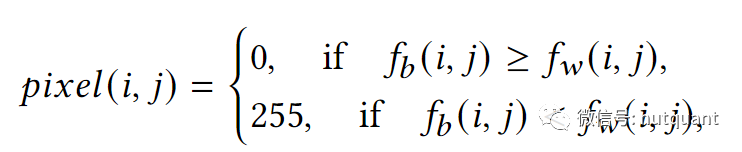
-
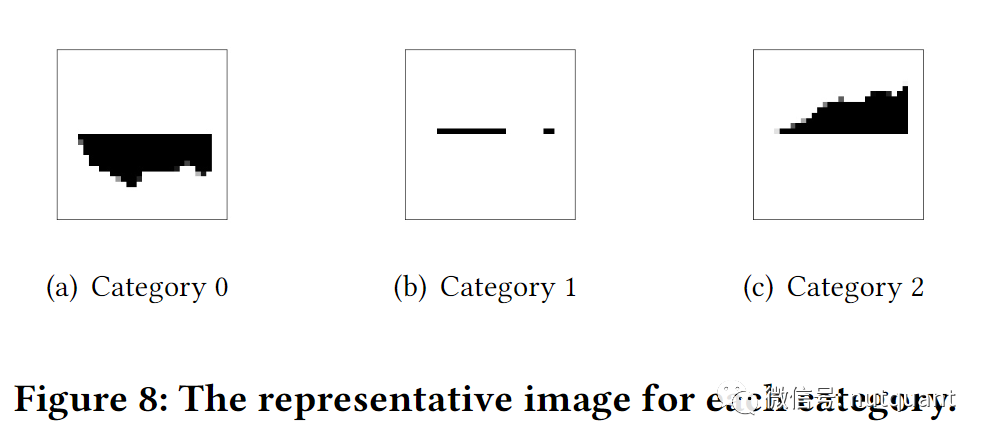
在每个类别中,计算样本的黑白图像与类别表示图片的欧式距离,选择最小距离的100个样本作为干净样本。
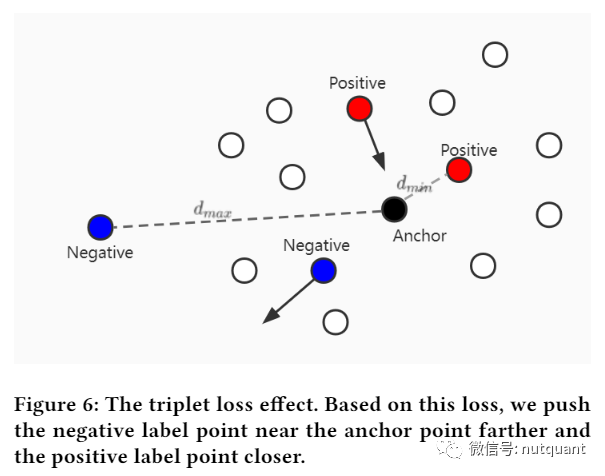
在训练标签生成器时,对于干净数据可以使用监督学习,随机选择 𝒟_𝑐𝑙𝑒𝑎𝑛中的一个数据作为锚点,使用与锚点具有不同标签的点作为负样本。对于未标记的𝒟𝑛𝑜𝑖𝑠𝑒 样本使用无监督学习在 ,在𝒟𝑛𝑜𝑖𝑠𝑒 中随机选择其中一个数据作为锚点,并计算它与 𝒟𝑐𝑙𝑒𝑎𝑛 中所有干净数据之间的距离,然后取最小距离的干净数据的标签作为正标签,取距离更远的干净数据的标签作为负标签。如果距离最大的干净数据的标签与距离最小的干净数据的标签相同,则选择第二大距离的标签作为负标签,以此类推。确定伪标签后,可以根据上述有监督策略构建三元组。使用三元组Loss计算样本之间的Loss。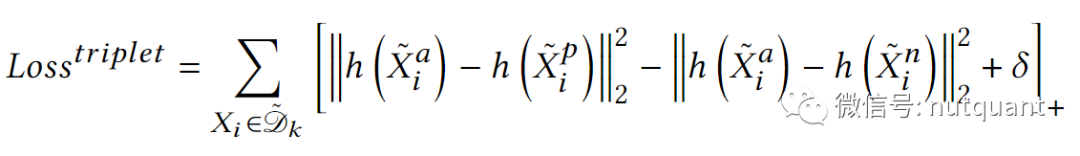
3.3 基于元学习的标签校准器
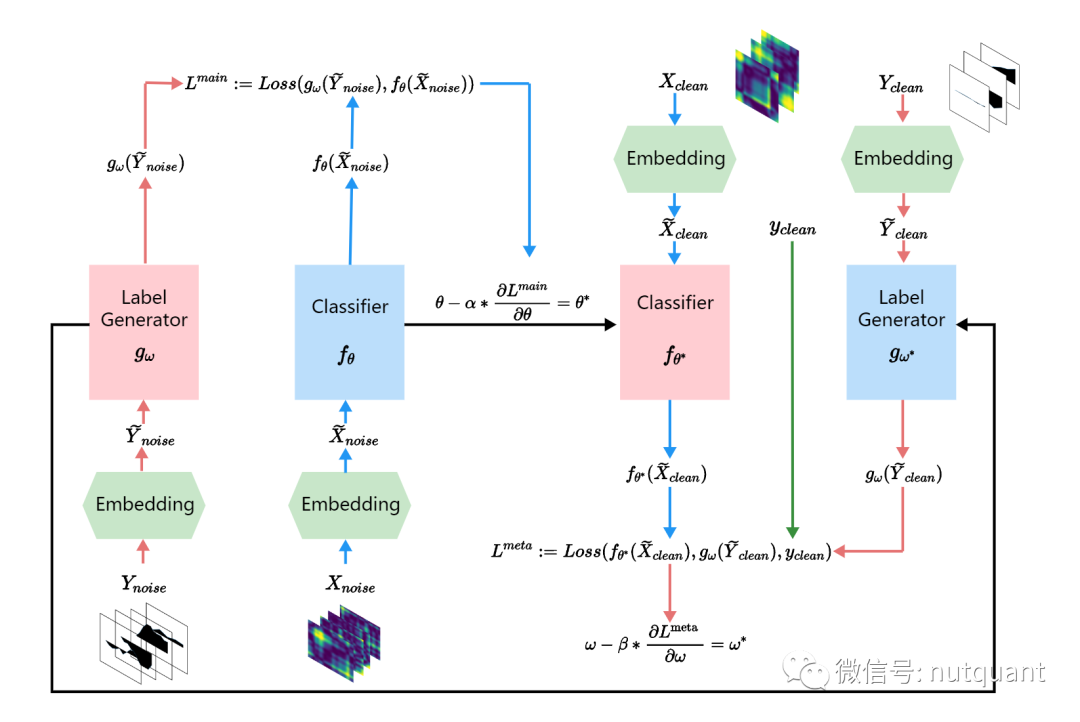
如上图所示,MCLC方法通过少量的有标记数据来生成和修正标签。首先,将无噪声的预处理数据输入到元模型中,生成无监督策略下的标签。然后,使用三元组正则化损失函数进行标签生成器的预训练,并使用交叉熵损失函数对分类器进行更新。接着,使用生成的标签来纠正主模型。内部循环中优化主模型参数,外部循环中优化元学习器参数,以实现互相博弈。该模型不仅可以自动标记基于时间序列图像信息,还能通过干净数据将信息馈送回元模型,从而帮助更新元学习器。
四 实验分析
本文实验部分收集了2007年至2017年期间5只股票的每日价格,如表1所示。历史价格长度为2053天。将特征(𝑋)序列长度设置为30,预测(𝑌)序列长度设置为10,构造样本,即每只股票有2014个样本。然后将数据集按比例分成训练集和测试集(约3:1的比例,1511×5个训练样本和503×5个测试样本)。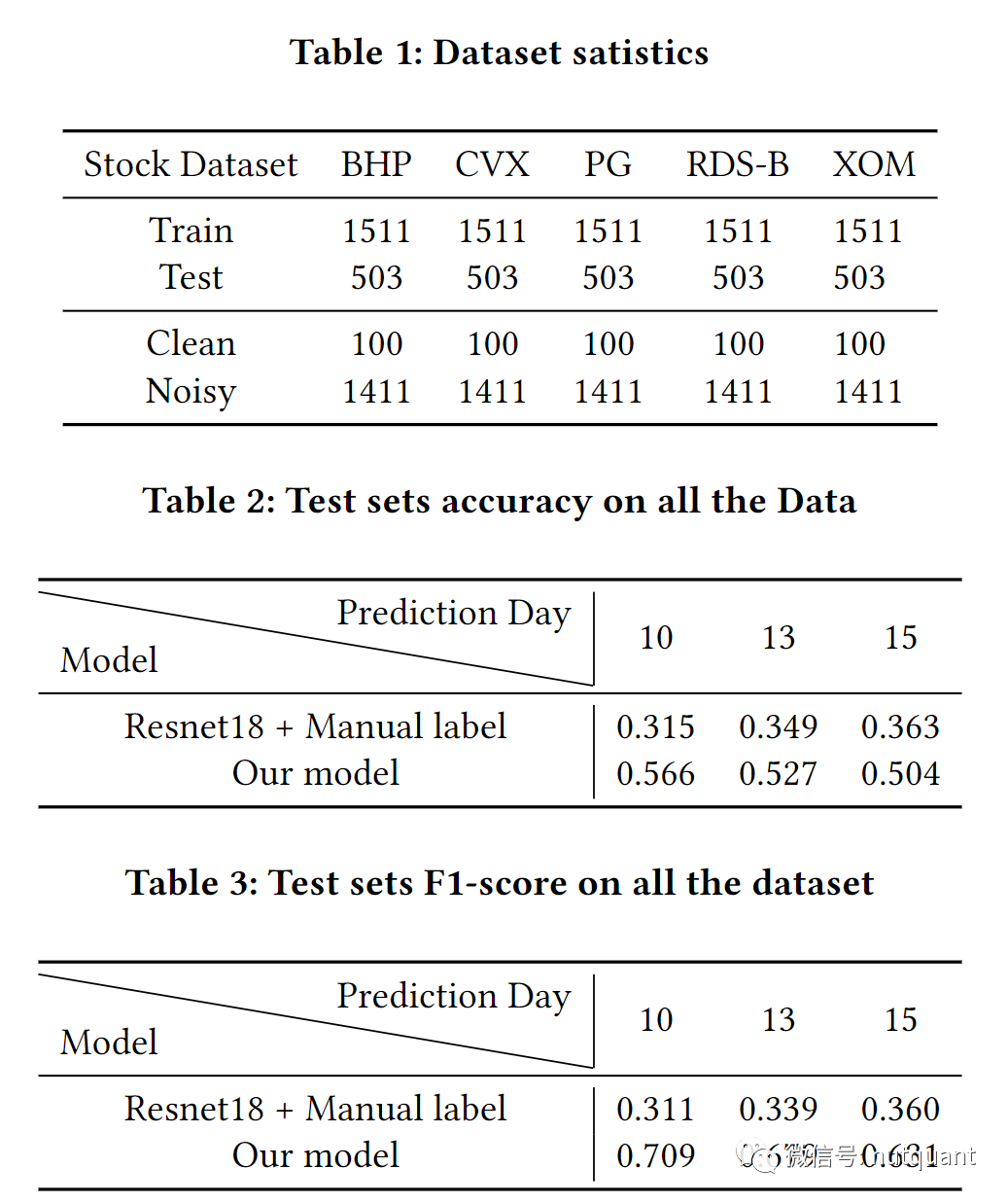
实验结果显示本文提出的方法在准确性上比基准模型提高了20%,在F1分数上增加了近100%。
五 总结展望
本文提出了一种改进传统手动标注方法的自动标注框架,基于元学习和对比学习。采用Gramian Angular Summation Field 和像素图将时间序列转换为图像数据,增强特征信息。同时,本文提出了三元组正则化损失函数,并在多任务下验证了所提出的MCLC模型在五个股票上的准确性和F1分数。结果表明,MCLC方法在金融股票趋势预测中表现优于基准模型。然而,算法中的一些人工超参数需要精确选择并具有更科学的基础。未来的工作将基于双层优化进行更多的理论分析,并深入研究不同权重分布导致这些惊人结果发生的原因。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/110967
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!