
关于投资,使用风险平价+动态现平衡肯定是可行的。
我们还需要加入更多的主动管理,比如有些指数,明显没有动量,或者一些择时指数是负向的,那我们直接把对应的指数权重置为0,甚至反过来,当一些指数的动量很强时,加大它的权重。
若是加上了择时,那风险平价是否还是必要的?
风险平价动态调仓的基础逻辑是:波动率有一定的平稳性,波动率大的时候,市场下行的概率大,所以波动率加大的应该降低仓位。但若是加上了动量、行业景气度这些逻辑,风险平价的最优计算似乎也失去了原本的意义?
还不如统一到一个“多因子”模型里去“学习”。
有时候,简单的反而是最好的。
有一个兄弟,真的做到极简:就是指数基金+动量轮动——骑最快的马。当然很多人觉得很好笑,现在想想还有一定的道理。动量策略本身就是一直有效的。另外直观好理解,纯右侧交易,持有感受也好。
若要把更多因子整合在一起,规则型的策略trick太多了,怎么看都像凑出来的,使用传统机器学习或者深度学习把多因子整合到一起倒是可行,最大的问题是,监督学习是需要标签的。这个标签把一个“多轮贯序决策”问题,变成一个个分类问题,根本就有一定的问题。看来看去,最前前途的,当属强化学习的范式,当然并不容易。
一个美好的愿景,应该是这样一个框架:
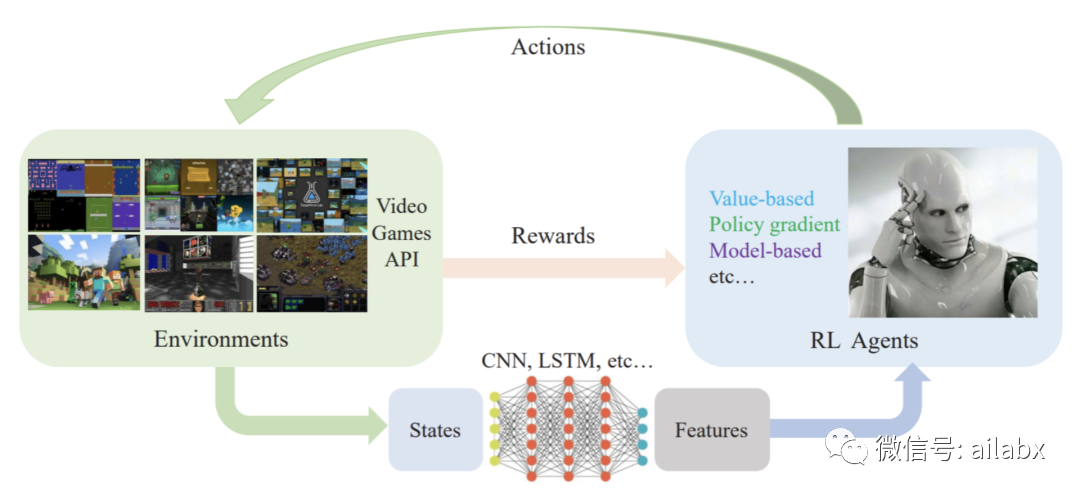

多因子,新增的数据、指标进来都可以纳入模型;有用更好,没用至少不会影响原有结果。
可以自适应市场环境,就是需要自我进化,而不是静态的。
可以按需要优化,比如夏普比,最大回撤等。
看起来强化学习是方向。
在原有的engine的基础上,我继承并拓展它成为强化学习环境:
from abc import ABC import gym import numpy as np from gym import spaces from engine.engine_runner import Engine class FinanceEnv(Engine, gym.Env, ABC): def __init__(self, symbols, names, fields, features): Engine.__init__(self, symbols, names, fields) gym.Env.__init__(self) # 正则化,和=1,长度就是组合里的证券数量 self.df_features = self.df_features[features] self.action_space = spaces.Box(low=0, high=1, shape=(len(symbols),)) self.observation_space = spaces.Box( low=-np.inf, high=np.inf, shape=(len(symbols), len(self.df_features.columns)), dtype=np.float64 ) print(self.action_space, self.observation_space) def reset(self): self.index = 0 self.curr_date = self.dates[self.index] df = self.df_features.loc[self.curr_date] print(df.values.shape) return df.values def step(self, actions): done = False if self.index >= len(self.dates) - 1: done = True return self.state, self.reward, done, {} self._update_bar() weights = self.softmax_normalization(actions) wts = {s: w for s, w in zip(self.symbols, weights)} self.acc.adjust_weights(wts) df = self.df_features.loc[self.dates[self.index], :] self.state = df.values self.reward = self.acc.cache_portfolio_mv[0] self._move_cursor() return self.state, self.reward, done, {} def softmax_normalization(self, actions): numerator = np.exp(actions) denominator = np.sum(np.exp(actions)) softmax_output = numerator / denominator return softmax_output if __name__ == '__main__': from stable_baselines3.common.env_checker import check_env from stable_baselines3 import A2C from engine.datafeed.dataloader import Dataloader symbols = ['399006.SZ', '000300.SH'] names = [] fields = [] features = [] # fields += ['$close/Ref($close,20) -1'] fields += ['Slope($close,20)'] names += ['mom'] features += ['mom'] env = FinanceEnv(symbols, names, fields, features) check_env(env) model = A2C("MlpPolicy", env) model.learn(total_timesteps=100000)
之前的文章是从零实现的,这次是整合进了engine里。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104187
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!