
今天基于基准指数做大类资产的“战略配置”。
基础框架是风险平价及期扩展。之前的文章说过,在投资里,为数不多的“确定性”, 一是市场长期向上;二是分散是免费的午餐。
如何分散。从股债20:80或者等级,到“均值-方差”的MVO模型,前沿资产从实操的角度,更倾向于配置风险。不是说风险平价比MVO更优,它更像一种近似,但由于MVO需要“预测”收益率且参数敏感性高,风险平价只需要协方差,计算量少且协方差具备一定的稳定性。
这种战略资产配置,完全是不预测的。若说有一个假设,就是协方差是相对稳定的,至少在最近的一段时间内是稳定的。——而这个假设是可以成立的。
从战术资产的角度,如果有些资产明显处于下行周期,那么可不把相关资产纳入配置或者降低权重。资产肯定在震荡,但在一个阶段是向上、横盘还是向下。
风险平价本质是控制风险,根据收益率的协方差,组合在一起可以降低波动。因为市场变化确实非常难预测。但若是短期内震荡下行的资产排除在外,可以在不提高波动的同时,提升收益率。这里还可以纳入“多因子”模型,给标的打分,短期预期下行的标的排除在外。
接着来说说具体工程上的实现,mongo存储基础数据,量价数据,因为涉及到增量更新,不能每次都通过api去调取。
全市场回测需要总体数据,所以,可以把mongo数据变成具体的dataframe存储到本地HDF5文件备用。尤其是回测,并不需要每天都更新,所以,这里增量更新是非必须的。

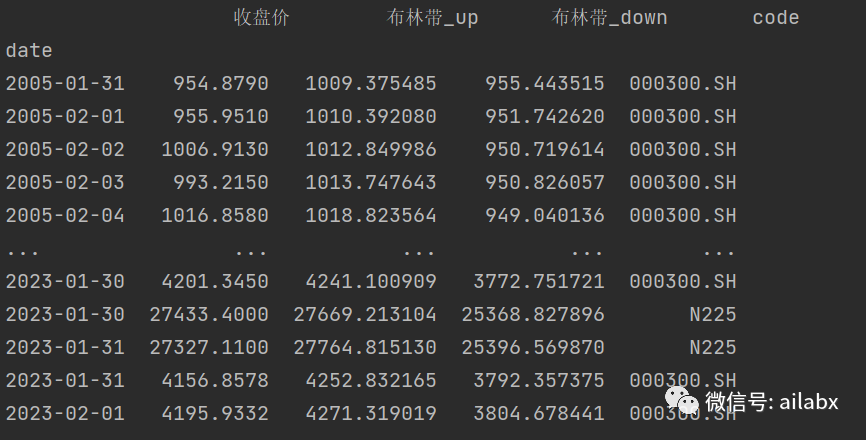
基于因子表达式计算因子:
# encoding:utf8 import pandas as pd from loguru import logger from quant_project.dataloader.expr.expr_mgr import ExprMgr from quant_project.dataloader.datafeed_hdf5 import Hdf5DataFeed from quant_project.config import DATA_DIR_HDF5_FEATURES class Dataloader: def __init__(self): self.expr = ExprMgr() self.feed = Hdf5DataFeed() def load_datas(self, symbols, names, fields, key='features'): dfs = self.load_dfs(symbols, names, fields) all = pd.concat(dfs) all.sort_index(ascending=True, inplace=True) all.dropna(inplace=True) with pd.HDFStore(DATA_DIR_HDF5_FEATURES.resolve()) as s: s[key] = all return all def load_from_cache(self, key): with pd.HDFStore(DATA_DIR_HDF5_FEATURES.resolve()) as store: key = 'features' if '/' + key in store.keys(): # 注意判断keys需要前面加“/” logger.info('从缓存中加载...') data = store[key] return data else: logger.error('{}不存在'.format(key)) return None def load_dfs(self, symbols, names, fields): dfs = [] for code in symbols: df = pd.DataFrame() for name, field in zip(names, fields): exp = self.expr.get_expression(field) # 这里可能返回多个序列 se = exp.load(code) if type(se) is pd.Series: df[name] = se if type(se) is tuple: for i in range(len(se)): df[name + '_' + se[i].name] = se[i] df['code'] = code dfs.append(df) return dfs if __name__ == '__main__': names = ['收盘价'] fields = ['$close'] fields += ['BBands($close)'] names += ['布林带'] loader = Dataloader() df_returns = loader.load_datas(['N225', '000300.SH'], names, fields) print(df_returns)
使用dagster计算因子:
@asset(description='指数因子') def index_features(index_code_list): names = ['Roc_1'] fields = ['$close/Ref($close,1) -1'] df = Dataloader().load_datas(index_code_list, names, fields) print(df) return df
得到所有指数的收益率数据:
df = Dataloader().load_datas(index_code_list, names, fields) df = df.pivot_table(columns='code', values='close', index=df.index) df.ffill(inplace=True) df = df.pct_change() df.dropna(inplace=True) print(df.corr())
计算核心指数的收益率以及相关系数。
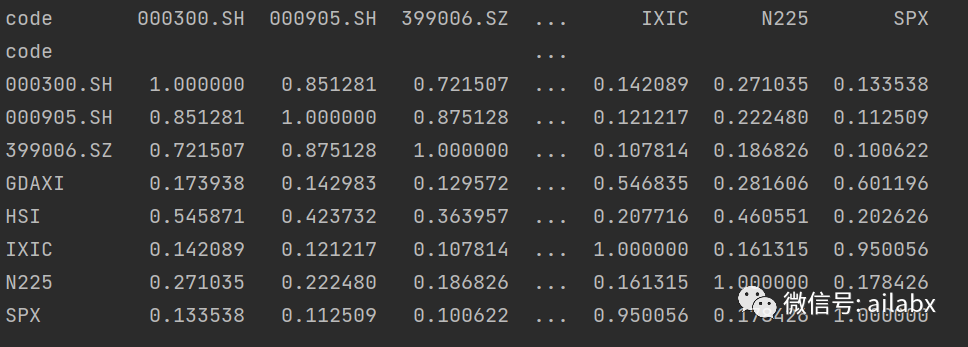
可以看出来,同一市场比如沪深300, 中证500,创业板的相关系数高,都在0.7以上,而与美股的相关性不到0.2,港股是0.5。
所以,这样的大类资产配置在一起,是可以显著降低波动的。
有个收益率数据,可以计算风险平价:
solution x: [11.0326 9.943 8.8493 13.5096 12.8522 13.3536 15.1819 15.2778]
lambda star: 13.9064
risk contributions: [12.5 12.5 12.5 12.5 12.5 12.5 12.5 12.5]
根据过往十年的协方差,可以得出,沪深300配置11%,纳指100配置15%等等。
按过往一年的协方差来计算:
solution x: [12.7872 13.2409 10.5217 14.2504 8.1779 9.8577 17.9687 13.1956]
lambda star: 0.9205
risk contributions: [12.5 12.5 12.5 12.5 12.5 12.5 12.5 12.5]
结果也没有差特别多,与等权的12.5%相比,有些多一点,有些少一点,最多的17%,最少的也有8%。
因此我们要配置多因子,比如某市场就在下行,那当期不配置这样一个多因子的逻辑。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104160
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!