
01 背景说明
今天讲讲遗传算法,之前提过几次,写过一些demo,但不系统。
这一周打算系统的谈一谈,做一个系列。
我们应用场景是期货,与本月咱们星球的目标(vnpy等开源框架的源码解读和整合)一致。
自动挖因子,大家第一个想到的框架应该就是gplearn。gplearn是基于遗传算法,基于数据生成符号表达,所以,可以应用于因子的自动化挖掘上。
传统量化里的均线,OBV,KDJ之类的技术分析,也是一种因子,它们主要是基于“经验”。优点是有成熟的计算包,比如talib,计算量不大,一般有直观的解释,规则容易构造。
缺点就是,规则如果不适用了,如何优化呢?以及多个规则如何有效融合呢?再者,如何把前沿机器学习技术应用起来,尤其是非线性的统计能力,传统的技术分析是做不到的。
当然,存在即合理,技术分析历经几百年,证明其生命力,我们会考虑整合,融合,取其精华。
02 遗传算法挖因子
基于已有数据随机生成新的因子,随后运用适应度函数剔除表现不好的因子,最终进化出具有较好投资效果的因子。
遗传规划中的复制、交叉、变异三种方法,可以对已有数据(父代)
通过函数运算进行组合,进而生成新的因子(子代)。在这之后,对于新生成的因子投资效果进行测试,并依据测试结果筛选因子作为下一次迭代的父代。依次进行循环,
以最终找到具有理想投资效果的因子。
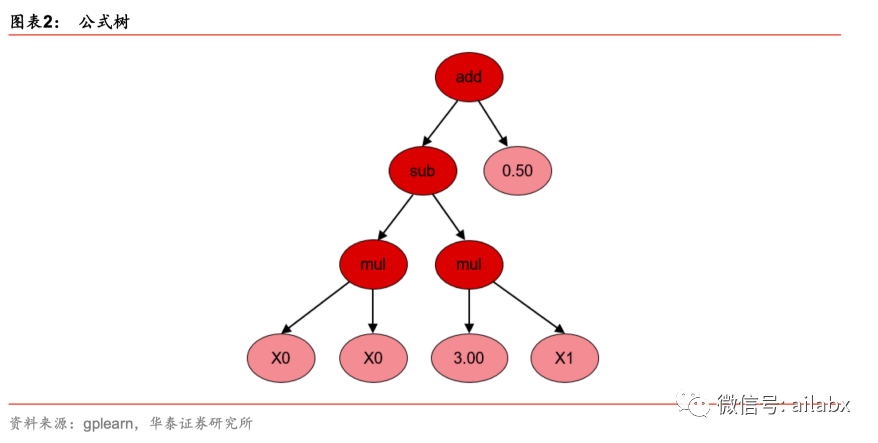
例如,假设有因子 𝑋0 和 𝑋1,我们需要基于这两个因子找到一个有效的因子 𝑦,该
因子可能的形式是:𝑦 = 𝑋2
0
− 3 × 𝑋1 + 0.5
表示为 S-expression 为:𝑦 = (+(−(×(𝑋0𝑋0
)(×3𝑋1
))0.5)
与我们的强化学习里的“逆波兰表达式”端到端因子挖掘框架:DeepAlphaGen V1.0代码发布,支持最新版本qlib有异曲同工的用处。
一个表达式,符号,常数以及特征,本质是一棵“二叉树”。

03 代码实证
实证基于 1 分钟级 IC 股指期货数据。(大家可以自行换成自己的数据)
取 2019 年 11 月 4 日至 2022 年 11 月 1 日共三年数据。
其中 2019 年 11 月
4 日至 2021 年 10 月 29 日为训练集,
2021 年 11 月 1 日至 2022 年 11 月 1 日为测试集。
我们的优化目标是“卡玛比率”:
def score_func_basic(y, y_pred, sample_weight): # 因子评价指标 try: _ = bt.run_(factor=y_pred) factor_ret = _['annualized_mean']/_['max_drawdown'] if _['max_drawdown'] != 0 else 0 # 可以把max_drawdown换成annualized_std except: factor_ret = 0 return factor_ret
回测结果:
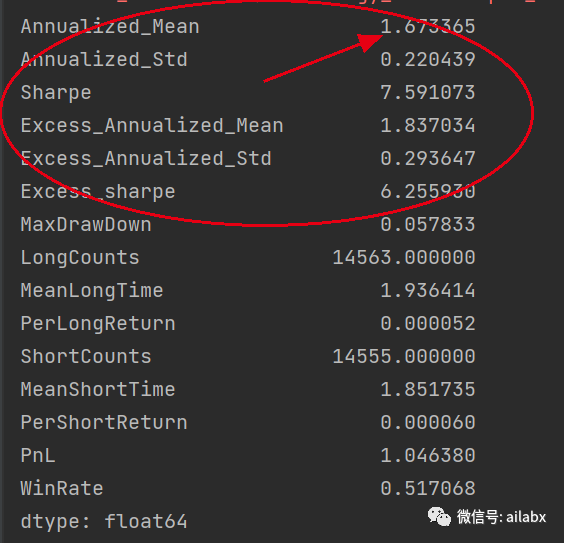

这里需要检视一下问题,但初步验证的因子挖掘的有效性。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103633
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!