
01 因子挖掘之因子表达式

昨天群里大家在讨论的问题,DeepAlphaGen里用的算子:
我前面的文章有总结,在Quantlab里复现WorldQuant101因子表达式引擎(代码+数据)
因子表达式无外乎四类:
一元直接计算:比如abs, log;
二元直接计算的:比如+,-,*,/比大小之类的;
一元rolling:比如ts_max, delta。
还有就是二元滑动:比如rolling_corr, rolling_std。
最后一种比较麻烦,Pandas原生不支持,或者说性能不好。
gip unary_ops = [Abs, Log] binary_ops = [Add, Sub, Mul, Div, Greater, Less] rolling_ops = [Ref, Mean, Sum, Std, Var, Max, Min, Med, Mad, Delta, WMA, EMA] rolling_binary_ops = [Cov, Corr]
就以最后一种为例:
def rolling_binary(cls, day): def _calc(a, b): n = len(a) return np.array([f'{cls.__name__}({a[i]},{b[i]},{day})' for i in range(n)]) return _calc
这里的计算函数,按最后一个维度展开,其实类似group_by_symbol。
因为数据是三维叠加的。
昨天在群里和星友们讨论的问题——qlib支持不支持截面,但有同学说DeepAlpha是支持的呀,应该它把所有数据搁到一起了。——不好意思,这种方式,仍然不支持截面,比如rank(a)
class RollingOperator(Operator): def __init__(self, operand: Union[Expression, float], delta_time: Union[int, DeltaTime]) -> None: self._operand = operand if isinstance(operand, Expression) else Constant(operand) if isinstance(delta_time, DeltaTime): delta_time = delta_time._delta_time self._delta_time = delta_time @classmethod def n_args(cls) -> int: return 2 @classmethod def category_type(cls) -> Type['Operator']: return RollingOperator def evaluate(self, data: StockData, period: slice = slice(0, 1)) -> Tensor: start = period.start - self._delta_time + 1 stop = period.stop # L: period length (requested time window length) # W: window length (dt for rolling) # S: stock count values = self._operand.evaluate(data, slice(start, stop)) # (L+W-1, S) values = values.unfold(0, self._delta_time, 1) # (L, S, W) return self._apply(values)
用三维矩阵来存储数据,不直观还容易出错。
因此,咱们的因子表达式使用group by symbol和 group by symbol统一的范式,清晰简单。
WorldQuant101的3号因子,只要使用rank(open)和rank(volume)求相关系数,结果都是None。
我检查过,如果计算correlation(open,volume)是没有问题的,说明计算函数correlation没有问题——这里怀疑是rank后数值太相近??。
# Alpha#3: (-1 * correlation(rank(open), rank(volume), 10)) se = calc_expr(df, expr='(-1 * correlation(rank(open), rank(volume), 10))') df['alpha_03'] = se
另外一个点,
series_left.rolling(10).corr(right)可以实现两个序列的滑动相关计算,但这里不支持自定义函数,比如计算rsrs, numpy的内置函数是可以的(这里有认知的同学,欢迎留言探讨)。
@calc_by_symbol def correlation(left: pd.Series, right: pd.Series, periods=20): #es: pd.Series = pd.Series(index=left.index) res = left.rolling(window=periods).corr(right) #left.rolling(window=periods).apply(func=func,right) res.loc[ np.isclose(left.rolling(periods, min_periods=1).std(), 0, atol=2e-05) | np.isclose(right.rolling(periods, min_periods=1).std(), 0, atol=2e-05) ] = np.nan return res
代码会持续在星球更新:
吾日三省吾身
什么算“躬身入局”?
做一款产品,一定要自己写代码才算吗?
这个显然不是,至少一款成功的产品,它的核心是用户需求与商业模式。
之所以问这个问题,是想起来,有一群比较成功的自媒体人,他们写的东西关于个人成长,比如彭小六。
他读了很多书以后,书的内容本身“并没有起作用”,而是开始教大家读书的方法。
还有另外一个兄弟,坚持学习外语,然后有所悟,他甚至不是教大家学外语,而是教大家“坚持的方法论”。
国际时事分析,对于多数人,就是茶余饭后的谈资,当然,你说做全球化的二级市场投资,关注一下黄金和国际油价的影响因素倒有可能。
芒格说:“宏观是我们必须承受的,而微观才是我们有所作为的”。
必须承受的大势,更应该了解并顺势而为。可以有所作为的微观,就是躬身入局。
所谓“抬头看天,低走走路”。
路只能自己走。
原创文章第515篇,专注“AI量化投资、世界运行的规律、个人成长与财富自由”。
从专业量化投资的角度,核心第一要务是因子。
因子挖掘,分为手工构造,机器挖掘,以及星球在尝试的GPT挖掘。
手工注定是低效的,尽管现在在很小小型私募里仍然有效。
我们重心放在后两者上。
gpt大家可以先看这几篇文章:
Quantlab3.9代码:内置大模型LLM因子挖掘,全A股数据源以及自带GUI界面
AlphaGPT v0.1发布后答疑——基于大模型的智能因子挖掘框架(代码)
机器挖掘当下也有两个方向:gplearn和强化学习。在这DeepAlpha我们都覆盖了:DeepAlpha通用因子挖掘:支持GPlearn遗传算法和深度强化学习挖掘因子(代码+数据下载)
但这个系统有个缺陷,基于qlib,另外它生成的因子还没有办法在Quantlab直接使用、回测。
Qlib的表达式系统有一个天生的缺陷,就是不支持截面因子!——因为它的表达式是基于一个个类,而类是针对单个symbol来计算的。截面计算,需要group by date。
在咱们代码目录AlphaGPT下,我带了WorldQuant101的因子表达式集合,给GPT few-shot学习用的。
大家仔细看下,满眼的rank,这就是典型的“截面函数”。——qlib不支持且无法支持!

Alpha#3: (-1 * correlation(rank(open), rank(volume), 10))
比如这个三号因子,就是10日开盘价与交易量的负相关性,在投资上,我们称之为“价量背离”。——一个很好理解的因子,它不是用价格和成交量的值来算相关系数,因为量纲不一样,取rank后,量纲就一致了。
因此rank是一个很通用的函数。
qlib只能算时序,不能算截面,就限制了它的表达式引擎不可用。
我们重定并改进了这个缺点。
咱们同样在dataloader下计算因子:
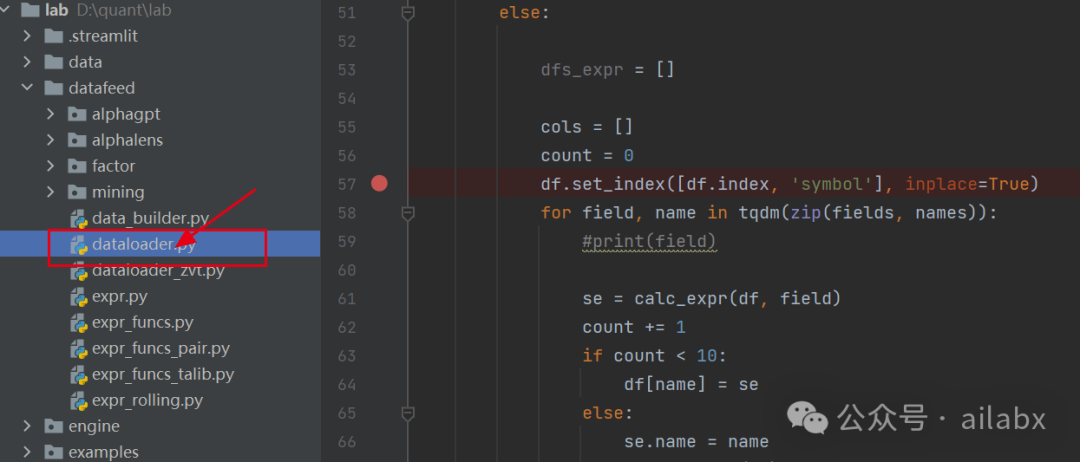
所有数据加载到一个DataFrame里后,选group_by_date,按日期分组,然后调用相应的函数,比如rank即可。
@calc_by_date def rank(se: pd.Series): ret = se.rank() return ret
我们后续会还原WorldQuant101里这100多个因子:
其实就是把常用函数实现就好了,比如 delay, delta, rank
import pandas as pd from .expr_utils import calc_by_symbol, calc_by_date @calc_by_symbol def delay(se: pd.Series, periods=5): return se.shift(periods=periods) @calc_by_date def delta(se: pd.Series, periods=20): se_result = se - se.shift(periods=periods) return se_result
测试代码如下:
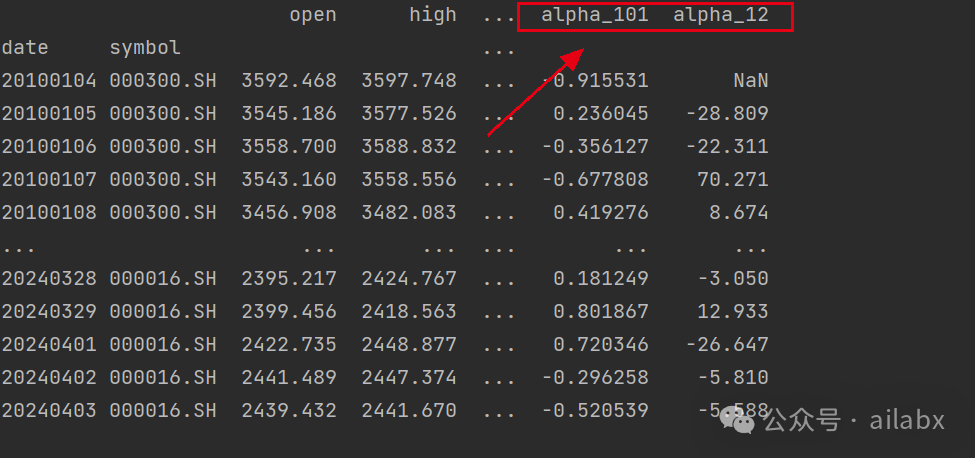
import numpy as np import pandas as pd from config import DATA_DIR from datafeed.expr import calc_expr sh300 = pd.read_csv(DATA_DIR.joinpath('quotes').joinpath('000300.SH.csv').resolve()) sh905 = pd.read_csv(DATA_DIR.joinpath('quotes').joinpath('000905.SH.csv').resolve()) sh016 = pd.read_csv(DATA_DIR.joinpath('quotes').joinpath('000016.SH.csv').resolve()) df = pd.concat([sh300, sh905, sh016]) df['date'] = df['date'].apply(lambda x: str(x)) df.dropna(inplace=True) df.set_index(['date', 'symbol'], inplace=True) df = df.loc[df.index.get_level_values('date') > '20100101', :] # Alpha#101: ((close - open) / ((high - low) + .001)) se = calc_expr(df, expr='((close - open) / ((high - low) + .001))') df['alpha_101'] = se # Alpha#12: (sign(delta(volume, 1)) * (-1 * delta(close, 1))) se = calc_expr(df, expr='(sign(delta(volume, 1)) * (-1 * delta(close, 1)))') df['alpha_12'] = se print(df)
计算两个alpha,比如简单:
测试代码在如下位置:
公用函数其实就那么一些,我们实现一下就好了(之前是qlib的标准,我会按WorldQuant101的标准重新刷一轮):
abs(x),log(x),sign(x) = standard definitions
分别为:取绝对值、对数值、正负号(正数返回1,负数返回-1)
rank(x) = 截面rank
股票的排名,数值从1-最后,若输入值含nan,则nan不参与排名,输出为股票对应排名的boolean值(排名所占总位数的百分比)
delay(x,d) = value of x d days ago
x变量d天之前的值
correlation(x,y,d) = time-serial correlation of x and y for the past d days
x和y两个变量d天以来的值的相关系数
covariance(x,y,d) = time-serial covariance of x and y for the past d days
x和y两个变量d天以来的值的协方差
scale(x,a) = rescaled x such that sum(abs(x))=a (the default is a=1)
将x中的值标准化,使x的绝对值的和为a,默认a=1
delta(x,d) = today’s value of x minus the value of x d days ago
指定enddate的x值减去d天之前的x值
signedpower(x,a) = x^a
x值的a次方,如果x为一个list或者series,则为x中每一个值的a次方
decay_linear(x,d) = weighted moving average over the past d days with linearly decaying weights d,d-1,…,1 (rescaled up to 1)
x中时间从最远到最近的值,分别乘权重d,d-1,…,1(权重要进行标准化,使和为1)再求和
ts_min(x,d) = time-series min over the past d days
x中d天内最小的值
ts_max(x,d) = time-series max over the past d days
x中d天内最大的值
ts_argmin(x,d) = which day ts_min(x,d) occurred on
ts_min(x,d)发生在d天中的第几天,最远的天为第一天
ts_argmax(x,d) = which day ts_max(x,d) occurred on
ts_max(x,d)发生在d天中的第几天,最远的天为第一天
ts_rank(x,d) = time-series rank in the past d days
x中,最后一天的值,在这d天中,排多少名,最后输出的名次为boolean值(即该名次占总排名数的百分比)
min(x,d) = ts_min(x,d)
当遇到min函数时,当ts_min函数处理——-注意!!实际上遇到min时,当min中的输入不是(x,d)而是(x,y)时,取x、y两个值中的最小值
max(x,d) = ts_max(x,d)
当遇到max函数时,当ts_max函数处理——注意!!实际上遇到max时,当max中的输入不是(x,d)而是(x,y)时,取x、y两个值中的最大值
sum(x,d) = time-series sum over the past d days
d天以来x值的和
product(x,d) = time-series product over the past d days
d天以来x值的乘积
stddev(x,d) = moving time series standard deviation over the past d days
d天以来,x值的标准差
从因子函数库的实现角度分析:
1、单时间序列计算:比如log, sign,abs这种,numpy都有函数,技术分析类的,可以直接调用ta-lib。
2、单时间序列的rolling, 比如shift, delta,使用pd.Series的rolling加apply即可。
3、多序列直接运算,比如加,减,金叉之类的。直接序列运算即可。
4、多序列多为双序列窗口计算,比如correlation等。这种计算有性能问题,我还在想办法,RSRS计算就是一个典型场景,计算high和low两个序列的rolling的beta。
后续这些因子引擎与gplearn和强化学习自动挖掘因子打通,形成一个“自动化的因子工厂”!
代码已经发布至星球:
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103412
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!