
继续讲因子挖掘:目前有三个方向:
一、“传统的” 以gplearn为代表的遗传算法;
二、强化学习驱动的深度学习框架;

三是gpt驱动的LLM生成因子框架。
这三类咱们都写过代码,不过接下来要做的事情,需要把三者整合到一个统一的框架下,并且与Quantlab回测引擎打通。因子可以直接形成策略。

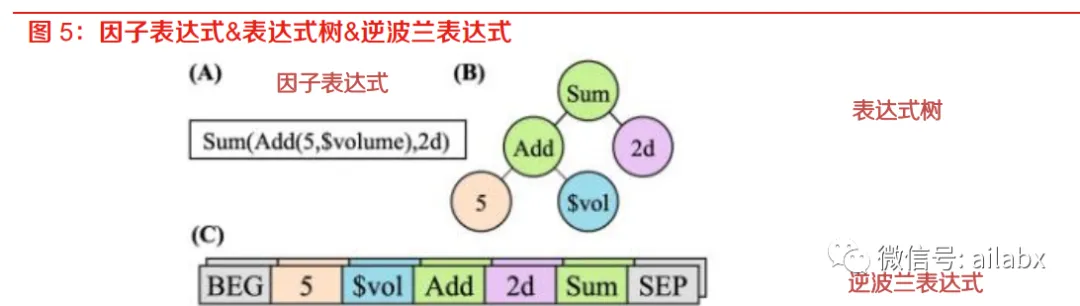
表达式由token组成,比如+,-,*,/这样的运算符,
还有自定义函数,比如ts_rank, ts_argmin,我们在wordquant101里实现了
很多这样的函数
强化学习每次生成一个token,如果遇到结束符号就中止。
形成一个表达式。
我们定义一系列的Token,包含开始,结束符,然后是函数集,运算符以及常数等。
from enum import IntEnum from typing import Type class FeatureType(IntEnum): OPEN = 0 CLOSE = 1 HIGH = 2 LOW = 3 VOLUME = 4 VWAP = 5 class SequenceIndicatorType(IntEnum): BEG = 0 SEP = 1 class Token: def __repr__(self): return str(self) class ConstantToken(Token): def __init__(self, constant: float) -> None: self.constant = constant def __str__(self): return str(self.constant) class DeltaTimeToken(Token): def __init__(self, delta_time: int) -> None: self.delta_time = delta_time def __str__(self): return str(self.delta_time) class FeatureToken(Token): def __init__(self, feature: FeatureType) -> None: self.feature = feature def __str__(self): return self.feature.name.lower() class OperatorToken(Token): def __init__(self, operator) -> None: self.operator = operator # 直接返回函数名(这里的operator就是函数名), 在函灵敏集的基础上,需要加上Add, Sub, Mul, Div加减乘出。 def __str__(self): return self.operator.__name__ class UnaryOperator(OperatorToken): def __init__(self, operator): super(UnaryOperator, self).__init__(operator) pass @classmethod def n_args(cls) -> int: return 1 class UnaryRollingOperator(OperatorToken): def __init__(self, operator): super(UnaryRollingOperator, self).__init__(operator) @classmethod def n_args(cls) -> int: return 2 class BinaryOperator(OperatorToken): def __init__(self, operator): super(BinaryOperator, self).__init__(operator) @classmethod def n_args(cls) -> int: return 2 class BinaryRollingOperator(OperatorToken): def __init__(self, operator): super(BinaryRollingOperator, self).__init__(operator) @classmethod def n_args(cls) -> int: return 3 class DeltaTime(Token): def __init__(self, delta: int): self.delta = delta class SequenceIndicatorToken(Token): def __init__(self, indicator: SequenceIndicatorType) -> None: self.indicator = indicator def __str__(self): return self.indicator.name BEG_TOKEN = SequenceIndicatorToken(SequenceIndicatorType.BEG) SEP_TOKEN = SequenceIndicatorToken(SequenceIndicatorType.SEP)
一棵逻辑树:(一棵“逆波兰”token构成的表达式树),对于构建有意义的表达式。
#from alphagen.data.expression import * from typing import List from datafeed.mining.tokens import * class ExpressionBuilder: stack: List[Token] def __init__(self): self.stack = [] def get_tree(self): if len(self.stack) == 1: return self.stack[0] else: raise InvalidExpressionException(f"Expected only one tree, got {len(self.stack)}") def add_token(self, token: Token): if not self.validate(token): raise InvalidExpressionException(f"Token {token} not allowed here, stack: {self.stack}.") if isinstance(token, OperatorToken): n_args: int = token.n_args() children = [] for _ in range(n_args): children.append(self.stack.pop()) self.stack.append(token(*reversed(children))) # type: ignore elif isinstance(token, ConstantToken): self.stack.append(ConstantToken(token.constant)) elif isinstance(token, DeltaTimeToken): self.stack.append(DeltaTime(token.delta_time)) elif isinstance(token, FeatureToken): self.stack.append(FeatureToken(token.feature)) else: assert False def is_valid(self) -> bool: return len(self.stack) == 1 and self.stack[0].is_featured def validate(self, token: Token) -> bool: if isinstance(token, OperatorToken): return self.validate_op(token) elif isinstance(token, DeltaTimeToken): return self.validate_dt() elif isinstance(token, ConstantToken): return self.validate_const() elif isinstance(token, FeatureToken): return self.validate_feature() else: assert False def validate_op(self, op) -> bool: if len(self.stack) < op.n_args(): return False #print(isinstance(op, UnaryOperator)) if isinstance(op, UnaryOperator): if not isinstance(self.stack[-1], FeatureToken): return False elif isinstance(op, BinaryOperator): if not self.stack[-1].is_featured and not self.stack[-2].is_featured: return False if (isinstance(self.stack[-1], DeltaTime) or isinstance(self.stack[-2], DeltaTime)): return False elif isinstance(op, UnaryRollingOperator): if not isinstance(self.stack[-1], DeltaTime): return False if not self.stack[-2].is_featured: return False elif isinstance(op, BinaryRollingOperator): if not isinstance(self.stack[-1], DeltaTime): return False if not self.stack[-2].is_featured or not self.stack[-3].is_featured: return False else: assert False return True def validate_dt(self) -> bool: return len(self.stack) > 0 and self.stack[-1].is_featured def validate_const(self) -> bool: return len(self.stack) == 0 or self.stack[-1].is_featured def validate_feature(self) -> bool: return not (len(self.stack) >= 1 and isinstance(self.stack[-1], DeltaTime)) class InvalidExpressionException(ValueError): pass if __name__ == '__main__': from datafeed.expr_functions import * tokens = [ FeatureToken(FeatureType.LOW), UnaryOperator(sign), DeltaTimeToken(-10), #OperatorToken(Ref), FeatureToken(FeatureType.HIGH), FeatureToken(FeatureType.CLOSE), OperatorToken(Div), OperatorToken(Add), ] builder = ExpressionBuilder() for token in tokens: print(token) builder.add_token(token) print(f'res: {str(builder.get_tree())}') print(f'ref: Add(Ref(Abs($low),-10),Div($high,$close))')
代码在如下位置:
这个表达式树就可以应用于强化学习生成一个个token,然后形成一个有效的表达式,计算ic值等。
大模型落地场景之AI量化投资
大横型如火如荼,与AI量化的关系也非常紧密,除了咱们之前聊天AlphaGPT之外,Quantlab3.8源码发布:整合AlphaGPT大模型自动因子挖掘以及zvt股票数据框架,这种智能问答在量化投研上应用也非常广。
AI智能投顾,第一性原理与kensho,这个被高盛和标普500收购的智能引擎,在现在大模型时代看来,就是个小儿科了。
我在星球同步了一篇最新的论文(后续会提供代码):
FinReport: 结合新闻语义信息的多因子模型显著提升预测准确性。

大模型相当于“大脑”。
很多时候,并不需要再训练一个“金融大脑”。因为它的知识储备已经非常充充分。我们需要的是场景,流程分解,prompts指令,提出精确的问题。
吾日三省吾身 之 “一人企业”与“超级个体”
十年前,我们聊“大众创业”,现在更多人聊“超级个体”。
现在大家都劝人吃饱饭,别创业,以稳为主。把炒股和创业列为高风险行当。
其实,都是脸谱化的误解。
从本质上看,超级个体与创业的逻辑一致。
创业并不是大家理解中的“All in”。大家对创业的刻板印象是,自己辞职,找钱,找人,租一个办公室,然后开会,讨论战略,开发产品,提供服务,建立商业模式。
这些只是形式罢了。
创业的本质就是给市场提供一种更多的产品或服务。以什么样的方式来组织生产,公司只是一种形式。
而超级个体是在当前技术,市场条件下,把自己“活成”一家公司。
你是自己的CEO,有战略部;你又是研发,有研发部;有市场部,运营部。
你说精力上顾不过来怎么办?
你拆解一下:一种是基础设施,已经不需要自己构建了。比如云服务,大模型,支付服务,流量平台,方便接入且成本不高。二是一些开发产品必须的技能,比如工程师——这种硬技能没有办法,如果你恰好是栈工程师,这就再好不过了,这种可以外包给另外的超级个体——以松散的方式组织生产。
完成比完美更加重要,方向比努力重要。
选择做对的事,有限的的事,专注而持续,先完成,形成反馈闭环。
简言之:作为超级个体,你专注你的专长,把以前需要以公司化来组织的事情,交给其的组织或超级个体。
这会带来什么来的好处呢?
灵活。——“一人企业”,就是以成本小到无法倒闭的方式来组织生产,创造价值。——本质还是“创业”。
不需要风投,不需要各种沟通,汇报,会议,管理。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103406
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!