
因子挖掘
传统券商研报里,多使用gplearn。
gplearn有一些天然的缺陷: 为了兼容类似sklearn的接口,失去了一些数活性,比如需要传入数据X, y,需要传入预定义的函数,不支持常数项,不支持多支股票挖掘等。
而deap可以完美解决这一切。
https://deap.readthedocs.io/en/master/
下面这段代码,按照咱们给定的函数集——只需要给出“函数名”即可,不需要真正实现这些函数,这样生成了表达式,直接用咱们的因子表达式引擎来计算即可,也deap无关。
import random
from deap_patch import * # noqa
from deap import base, creator, gp
from deap import tools
from add_ops import add_operators, add_factors, add_constants, RET_TYPE
def init_pset():
pset = gp.PrimitiveSetTyped("MAIN", [], RET_TYPE)
pset = add_constants(pset)
pset = add_operators(pset)
pset = add_factors(pset)
return pset
def init_creator(): # 可支持多目标优化 # TODO 必须元组,1表示找最大值,-1表示找最小值 FITNESS_WEIGHTS = (1.0, 1.0) creator.create("FitnessMulti", base.Fitness, weights=FITNESS_WEIGHTS) creator.create("Individual", gp.PrimitiveTree, fitness=creator.FitnessMulti) return creator def init_toolbox(creator): toolbox = base.Toolbox() pset = init_pset() toolbox.register("expr", gp.genHalfAndHalf, pset=pset, min_=2, max_=5) toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.expr) toolbox.register("population", tools.initRepeat, list, toolbox.individual) return toolbox random.seed(9527) creator = init_creator() toolbox = init_toolbox(creator) pop = toolbox.population(n=100) print(pop)
生成初代因子1000个:

我们预定义的函数集如下:
# TODO: 请在此文件中添加算子和因子 # TODO: 由于部分算子计算过慢,这里临时屏蔽了 import random class RET_TYPE: # 是什么不重要 # 只要addPrimitive中in_types, ret_type 与 PrimitiveSetTyped("MAIN", [], ret_type)中 # 这三种type对应即可 pass # 改个名,因为从polars_ta中默认提取的annotation是Expr # TODO 如果用使用其它库,这里可能要修改 Expr = RET_TYPE def _random_int_(): return random.choice([1, 3, 5, 10, 20, 40, 60]) def add_constants(pset): """添加常量""" # !!! 名字一定不能与其它名字重,上次与int一样,结果其它地方报错 [<class 'deap.gp.random_int'>] pset.addEphemeralConstant('_random_int_', _random_int_, int) return pset def add_operators_base(pset): """基础算子""" # 无法给一个算子定义多种类型,只好定义多个不同名算子,之后通过helper.py中的convert_inverse_prim修正 pset.addPrimitive(dummy, [Expr, Expr], Expr, name='fadd') pset.addPrimitive(dummy, [Expr, Expr], Expr, name='fsub') pset.addPrimitive(dummy, [Expr, Expr], Expr, name='fmul') pset.addPrimitive(dummy, [Expr, Expr], Expr, name='fdiv') pset.addPrimitive(dummy, [Expr, Expr], Expr, name='fmax') pset.addPrimitive(dummy, [Expr, Expr], Expr, name='fmin') pset.addPrimitive(dummy, [Expr, int], Expr, name='iadd') pset.addPrimitive(dummy, [Expr, int], Expr, name='isub') pset.addPrimitive(dummy, [Expr, int], Expr, name='imul') pset.addPrimitive(dummy, [Expr, int], Expr, name='idiv') # !!! max(x,1)这类表达式是合法的,但生成数量太多价值就低了,所以屏蔽 # pset.addPrimitive(dummy, [Expr, int], Expr, name='imax') # pset.addPrimitive(dummy, [Expr, int], Expr, name='imin') pset.addPrimitive(dummy, [Expr], Expr, name='log') pset.addPrimitive(dummy, [Expr], Expr, name='sign') pset.addPrimitive(dummy, [Expr], Expr, name='abs_') return pset def add_operators(pset): """添加算子""" pset = add_operators_base(pset) pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_delay') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_delta') # pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_arg_max') # pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_arg_min') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_max') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_min') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_sum') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_mean') # TODO 等待修复 # pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_decay_linear') # pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_product') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_std_dev') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_rank') # pset.addPrimitive(dummy, [Expr, Expr, int], Expr, name='ts_corr') # pset.addPrimitive(dummy, [Expr, Expr, int], Expr, name='ts_covariance') # TODO 其它的`primitive`,可以从`gp/primitives.py`按需复制过来 pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_scale') pset.addPrimitive(dummy, [Expr, int], Expr, name='ts_zscore') # TODO 时序IC时,不要添加`cs_`类算子 return pset def add_factors(pset): pset.addTerminal(1, Expr, name='OPEN') pset.addTerminal(1, Expr, name='HIGH') pset.addTerminal(1, Expr, name='LOW') pset.addTerminal(1, Expr, name='CLOSE') pset.addTerminal(1, Expr, name='VOLUME') # pset.addTerminal(1, Expr, name='AMOUNT') return pset def dummy(*args): # 由于生成后的表达计算已经被map和evaluate接管,所以这里并没有用到,可随便定义 print('dummy') return 1
deap仅负责对这些因子进行,复制,交叉,变异等操作,然后按照设定的fitness进行筛选即可,比如IC值。
这个变异过程,部分可以交给GPT来做,而不是deap来随机进化。这个后续咱们都会覆盖到。
吾日三省吾身
周末不带电脑回家,把自己空出来。
不写代码也不写文章,但思考不会停,这也很重要。
想清楚一件事情,AI量化投资如何做?之前想做无数种,尝试了很多种。
量化私募是为数不多的,可以做“一人企业”,个人英雄主义有效,可以做一辈子的事业。 没有圣杯,但可以持续进化。
可积累有复利。
不需要大规模协作。
直接面对市场,没有客户(自营的话),没有交付。
可攻可守。不需要大规模前期投入,
不需要厂房设备。(
策略上云)
规模受限于策略容量,其次就是资金规模。(私募从业(投研岗优先)的同学可加我,近期启动专项研讨)
昨天写在星球里的
这些点,我相信大家都认同,而且很多人也是有此期望,才开始了解量化,希望学习的。
之前我一度犹豫过,甚至还“劝退”身边的朋友,离开这个领域。
当时的核心逻辑是: 投资没有圣杯,没有一劳永逸的解决方案,做投资是可以赚钱,但与你打一份工没有太大的差别。若如此,就不符合“被动收入”的初心。
想来,被动收入这个概念有“误导”性。
这个世界有纯粹的被动收入嘛,有。比如大类资产配置的理财收入,比如房租等等。
其余更常见的,如很多自媒体聊的,写个专栏,出本书等等。
就拿出书来说,李笑来的例子是在教书的时候,写了两本书,一本是单词书,另一本是写作书。——长销且畅销的话,一份时间多次销售。很美好对不对。
但你仔细一想,不太对。
且不说,现在内容这很多,要写一本畅销书多不容易,长销就更难了。普通的畅销书,就算年销1万本——算很厉害了。每本版税3块的话,3万块钱/年。——这个真的能让你自由嘛。
李笑来真正自由是加密货币,然后形成自己的个人IP。
这个世界上有人擅长讲道理,也很深刻。但未必是他获得成功的路径。
或者说,没有人的成功是可以复制的。
成功的人,讲了一些普适的道理。——这些道理是对的,但这些只是成功的非必要且非充份条件。
不聊被动收入,聊长期复利。
你要做的事情,应该是有长期复利的。简单说,就是有积累。
比如阅读,锻炼身体,投资能力。
从这个角度出发,量化就是很值得学习和值得长期去帮的事情。主观交易可能积累得少,但量化是有可能的。
另外,是如何做的逻辑。
没有圣杯,那量化应该做什么?概念优势。
其实一个人的成功也是如此,没有什么路径一定带你走向成功,但成长就是在积累概率优势。你多做正概率的事情,哪天运气来了,你就成功了。如此而已。
学习和研究就是积累这个优质,然后等机会。
所以,我们应该构建一套交易体系。
确保资金安全的前提下,能发挥概率优势,市场与我们契合时,会赚得多,市场没有按照预期发展时,少亏或不亏(有限的,可承受的)。
有这样的交易体系,投资就是科学,不是赌博。
所以,后续星球的核心是建立: 对标前沿量化私募来构建交易体系。
AI量化
今天发布版本Quantlab 4.1:

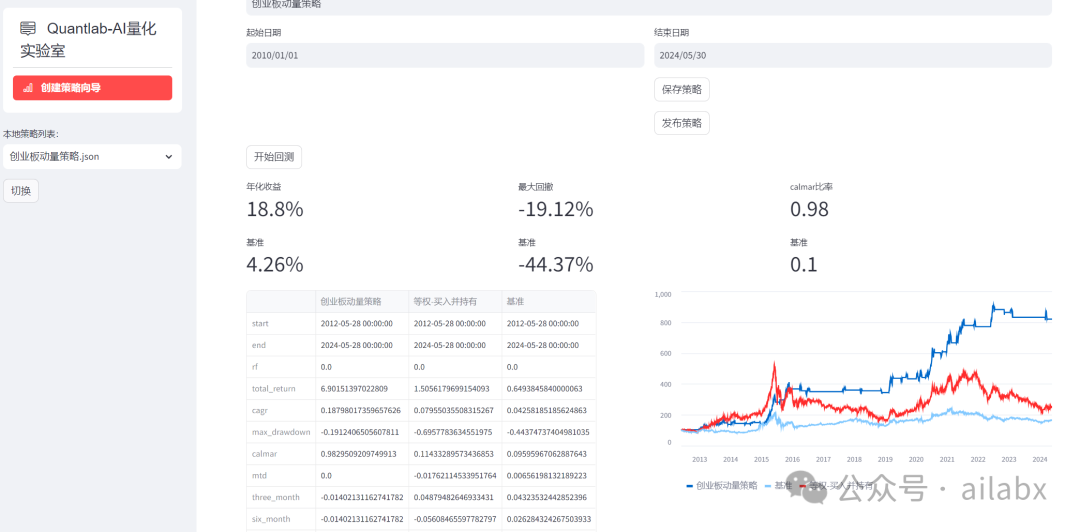
1、回测结果metrics显示
2、优化了Streamlit 的 session_state逻辑。
3、补充了一些策略:
3、修正已知bug
下周的工作做一下预告:
下周会正式重启因子挖掘,目前看可能deap比gplearn会更加合适一些。
gplearn不支持多因子截面数据,如果要使用,需要对框架进行大模型侵入式的改造。
然后就是多因子合成,比如lightGBM等等。
大致是这么个逻辑。
传统策略框架基本就是这样,大家可以自行开发自己的策略。
后续我们主要以AI量化策略为主了,因子挖掘,因子合成,机器模型这些。
吾日三省吾身
如何学习也是老生常谈。
昨天写了关于如何阅读,从书本里获得真正的知识。
总结起来,就是“寻找触动点”,“与自有认知体系产生关联”,“应用于实践“。可以写出来,或者讲给别人听等。
读书真是性价比最高,且随时随地都可以做的成长的事情。
有了认知体系,还有别一类叫”技能“的东西。
比如游泳,骑自行车,英语听力或口语。
国人多数英文阅读没啥问题,写作没啥需求。但就是学了这么多年,开不了口。
最近想把英语口语突破一下。
传统我们忽略了方法论,认为听力嘛,那就一直听。口语嘛,没有环境,怎么办,不能怪自己喽。
其实把一项技能分解开来,多数都是可以模拟训练的。
学吉他不是一首歌换一首歌,每天不停练。篮球运动员要提高成绩,也不是不停地上场比赛。
打基础的时候,都是分解动作。如同军训,左脚,右脚分解动作,都练到肌肉记忆后,再来整合。
口语也一样。
听说不分享,口语的应用场景肯定是与人交流。那么听就是基础。
你能听得懂,然后做出回应,有来有回,这就是交流。
听力训练:盲听,精听,复听,都是可以自己完成的。——在读书的时候,一直盲听,听不懂就跳过,看似每天晚上都在听,但进步很慢。直到在北大上学的时候,有过小一年的精听训练,听力有了很大进展,当然也没有特别刻意练习,但明显感觉到进步。
在这个基础上,我的口语训练计划就有了,不必报一个口语班(确实也没有时间),也不必找一个外教,陪练啥的。至少目前还不需要。
短视频平台就有大量这样的免费材料,先盲听,讲单词,句式。而且这些视频来自像《老友记》这样的情景剧,不枯燥且实用。——定一个计划,半年左右,上下班的时间把英文听力,口语提个可应用的水平。
”每新增一个技能,成功的概率就提升一倍“——史考特.亚当斯。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103370
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!