
咱们的目标是实盘。量化而言,就是把人工盯盘这种低效,无法积累的事情取代掉。
就算你是主观交易高手,需要在交易时间一直盯着盘,就算你可以稳定地赢利,以交易为生——这已经很不容易了。但这仍然是“打了一份工”,你是一个自由职业者罢了,它仍然不是“被动收入”。
如何把你的时间解放出来,做更有意义的事情。
这是量化系统的终极要义。
自动化的事情,部分智能化的事情,交给计算机做。
咱们要基于backtrader搭建实盘通道,我们从期货开始——从基础设施来讲,期货更加成熟,像股票量化接口,你需要与券商去沟通,有些还有资金门槛,另外股票默认不支持日内交易(你自己构建底仓另说),不支持做空——在下行市就没事可做等等。
实盘与回测最大的区别——数据准备方面,实盘的数据是实时进来的,而回测的数据是一次性加载上来的。
在实盘之前,还有一个状态,仿真模拟盘——所有的状态接近实盘,包括数据状态,这是实战中必备的一步。
SimNow是上海期货交易所全资子公司上期技术公司专为投资者打造的期货模拟仿真交易平台,为上海期货交易所投资者教育网认证的期货模拟仿真系统。该产品仿真各交易所的交易及结算规则研发,目前已经支持国内各期货交易所的商品期货业务。
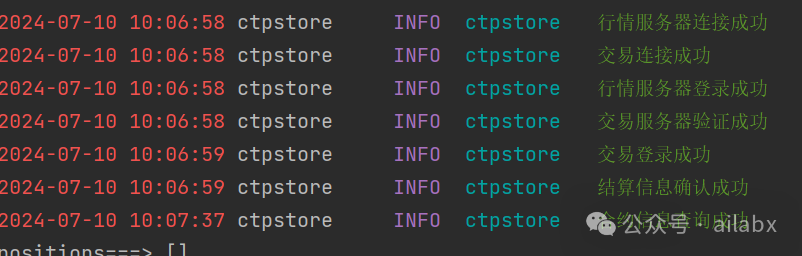
在SimNow上注册一个账号,非常简单,然后咱们就可以直接登录了:

backtrader的设计本身就支持实盘。
with open('./params.json', 'r') as f: ctp_setting = json.load(f) cerebro = bt.Cerebro(live=True) store = CTPStore(ctp_setting, debug=True) cerebro.addstrategy(SmaCross, store=store) #由于历史回填数据从akshare拿,最细1分钟bar,所以以下实盘也只接收1分钟bar #https://www.akshare.xyz/zh_CN/latest/data/futures/futures.html#id106 data0 = store.getdata(dataname='ag2112.SHFE', timeframe=bt.TimeFrame.Minutes, #注意符号必须带交易所代码。 num_init_backfill=100 if is_trading_period() else 0) #初始回填bar数,使用TEST服务器进行模拟实盘时,要设为0 data1 = store.getdata(dataname='rb2201.SHFE', timeframe=bt.TimeFrame.Minutes, #注意符号必须带交易所代码。 num_init_backfill=100 if is_trading_period() else 0) #初始回填bar数,使用TEST服务器进行模拟实盘时,要设为0 cerebro.adddata(data0) cerebro.adddata(data1) cerebro.run()
只是我们添加的data,需要按backtrader的datafeed来设计,通过CTP读取实时数据。
backtrader推荐的实盘模式是store,调用自己的datafeed和broker。这部分代码咱们明天展开:
吾日三省吾身
昨天我们分享的RSRS研报,在backtrader里计算了RSRS指标。
RSRS研报复现——年化21.5%,含RSRS标准分,右偏标准分的Backtrader指标计算(代码+数据)
值得注意的是,这两年RSRS指标效果并不好——这份代码,很好的演示了如何自定义,扩展backtrader的指标。
以前,关于过拟合,更多出现在机器学习相关的评价里,技术分析规则策略,我们很少提及。
其实,这里的参数或者值,本身也存在过拟合,或者说就是过拟合。
我们总能找到一些不错的参数,让过去的收益率或者夏普比率“显得”很漂亮,你会“惊讶地”发现,很快就失效了。
从这个意思上来讲,如何努力呢?
其实投资是讲求“模糊的正确”,赢的时候多赢,输的时候少输,你无法预测市场,但可以建立体系。
比如,一个箱子里有70个白球,30个黑球。你每次抓一个球,仍然是“随机”的,但你“赌”结果是白球的胜率肯定高,长期下来,你就能获得超额收益——如果别人以为箱子里白球与黑球数相等。
新手花太多时间,搞新指标,拟合参数,挖掘因子。
其实——稳定赢利的人,并不是“预测”能力有多厉害,没有人可以预测市场。
而是无论是什么情况下,他的系统可以自适应,亏的时候少,可以止损;赢的时候多赢,让利润奔跑。
继续Backtrader,今天讲讲指标扩展。
作为规则型的量化框架,指标是非常重要的元素,它是策略的基础。
我们来扩展一个经典的指标,RSRS——来自光大证券研报的“阻力支撑”指标。
尽管Backtrader内置140多个指标及运算符,外加talib的扩展,仍然不够,比如RSRS指标。
继承自bt.Indicator,lines里定义我们这个指标有几个line, params是参数,在init里做一次性的“向量”运算,在next里按元素计算。
Backtrader的指标继承自bt.Indicator。与实现策略类似,在next函数里计算指标的值。我们取high, low两个数据序列,每次取N个值,然后线性回归取斜率。
import backtrader as bt
import numpy as np
import statsmodels.api as sm
class RSRS(bt.Indicator):
lines = ('rsrs', 'R2')
params = (('N', 18), ('value', 5))
def __init__(self):
self.high = self.data.high
self.low = self.data.low def next(self): high_N = self.high.get(ago=0, size=self.p.N) low_N = self.low.get(ago=0, size=self.p.N) try: X = sm.add_constant(np.array(low_N)) model = sm.OLS(np.array(high_N), X) results = model.fit() self.lines.rsrs[0] = results.params[1] self.lines.R2[0] = results.rsquared except:
self.lines.rsrs[0] = 0
self.lines.R2[0] = 0
class RSRS_Norm(bt.Indicator):
lines = (‘rsrs_norm’,‘rsrs_r2’,‘beta_right’)
params = ((‘N’, 18), (‘M’, 600))
def __init__(self):
self.rsrs = RSRS(self.data)
self.lines.rsrs_norm = (self.rsrs – bt.ind.Average(self.rsrs, period=self.p.M))/bt.ind.StandardDeviation(self.rsrs, period= self.p.M)
self.lines.rsrs_r2 = self.lines.rsrs_norm * self.rsrs.R2
self.lines.beta_right = self.rsrs * self.lines.rsrs_r2


代码在如下位置:

代码下载:
基于大模型的可控文本生成
CTG(Controllable Text Generation)——在传统的文本生成的基础上,增加对生成文本一些属性、风格、关键信息等等的控制,从而使得生成的文本符合我们的某种预期。
现在大模型在生成文本方面,流畅度是没有问题的,而且天然支持多轮对话,意图识别。——但也有一个弊端,就是它仍然是计算下一个字符的概率,那么,对于内容的走向,我们是无法掌控,当然更无法进行微调改进。
比如data-to-text领域,我们希望大模型去查询数据库,然后用自然语言表达给用户。这在大数据领域,自动化报表,或者金融领域——量化投研都有非常有用。
咱们的目标是实盘。量化而言,就是把人工盯盘这种低效,无法积累的事情取代掉。
就算你是主观交易高手,需要在交易时间一直盯着盘,就算你可以稳定地赢利,以交易为生——这已经很不容易了。但这仍然是“打了一份工”,你是一个自由职业者罢了,它仍然不是“被动收入”。
如何把你的时间解放出来,做更有意义的事情。
这是量化系统的终极要义。
自动化的事情,部分智能化的事情,交给计算机做。
咱们要基于backtrader搭建实盘通道,我们从期货开始——从基础设施来讲,期货更加成熟,像股票量化接口,你需要与券商去沟通,有些还有资金门槛,另外股票默认不支持日内交易(你自己构建底仓另说),不支持做空——在下行市就没事可做等等。
实盘与回测最大的区别——数据准备方面,实盘的数据是实时进来的,而回测的数据是一次性加载上来的。
在实盘之前,还有一个状态,仿真模拟盘——所有的状态接近实盘,包括数据状态,这是实战中必备的一步。
SimNow是上海期货交易所全资子公司上期技术公司专为投资者打造的期货模拟仿真交易平台,为上海期货交易所投资者教育网认证的期货模拟仿真系统。该产品仿真各交易所的交易及结算规则研发,目前已经支持国内各期货交易所的商品期货业务。
在SimNow上注册一个账号,非常简单,然后咱们就可以直接登录了:
backtrader的设计本身就支持实盘。
with open('./params.json', 'r') as f: ctp_setting = json.load(f) cerebro = bt.Cerebro(live=True) store = CTPStore(ctp_setting, debug=True) cerebro.addstrategy(SmaCross, store=store) #由于历史回填数据从akshare拿,最细1分钟bar,所以以下实盘也只接收1分钟bar #https://www.akshare.xyz/zh_CN/latest/data/futures/futures.html#id106 data0 = store.getdata(dataname='ag2112.SHFE', timeframe=bt.TimeFrame.Minutes, #注意符号必须带交易所代码。 num_init_backfill=100 if is_trading_period() else 0) #初始回填bar数,使用TEST服务器进行模拟实盘时,要设为0 data1 = store.getdata(dataname='rb2201.SHFE', timeframe=bt.TimeFrame.Minutes, #注意符号必须带交易所代码。 num_init_backfill=100 if is_trading_period() else 0) #初始回填bar数,使用TEST服务器进行模拟实盘时,要设为0 cerebro.adddata(data0) cerebro.adddata(data1) cerebro.run()
只是我们添加的data,需要按backtrader的datafeed来设计,通过CTP读取实时数据。
backtrader推荐的实盘模式是store,调用自己的datafeed和broker。这部分代码咱们明天展开:
吾日三省吾身
昨天我们分享的RSRS研报,在backtrader里计算了RSRS指标。
RSRS研报复现——年化21.5%,含RSRS标准分,右偏标准分的Backtrader指标计算(代码+数据)
值得注意的是,这两年RSRS指标效果并不好——这份代码,很好的演示了如何自定义,扩展backtrader的指标。
以前,关于过拟合,更多出现在机器学习相关的评价里,技术分析规则策略,我们很少提及。
其实,这里的参数或者值,本身也存在过拟合,或者说就是过拟合。
我们总能找到一些不错的参数,让过去的收益率或者夏普比率“显得”很漂亮,你会“惊讶地”发现,很快就失效了。
从这个意思上来讲,如何努力呢?
其实投资是讲求“模糊的正确”,赢的时候多赢,输的时候少输,你无法预测市场,但可以建立体系。
比如,一个箱子里有70个白球,30个黑球。你每次抓一个球,仍然是“随机”的,但你“赌”结果是白球的胜率肯定高,长期下来,你就能获得超额收益——如果别人以为箱子里白球与黑球数相等。
新手花太多时间,搞新指标,拟合参数,挖掘因子。
其实——稳定赢利的人,并不是“预测”能力有多厉害,没有人可以预测市场。
而是无论是什么情况下,他的系统可以自适应,亏的时候少,可以止损;赢的时候多赢,让利润奔跑。
继续Backtrader,今天讲讲指标扩展。
作为规则型的量化框架,指标是非常重要的元素,它是策略的基础。
我们来扩展一个经典的指标,RSRS——来自光大证券研报的“阻力支撑”指标。
尽管Backtrader内置140多个指标及运算符,外加talib的扩展,仍然不够,比如RSRS指标。
继承自bt.Indicator,lines里定义我们这个指标有几个line, params是参数,在init里做一次性的“向量”运算,在next里按元素计算。
Backtrader的指标继承自bt.Indicator。与实现策略类似,在next函数里计算指标的值。我们取high, low两个数据序列,每次取N个值,然后线性回归取斜率。
import backtrader as bt
import numpy as np
import statsmodels.api as sm
class RSRS(bt.Indicator):
lines = ('rsrs', 'R2')
params = (('N', 18), ('value', 5))
def __init__(self):
self.high = self.data.high
self.low = self.data.low def next(self): high_N = self.high.get(ago=0, size=self.p.N) low_N = self.low.get(ago=0, size=self.p.N) try: X = sm.add_constant(np.array(low_N)) model = sm.OLS(np.array(high_N), X) results = model.fit() self.lines.rsrs[0] = results.params[1] self.lines.R2[0] = results.rsquared except:
self.lines.rsrs[0] = 0
self.lines.R2[0] = 0
class RSRS_Norm(bt.Indicator):
lines = (‘rsrs_norm’,‘rsrs_r2’,‘beta_right’)
params = ((‘N’, 18), (‘M’, 600))
def __init__(self):
self.rsrs = RSRS(self.data)
self.lines.rsrs_norm = (self.rsrs – bt.ind.Average(self.rsrs, period=self.p.M))/bt.ind.StandardDeviation(self.rsrs, period= self.p.M)
self.lines.rsrs_r2 = self.lines.rsrs_norm * self.rsrs.R2
self.lines.beta_right = self.rsrs * self.lines.rsrs_r2
代码在如下位置:
基于大模型的可控文本生成
CTG(Controllable Text Generation)——在传统的文本生成的基础上,增加对生成文本一些属性、风格、关键信息等等的控制,从而使得生成的文本符合我们的某种预期。
现在大模型在生成文本方面,流畅度是没有问题的,而且天然支持多轮对话,意图识别。——但也有一个弊端,就是它仍然是计算下一个字符的概率,那么,对于内容的走向,我们是无法掌控,当然更无法进行微调改进。
比如data-to-text领域,我们希望大模型去查询数据库,然后用自然语言表达给用户。这在大数据领域,自动化报表,或者金融领域——量化投研都有非常有用。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103210
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!