
想”以交易为生“,基础设施很重要。
现在开源框架比较多,我几乎读过市面上所有开源框架的代码,了解其设计理念与使用细节。
从选型上讲,兼容实盘与回测,尤其是策略可以”一键切换到实盘“,这个很重要。另外一点也很关键,就是开发策略效率要高。
传统从实盘起家的框架,往往暴露很多实盘细节,让新手不知所措。而很多量化框架,只关心回测,忽略了上实盘的诉求。
兼容二者而言,目前个人偏向的选型是backtrader。
当然,我会整合qlib的因子表达式,以及它的topK因子轮动算法。
这样就兼顾了传统规则量化、机器学习多因子智能量化,回测效率与实盘。
我们来看下如何封装:
首先,继承bt.strategy——这是一个常规的封装,notify_order, notify_trade这样的”模板“代码。后续传统的backtrader策略,直接继承StrategyBase即可。
class StrategyBase(bt.Strategy):
def log(self, txt, dt=None):
dt = dt or self.datas[0].datetime.date(0)
logger.info('%s, %s' % (dt.isoformat(), txt))
# 取当前的日期 def get_current_dt(self): # print(self.datas[0].datetime) dt = self.datas[0].datetime.date(0).strftime('%Y-%m-%d') # print(dt) return dt # 取当前持仓的data列表 def get_current_holding_datas(self): holdings = [] for data in self.datas: if self.getposition(data).size > 0: holdings.append(data) return holdings # 打印订单日志 def notify_order(self, order): order_status = ['Created', 'Submitted', 'Accepted', 'Partial', 'Completed', 'Canceled', 'Expired', 'Margin', 'Rejected'] # 未被处理的订单 if order.status in [order.Submitted, order.Accepted]: return self.log('未处理订单:订单号:%.0f, 标的: %s, 状态状态: %s' % (order.ref, order.data._name, order_status[order.status])) return # 已经处理的订单 if order.status in [order.Partial, order.Completed]: if order.isbuy(): self.log( 'BUY EXECUTED, 状态: %s, 订单号:%.0f, 标的: %s, 数量: %.2f, 价格: %.2f, 成本: %.2f, 手续费 %.2f' % (order_status[order.status], # 订单状态 order.ref, # 订单编号 order.data._name, # 股票名称 order.executed.size, # 成交量 order.executed.price, # 成交价 order.executed.value, # 成交额 order.executed.comm)) # 佣金 else: # Sell self.log( 'SELL EXECUTED, status: %s, ref:%.0f, name: %s, Size: %.2f, Price: %.2f, Cost: %.2f, Comm %.2f' % (order_status[order.status], order.ref, order.data._name, order.executed.size, order.executed.price, order.executed.value, order.executed.comm)) elif order.status in [order.Canceled, order.Margin, order.Rejected, order.Expired]: # order.Margin资金不足,订单无法成交 # 订单未完成 self.log('未完成订单,订单号:%.0f, 标的 : %s, 订单状态: %s' % ( order.ref, order.data._name, order_status[order.status])) self.order = None def notify_trade(self, trade):
如果要实现一个”买入并持有“的策略:
class StrategyBuyAndHold(StrategyBase): def __init__(self): pass def next(self): if self.position: return print('全仓买入') self.order_target_percent(self.data, 0.99)
但这是一支股票的情况,如果是多支,就需要 for data in self.datas,然后,循环判断,position为空,然后计算各自权重,再order_target_percent,这样进行调仓——代码繁琐,且容易出错!
我们来实现一个通用的”算子“策略:
class StrategyAlgo(StrategyBase): def __init__(self, algo_list, engine): self.now = None self.df_bar = None self.algos = algo_list self.df_data = engine.df_data self.temp = {} self.perm = {} self.index = -1 self.dates = list(self.df_data.index.unique()) def next(self): self.index += 1 self.now = self.dates[self.index] self.df_bar = self.df_data.loc[self.now] if type(self.df_bar) is pd.Series: self.df_bar = self.df_bar.to_frame().T self.df_bar.set_index('symbol', inplace=True) for algo in self.algos: if algo(self) is False: # 如果algo返回False,直接不运行 return
其实就是实现了bt.Strategy的next函数,这里会将当前的一些变量,比如index, now ,df_bar(类似很多线上平台的onbar函数传入的当前的bar,这里不需要一个个取因子,我们都预计算好),然后调用”算子“列表,完成策略。
这些代码在如下位置:
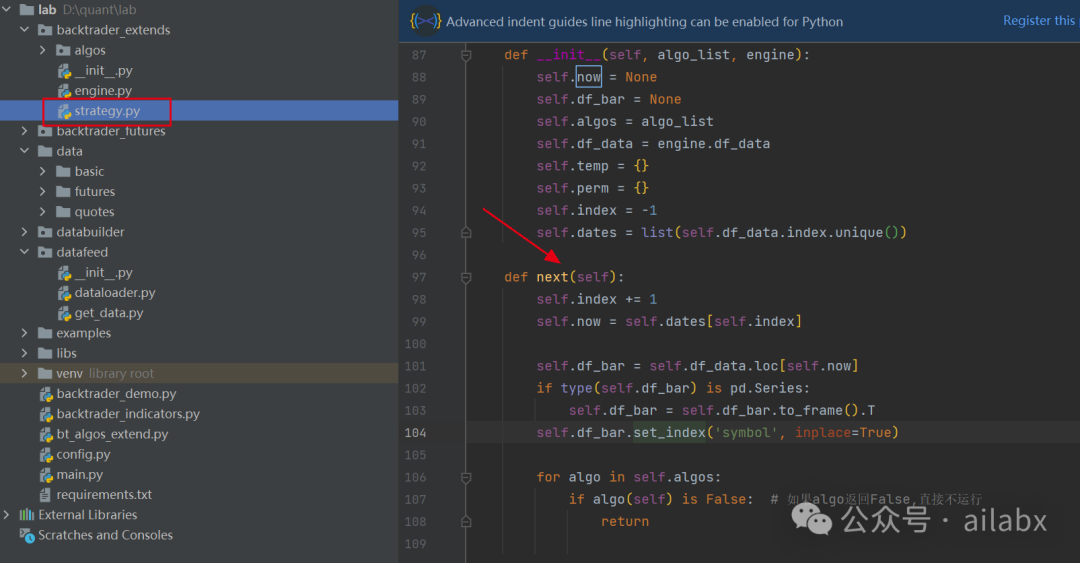

同样买入并持有策略——定义algo_list即可:
RunOnce——只运行一次;
SelectAll——选择所有股票;
就是把df_bar的index——当前有bar,也就是有数据的symbols都包含进来。
class SelectAll(Algo): def __call__(self, target): target.temp["selected"] = list(target.df_bar.index) return True
WeightEqually——等权分配;
按Selected数组,平均分配权重:
class WeightEqually(Algo): def __init__(self): super(WeightEqually, self).__init__() def __call__(self, target): selected = target.temp["selected"] n = len(selected) if n == 0: target.temp["weights"] = {} else: w = 1.0 / n target.temp["weights"] = {x: w for x in selected} return True
Rebalance——调仓。
class ReBalance(Algo): def __init__(self): super(ReBalance, self).__init__() def __call__(self, target): if "weights" not in target.temp: return True targets = target.temp["weights"] if type(targets) is pd.Series: targets = targets.to_dict() for data, w in targets.items(): target.order_target_percent(data, w*0.99) return True
拆来来看,Algo都非常简单:
engine.run_algo_strategy(algo_list=[
RunOnce(),
SelectAll(),
WeightEqually(),
Rebalance()
])
如果想开发因子轮动策略呢?加一个Algo即可,而且代码是完全可复用的:
SelectTopK:
class SelectTopK(Algo): def __init__(self, factor_name='order_by', K=1, drop_top_n=0, b_ascending=False): self.K = K self.drop_top_n = drop_top_n # 这算是一个魔改,就是把最强的N个弃掉,尤其动量指标,过尤不及。 self.factor_name = factor_name self.b_ascending = b_ascending def __call__(self, target): selected = None key = 'selected' if key in target.temp.keys(): selected = target['temp'][key] df_bar = target.bar_df factor_sorted = df_bar.sort_values(by=self.factor_name, ascending=self.b_ascending) symbols = factor_sorted.index if not selected: start = 0 if self.drop_top_n <= len(symbols): start = self.drop_top_n ordered = symbols[start: start + self.K] else: ordered = [] else: ordered = [] count = 0 for s in symbols: # 一定是当天有记录的 if s in selected: # 已经选择的symbols count += 1 if count >= self.drop_top_n: ordered.append(s) if len(ordered) >= self.K: break target.temp[key] = ordered return True
代码解读:
按order_by指定列,默认从大到小排序。如果前面的Algo有设置Selected,那么在Selected的基本上选择,否则在df_bar.index里选择,drop掉前N个,取之后的K个,这就是因子轮动的逻辑。
这里的因子可以由线性模型来合成,也可以机器学习来预测,总之会生成一个最终的排序列。
吾日三省吾身
最近刷的几本投资类的书。
埃尔德的《以交易为生》系列,还有欧尼斯特.陈的《算法交易》系列。
这两套书很有代表性。
埃尔德是传统主观技术派操盘手的代表,但它的理念还是比较好的,没有把技术分析说成玄学,而是秉持客观、科学、系统的角度讲。
埃尔德认为:心理,技术分析,资金管理,风险管理以及交易记录是非常重要的。——其实多数理念,在量化交易里同时适用。
只是量化里,心理因素可能不需要提到如此高的位置。
埃尔德提出的“三重滤网”,“动量系统”,也许现在未心能直接赚钱,但其背后的理念是值得学习和借鉴的。
还有他的2%的单笔最大损失风控,以及每月6%和最大损失风控,都给新手很好的指导理念。
当然埃尔德对于技术,或者说AI了解有限,因此,他只提及了“黑盒”,“灰盒”和“白盒”。白盒就是技术工具箱,这个是肯定需要的,灰盒可以交给用户自己配置及参数优化;完全黑盒肯定不可取,交易没有一劳永逸的事情。
反观欧尼斯特.陈。本身就物理学博士,有自己的量化资管公司。因此,他对于量化系统设计,多因子模型,时间序列分析,机器学习等做了系统的阐述。
不过,最令人印象深刻的还是最后一章——算法交易有助手身心健康。
交易是一个集数学、计算机科学和经济学的交叉学科,给我们可以一生做创造性研究的机会。——而且不需要太多人的协作或许可。
——你可能不需要上司,或者同事,不需要看别人脸色,不需要处理人情世故。
——专心做好你的创造性研究,然后行走江湖,忘情山水。
想”以交易为生“,基础设施很重要。
现在开源框架比较多,我几乎读过市面上所有开源框架的代码,了解其设计理念与使用细节。
从选型上讲,兼容实盘与回测,尤其是策略可以”一键切换到实盘“,这个很重要。另外一点也很关键,就是开发策略效率要高。
传统从实盘起家的框架,往往暴露很多实盘细节,让新手不知所措。而很多量化框架,只关心回测,忽略了上实盘的诉求。
兼容二者而言,目前个人偏向的选型是backtrader。
当然,我会整合qlib的因子表达式,以及它的topK因子轮动算法。
这样就兼顾了传统规则量化、机器学习多因子智能量化,回测效率与实盘。
我们来看下如何封装:
首先,继承bt.strategy——这是一个常规的封装,notify_order, notify_trade这样的”模板“代码。后续传统的backtrader策略,直接继承StrategyBase即可。
class StrategyBase(bt.Strategy):
def log(self, txt, dt=None):
dt = dt or self.datas[0].datetime.date(0)
logger.info('%s, %s' % (dt.isoformat(), txt))
# 取当前的日期 def get_current_dt(self): # print(self.datas[0].datetime) dt = self.datas[0].datetime.date(0).strftime('%Y-%m-%d') # print(dt) return dt # 取当前持仓的data列表 def get_current_holding_datas(self): holdings = [] for data in self.datas: if self.getposition(data).size > 0: holdings.append(data) return holdings # 打印订单日志 def notify_order(self, order): order_status = ['Created', 'Submitted', 'Accepted', 'Partial', 'Completed', 'Canceled', 'Expired', 'Margin', 'Rejected'] # 未被处理的订单 if order.status in [order.Submitted, order.Accepted]: return self.log('未处理订单:订单号:%.0f, 标的: %s, 状态状态: %s' % (order.ref, order.data._name, order_status[order.status])) return # 已经处理的订单 if order.status in [order.Partial, order.Completed]: if order.isbuy(): self.log( 'BUY EXECUTED, 状态: %s, 订单号:%.0f, 标的: %s, 数量: %.2f, 价格: %.2f, 成本: %.2f, 手续费 %.2f' % (order_status[order.status], # 订单状态 order.ref, # 订单编号 order.data._name, # 股票名称 order.executed.size, # 成交量 order.executed.price, # 成交价 order.executed.value, # 成交额 order.executed.comm)) # 佣金 else: # Sell self.log( 'SELL EXECUTED, status: %s, ref:%.0f, name: %s, Size: %.2f, Price: %.2f, Cost: %.2f, Comm %.2f' % (order_status[order.status], order.ref, order.data._name, order.executed.size, order.executed.price, order.executed.value, order.executed.comm)) elif order.status in [order.Canceled, order.Margin, order.Rejected, order.Expired]: # order.Margin资金不足,订单无法成交 # 订单未完成 self.log('未完成订单,订单号:%.0f, 标的 : %s, 订单状态: %s' % ( order.ref, order.data._name, order_status[order.status])) self.order = None def notify_trade(self, trade):
如果要实现一个”买入并持有“的策略:
class StrategyBuyAndHold(StrategyBase): def __init__(self): pass def next(self): if self.position: return print('全仓买入') self.order_target_percent(self.data, 0.99)
但这是一支股票的情况,如果是多支,就需要 for data in self.datas,然后,循环判断,position为空,然后计算各自权重,再order_target_percent,这样进行调仓——代码繁琐,且容易出错!
我们来实现一个通用的”算子“策略:
class StrategyAlgo(StrategyBase): def __init__(self, algo_list, engine): self.now = None self.df_bar = None self.algos = algo_list self.df_data = engine.df_data self.temp = {} self.perm = {} self.index = -1 self.dates = list(self.df_data.index.unique()) def next(self): self.index += 1 self.now = self.dates[self.index] self.df_bar = self.df_data.loc[self.now] if type(self.df_bar) is pd.Series: self.df_bar = self.df_bar.to_frame().T self.df_bar.set_index('symbol', inplace=True) for algo in self.algos: if algo(self) is False: # 如果algo返回False,直接不运行 return
其实就是实现了bt.Strategy的next函数,这里会将当前的一些变量,比如index, now ,df_bar(类似很多线上平台的onbar函数传入的当前的bar,这里不需要一个个取因子,我们都预计算好),然后调用”算子“列表,完成策略。
这些代码在如下位置:
同样买入并持有策略——定义algo_list即可:
RunOnce——只运行一次;
SelectAll——选择所有股票;
就是把df_bar的index——当前有bar,也就是有数据的symbols都包含进来。
class SelectAll(Algo): def __call__(self, target): target.temp["selected"] = list(target.df_bar.index) return True
WeightEqually——等权分配;
按Selected数组,平均分配权重:
class WeightEqually(Algo): def __init__(self): super(WeightEqually, self).__init__() def __call__(self, target): selected = target.temp["selected"] n = len(selected) if n == 0: target.temp["weights"] = {} else: w = 1.0 / n target.temp["weights"] = {x: w for x in selected} return True
Rebalance——调仓。
class ReBalance(Algo): def __init__(self): super(ReBalance, self).__init__() def __call__(self, target): if "weights" not in target.temp: return True targets = target.temp["weights"] if type(targets) is pd.Series: targets = targets.to_dict() for data, w in targets.items(): target.order_target_percent(data, w*0.99) return True
拆来来看,Algo都非常简单:
engine.run_algo_strategy(algo_list=[
RunOnce(),
SelectAll(),
WeightEqually(),
Rebalance()
])
如果想开发因子轮动策略呢?加一个Algo即可,而且代码是完全可复用的:
SelectTopK:
class SelectTopK(Algo): def __init__(self, factor_name='order_by', K=1, drop_top_n=0, b_ascending=False): self.K = K self.drop_top_n = drop_top_n # 这算是一个魔改,就是把最强的N个弃掉,尤其动量指标,过尤不及。 self.factor_name = factor_name self.b_ascending = b_ascending def __call__(self, target): selected = None key = 'selected' if key in target.temp.keys(): selected = target['temp'][key] df_bar = target.bar_df factor_sorted = df_bar.sort_values(by=self.factor_name, ascending=self.b_ascending) symbols = factor_sorted.index if not selected: start = 0 if self.drop_top_n <= len(symbols): start = self.drop_top_n ordered = symbols[start: start + self.K] else: ordered = [] else: ordered = [] count = 0 for s in symbols: # 一定是当天有记录的 if s in selected: # 已经选择的symbols count += 1 if count >= self.drop_top_n: ordered.append(s) if len(ordered) >= self.K: break target.temp[key] = ordered return True
代码解读:
按order_by指定列,默认从大到小排序。如果前面的Algo有设置Selected,那么在Selected的基本上选择,否则在df_bar.index里选择,drop掉前N个,取之后的K个,这就是因子轮动的逻辑。
这里的因子可以由线性模型来合成,也可以机器学习来预测,总之会生成一个最终的排序列。
吾日三省吾身
最近刷的几本投资类的书。
埃尔德的《以交易为生》系列,还有欧尼斯特.陈的《算法交易》系列。
这两套书很有代表性。
埃尔德是传统主观技术派操盘手的代表,但它的理念还是比较好的,没有把技术分析说成玄学,而是秉持客观、科学、系统的角度讲。
埃尔德认为:心理,技术分析,资金管理,风险管理以及交易记录是非常重要的。——其实多数理念,在量化交易里同时适用。
只是量化里,心理因素可能不需要提到如此高的位置。
埃尔德提出的“三重滤网”,“动量系统”,也许现在未心能直接赚钱,但其背后的理念是值得学习和借鉴的。
还有他的2%的单笔最大损失风控,以及每月6%和最大损失风控,都给新手很好的指导理念。
当然埃尔德对于技术,或者说AI了解有限,因此,他只提及了“黑盒”,“灰盒”和“白盒”。白盒就是技术工具箱,这个是肯定需要的,灰盒可以交给用户自己配置及参数优化;完全黑盒肯定不可取,交易没有一劳永逸的事情。
反观欧尼斯特.陈。本身就物理学博士,有自己的量化资管公司。因此,他对于量化系统设计,多因子模型,时间序列分析,机器学习等做了系统的阐述。
不过,最令人印象深刻的还是最后一章——算法交易有助手身心健康。
交易是一个集数学、计算机科学和经济学的交叉学科,给我们可以一生做创造性研究的机会。——而且不需要太多人的协作或许可。
——你可能不需要上司,或者同事,不需要看别人脸色,不需要处理人情世故。
——专心做好你的创造性研究,然后行走江湖,忘情山水。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103191
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!