
无论您是一名专业的数据专家想要提升自己的技能,还是一名新手兴奋地进入 Pandas 的世界,这些片段都将帮助您顺利进行旅程。它们就像您工具箱中的有用指南,解锁了这个多才多艺库所提供的所有出色功能。
每个代码片段都像是您工具箱中的一个实用工具,专门应对日常数据挑战。下面编程君带着大家一起看下这些 Pandas 代码,并改变我们处理数据分析方式!
01
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据集(例如,CSV 文件)
titanic_df = pd.read_csv(‘../data/titanic.csv’)
加载数据集是任何数据分析任务中的第一步。用您的数据集的实际文件路径或 URL 替换 ‘titanic.csv’。
02
# 显示关于数据集的基本信息
titanic_df.info()
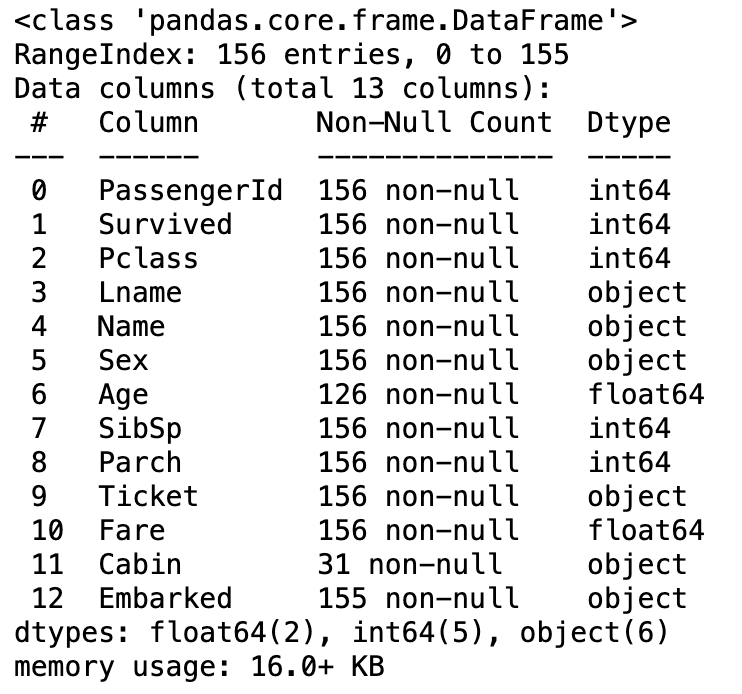

这提供了数据集的简洁摘要,包括每列中非空值的数量和数据类型。
03 # 显示数据集的前几行
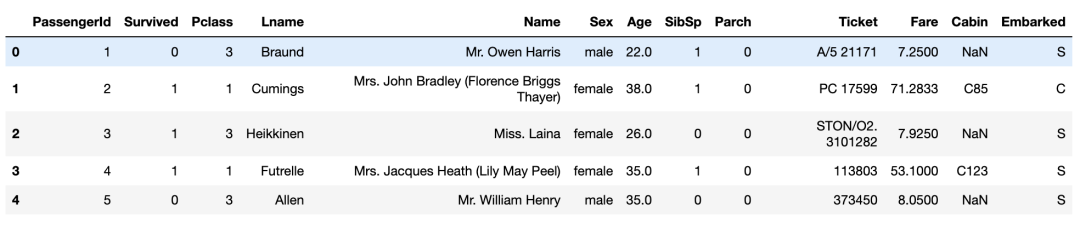
titanic_df.head()
这有助于您快速检查数据集的结构和内容。
04 # 生成描述性统计
titanic_df.describe(include = ‘all’)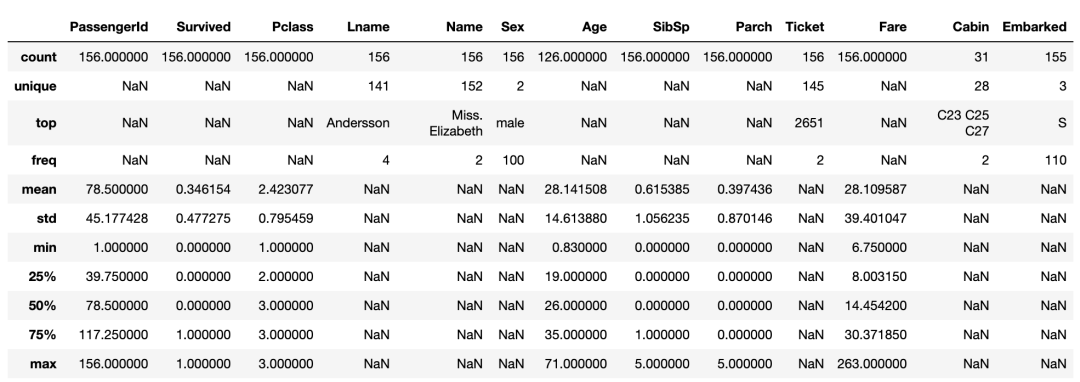
这为您提供了关键统计数据的概览,如均值、标准差和数值列的四分位数。写上“include = all”也会显示定性(字符串/对象变量)的摘要。
05
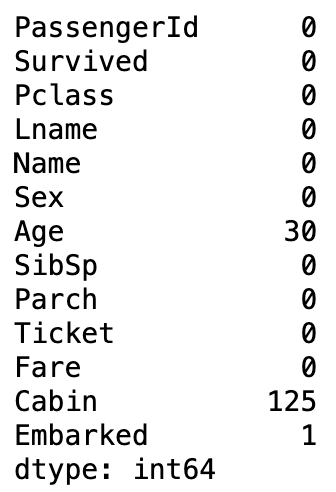
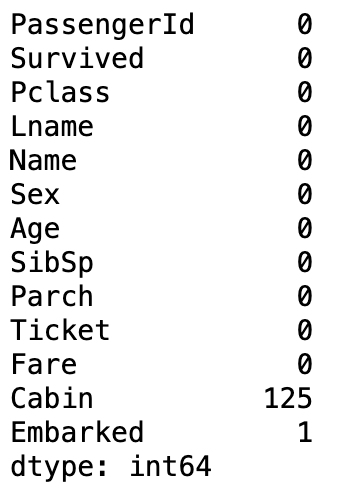
# 查找缺失值
titanic_df.isnull().sum()
# 使用特定值填充缺失值
titanic_df[‘Age’] = titanic_df[‘Age’].fillna(titanic_df[‘Age’].mean())
titanic_df.isnull().sum()
06
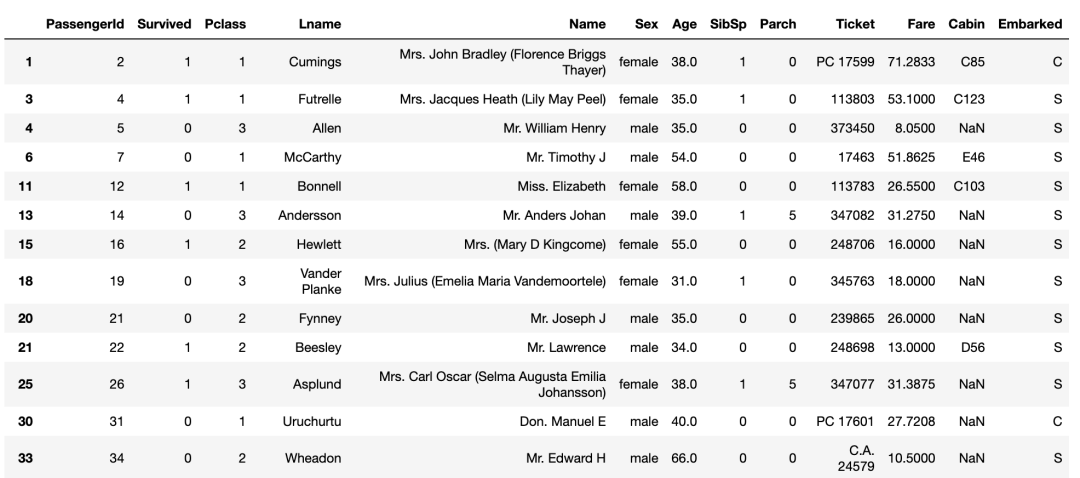
# 根据条件筛选数据
titanic_df.loc[titanic_df[‘Age’] > 30]
07
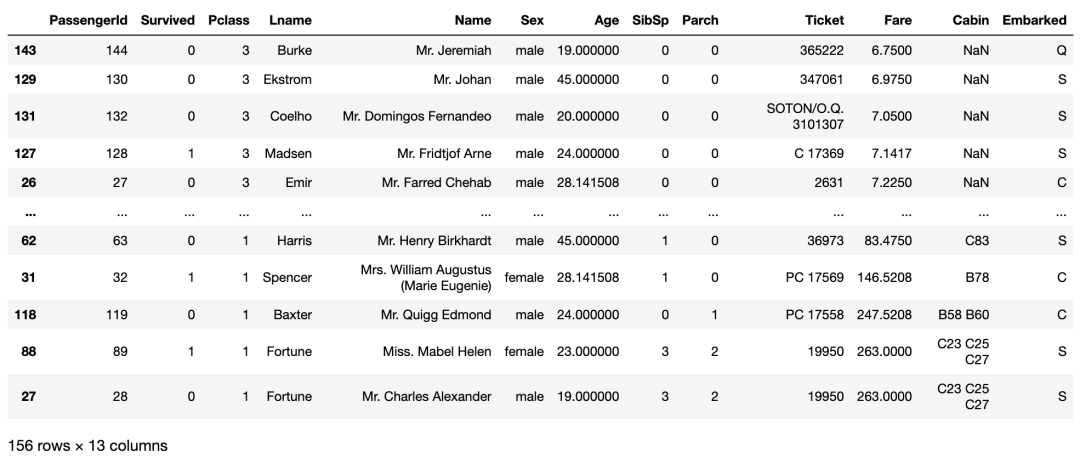
# 按特定列对数据进行排序
titanic_df_sorted = titanic_df.sort_values(by=‘Fare’)
titanic_df_sorted
08
对数据进行分组和聚合对于总结信息至关重要,如通过按性别计算平均收入所示。
# 按分类变量对数据进行分组,并计算均值
titanic_df.groupby(‘Sex’)[‘Survived’].mean()

09
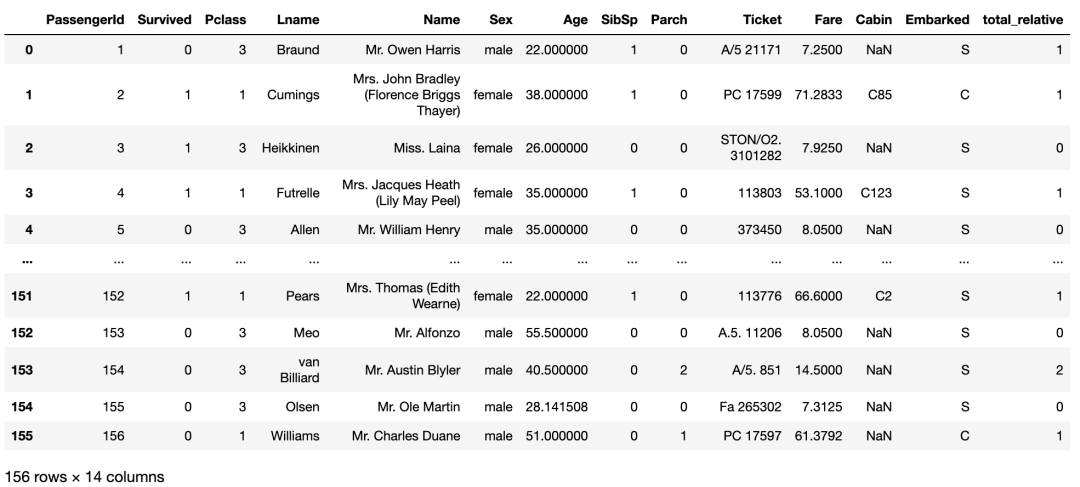
# 根据现有列创建新列
titanic_df[‘total_relative’] = titanic_df[‘SibSp’] + titanic_df[‘Parch’]
titanic_df
10
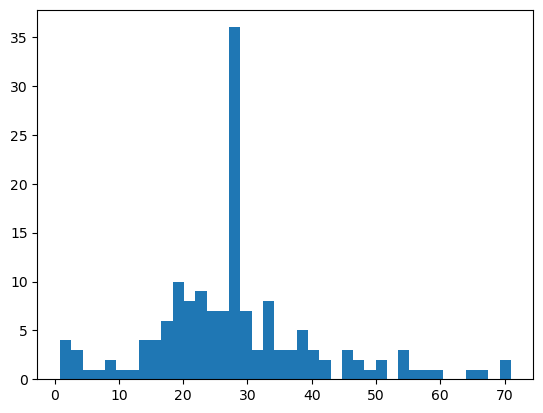
import matplotlib.pyplot as plt
# 绘制“Age”列的直方图
plt.hist(titanic_df[‘Age’],bins = 40)
plt.show()
11 # 将数据旋转以重新塑造它
titanic_df_pivot = titanic_df.pivot_table(index=‘Survived’, columns=‘Sex’, values=‘Age’, aggfunc=‘mean’)
titanic_df_pivot
合并在处理多个数据集时非常有用,它根据共享列将它们组合在一起。
12
# 将数据旋转以重新塑造它
titanic_df_pivot = titanic_df.pivot_table(index=‘Survived’, columns=‘Sex’, values=‘Age’, aggfunc=‘mean’)
titanic_df_pivot
数据透视表有助于重塑您的数据,使其更适合分析和可视化。
13
# 将一列转换为日期时间格式
df[‘Date’] = pd.to_datetime(df[‘Date’])
# 从“Date”列提取月份
df[‘Month’] = df[‘Date’].dt.month
处理日期和时间对于时间序列分析至关重要。这些示例演示了将列转换为日期时间格式并提取月份信息。使用虚拟代码(上文)因为在泰坦尼克数据框中没有时间列。
14
# 根据选择的列删除重复行
df_no_duplicates = titanic_df.drop_duplicates(subset=['PassengerId'])
df_no_duplicates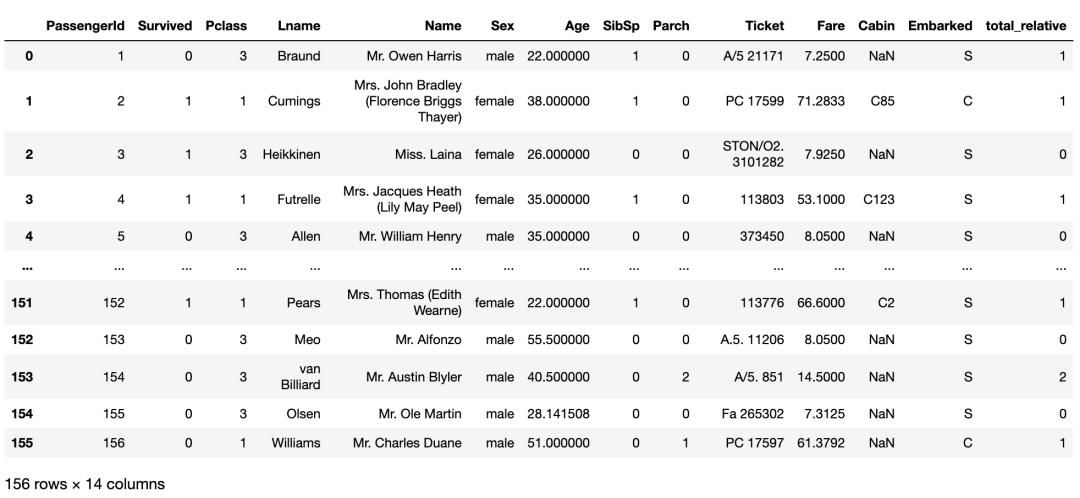
15
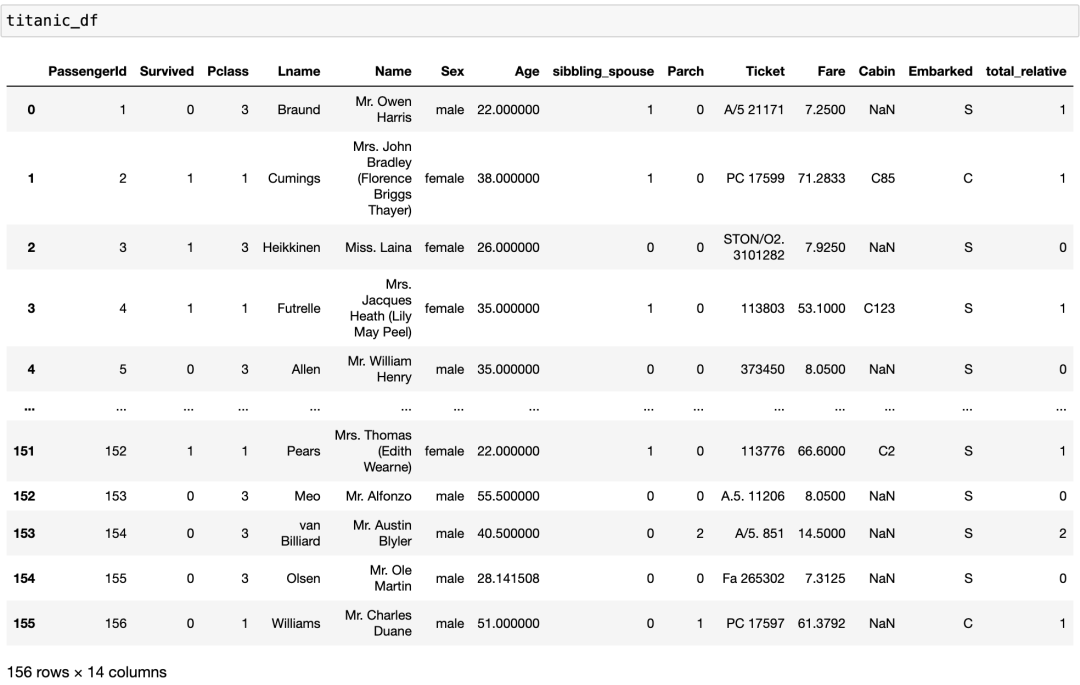
# 为清晰起见重命名列
titanic_df.rename(columns={‘SibSp’: ‘sibbling_spouse’}, inplace=True)
Python是当下最大众化的编程语言,但其基本概念、基础知识还是比较多的,对于小白来说,一时间要掌握这么多还是有些吃力,甚至学完就忘!
16 # 计算“Income”列的第75百分位数
fare_75th_percentile = titanic_df[‘Fare’].quantile(0.75)
fare_75th_percentile
# 输出:30.37185
百分位数提供了关于数字数据分布的见解。
在以下示例中,我们将使用一个虚拟数据框 ——df。
17 # 将“价格”列转换为数字
df[‘Price’] = pd.to_numeric(df[‘Price’], errors=‘coerce’)
在处理不一致的数据格式时,转换数据类型至关重要。
18
# 将自定义函数应用于一列
df[‘Discounted_Price’] = df[‘Price’].apply(lambda x: x * 0.9)
应用函数可以实现对数据的更复杂转换。
19
# 将列转换为分类类型
df[‘Category’] = df[‘Category’].astype(‘category’)
处理分类数据可以提高效率并减少内存使用。
20
# 将 DataFrame 导出到 CSV 文件
df.to_csv(‘output_dataset.csv’, index=False)
保存您处理过的数据对于分享结果和将来参考至关重要。
这 20 个 Pandas 代码涵盖了广泛的数据分析任务,为任何有抱负的数据分析师提供了坚实基础。通过掌握这些技术,您将能够很好地处理真实世界的数据集并得出有价值的见解。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/102100
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!