
数据清洗实践(附程序代码)
- 错误值处理
识别和处理错误值的方法主要是不同的数据源交叉比对。比如有A、B、C三个数据源,同样的数据从A和B采集的数值相同,但跟C采集的数值不同,则以数据源A或B采集的数据为准。在Python中可以用pandas来完成交叉比对,示例如下:
import pandas as pd
#df_A、df_B、df_B为三个数据表,这三张表的数据本应相同,但现在有错误的数据在里面
df_A = pd.DataFrame({‘value_A’: [10, 20, 30]},index=[‘2020-02-01′,’2020-02-02′,’2020-02-03’])
df_B = pd.DataFrame({‘value_B’: [10, 20, 31]},index=[‘2020-02-01′,’2020-02-02′,’2020-02-03’])
df_C = pd.DataFrame({‘value_C’: [10, 22, 30]},index=[‘2020-02-01′,’2020-02-02′,’2020-02-03’])
#将df_A、df_B、df_B合并为1个DataFrame
df = df_A.join([df_B, df_C], how=’outer’)
#比较value_A、value_B两列,如果值相等,则’correct’的值设为True(数据正确),否则为False(存在错误数据)
df[‘correct’] = (df[‘value_A’] == df[‘value_B’])
#如果’correct’列的值设为True,则取value_A为结果值,否则取value_C的值为结果值
df[‘value’] = df.apply(lambda x: x[‘value_A’] if x[‘correct’] else x[‘value_C’], axis=1)
用 print(df) 将结果输出查看:
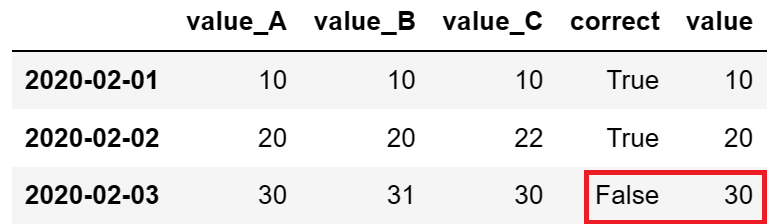

最后一列’value’即为数据交叉比对后的结果,可以看到’2020-02-03’这一天的数据value_A和value_C相同,但跟value_B不同,由此判断value_B的数据出现错误,最后采用的结果为value_A或value_C的数据。
- 缺失值处理
处理缺失值的方法有很多种。最简单的方法是删除包含缺失值的记录,但这种方法可能会导致数据的丢失。另一个常见的方法是使用数据集中其他值的统计信息(如平均值、中位数或众数)来填充缺失值。这种方法可以保留数据,但可能会引入一些偏差。在选择处理缺失值的方法时,需要考虑数据的特性和分析的目的。
下面示例如何使用数据集中的平均值来填充缺失值:
import pandas as pd
import numpy as np
#假设我们有一个包含缺失值(np.nan)的数据集
df = pd.DataFrame({
‘A’: [1, 2, np.nan, 6],
‘B’: [5, np.nan, np.nan, 8],
‘C’: [9, 10, 11, 12]
})
#使用列的平均值来填充缺失值。fillna()为填充缺失值的函数。
df.fillna(value=df.mean(), inplace=True)
对比缺失值处理前后的数据集,A、B两列中的缺失值已经用该列的均值来填充:
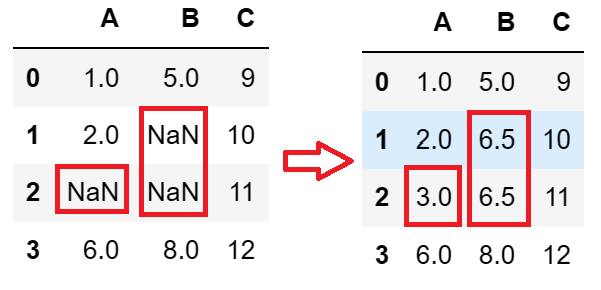
- 异常值(极端值)处理
处理异常值的方法有很多种。一种常见的方法是使用IQR(四分位数范围)方法来识别和处理异常值。IQR是第三四分位数(Q3)和第一四分位数(Q1)之间的差,它可以用来衡量数据的离散程度。在这种方法中,我们通常认为那些小于(Q1-1.5IQR)或大于(Q3+1.5IQR)的值是异常值。识别出异常值后,我们可以根据需要删除它们,或者用其他值替换它们。
下面的例子使用IQR(四分位数范围)方法来识别和删除异常值:
#假设我们有一个可能包含异常值的数据集,最后一个值1000明显偏离正常值的范围
df = pd.DataFrame({
‘A’: [1, 2, 3, 4, 5, 1000]
})
#使用IQR方法来识别异常值
Q1 = df[‘A’].quantile(0.25) # 第一四分位数
Q3 = df[‘A’].quantile(0.75) # 第三四分位数
IQR = Q3 – Q1
#正常值范围在(Q1 – 1.5 * IQR)和(Q3 + 1.5 * IQR)之间,不在这个范围内的就是异常值,对异常值作删除处理
df = df[~((df[‘A’] < (Q1 – 1.5 * IQR)) |(df[‘A’] > (Q3 + 1.5 * IQR)))]
对比处理前后的数据集,可以看到异常值1000已经被识别出来并予以删除:
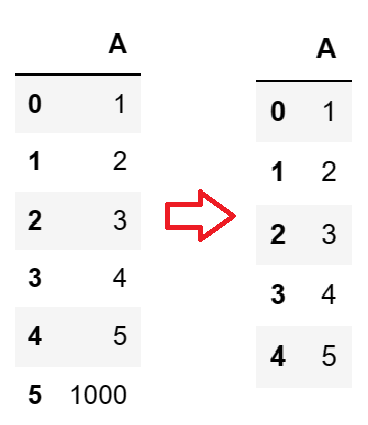
- 重复数据处理
处理重复数据的常见方法是使用数据处理工具提供的函数来删除重复的记录。在删除重复数据时,需要确保只保留一条记录,以保持数据的完整性。
下面的例子使用pandas的drop_duplicates方法来删除重复的行:
#假设我们有一个包含重复行的数据集
df = pd.DataFrame({
‘A’: [1, 2, 2, 4],
‘B’: [5, 6, 6, 8],
‘C’: [9, 10, 10, 12]
},index=[‘2020-02-01′,’2020-02-02′,’2020-02-02′,’2020-02-03’])
#删除重复的行
df = df.drop_duplicates()
对比处理前后的数据集,可以看到重复的行已经被删除:
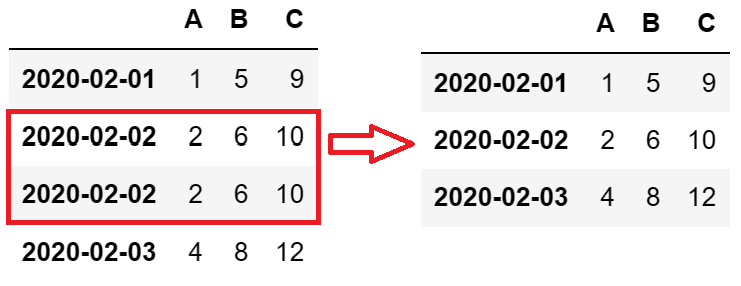
- 数据格式不一致或数据类型错误的处理
对于数据格式不一致或数据类型错误,需要根据数据的实际类型,通过转换数据类型来解决。例如,如果数据中的日期被记录为不同的格式,或日期数据类型被错误记录为文本,我们可以使用数据处理工具的函数来转换日期的格式,将其调整为正确的数据类型。
处理不一致或错误的数据通常需要根据具体的情况来决定。下面的例子中数据集中的日期被记录为不同的格式,我们使用pandas的to_datetime方法来统一日期的格式:
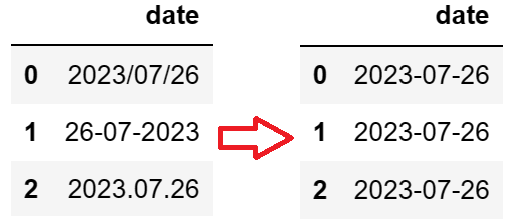
#假设我们有一个包含不一致的日期的数据集
df = pd.DataFrame({
‘date’: [‘2023/07/26′, ’26-07-2023’, ‘2023.07.26’]
})
#将日期转换为统一的格式
df[‘date’] = pd.to_datetime(df[‘date’])
处理后的日期数据统一为datetime格式:
以上就是数据清洗的一些常见方法。在实际的数据清洗过程中,需要根据数据的具体情况来选择适当的清洗方法。
发布者:爱吃肉的小猫,转载请注明出处:https://www.95sca.cn/archives/46124
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!