
量化入门系列:估值百分位增强的定投模型
本系列通过实例来介绍量化的入门知识,适合零基础的初学者。本文的量化环境基于Python和AKShare数据接口,安装教程见文末附录。
在普通的定投中,每期投入的金额是一样的,而将估值百分位用在定投中,总体思路是在指数低估时加大投资金额,在指数高估时减少投资金额。具体实现方法如下:
每期投入金额 = 定投基数 × 调整系数
调整系数 = (150%-估值百分位) ^ n
^ n 表示 n 次方
假设定投基数为100元,当期指数的估值百分位为50%,调整系数=(150%-50%)^n=1,当期投入的金额就等于定投基数100元;
如果当期的估值百分位为20%,调整系数=(150%-20%)^n=1.3^n,如果n=1,则调整系数=1.3倍,当期投入的金额=100元×1.3=130元,这就实现了指数低估时多投(比定投基数100元多投了30元)。我们可以通过调节 n 的值来调节定投的倍数,n 的值越大定投的倍数越大,当期投入金额越多,比如 n=2 时,调整系数=1.3^2=1.69倍。
如果当期的估值百分位为80%,调整系数=(150%-80%)^n=0.7^n,如果n=1,则调整系数=0.7倍,当期投入的金额=100元×0.7=70元,在指数高估时比定投基数100元少投了30元。同样我们可以通过调节 n 的值来调节定投的倍数,n 的值越大定投的倍数越小,当期投入金额越少,比如 n=2 时,调整系数=0.7^2=0.49倍。
下面我们用Python来实现这个逻辑:
首先是导入需要的库:
import akshare as ak # 导入AKShare数据源
import pandas as pd # 导入pandas库
import datetime # 导入datetime库
import bottleneck as bk
import numpy as np
然后取沪深300的PE和收盘价数据,放在DataFrame表格 hs300_df 中:
hs300_df = ak.stock_a_pe(market=”000300.XSHG”)[[‘middlePETTM’,’close’]] # 获取沪深300的PE和收盘价数据
接下来是计算估值百分位。这里有一个新人容易犯的错误需要注意:假设我们从2014年1月2日开始定投,在2021年11月14日结束定投,常见的错误是获取2014年1月2日 – 2021年11月14日的PE数据,然后根据这段时间的PE数据计算估值百分位。为什么说这样是错的呢,因为在2014年1月2日这一天定投时,用到的估值百分位的数据是根据这天之后的PE值计算的,这样就用到了未来数据。
正确的方法是用过去的PE值来计算估值百分位,我们用7年的时间来计算估值百分位(因为A股牛熊间隔大概为7年),因此在2014年1月2日要用2007年1月2日 – 2014年1月2日的PE值来计算估值百分位,在2014年1月3日要用2007年1月3日 – 2014年1月3日的PE值来计算估值百分位,如此滚动计算。
start_date = datetime.date(2014,1,1) # 定投开始日期
pe_start_date = datetime.date(2006,12,1) # PE数据的开始日期,往前多取几天
hs300_df = hs300_df[hs300_df.index>=pe_start_date] # 截取pe_start_date之后的数据
pct_rank = lambda x: bk.rankdata(x)[-1]/len(x) # 用来计算百分位的函数
hs300_df[‘PE_rank’] = hs300_df[‘middlePETTM’].rolling(window=1708).apply(pct_rank) # 滚动计算估值百分位,时间窗口为7年*244个交易日每年=1708天
hs300_df = hs300_df[hs300_df.index>=start_date] # 截取定投开始日之后的数据
把DataFrame表格 hs300_df 显示出来看下:
print (hs300_df)

下面开始构建定投模型:
base_money = 100 # 定投基数
power = 2 # 指数值
fees = 0.001 # 交易手续费率设为千分之一
hs300_df[‘调整系数’] = (1.5-hs300_df[‘PE_rank’])**power # 调整系数 = (150%-估值百分位) ^ power
hs300_df[‘每期定投金额’] = base_money * hs300_df[‘调整系数’] # 每期投入金额 = 定投基数 × 调整系数
hs300_df[‘累计定投金额’] = hs300_df[‘每期定投金额’].cumsum() #‘每期定投金额’的累计值
hs300_df[‘每期定投数量’] = hs300_df[‘每期定投金额’] / hs300_df[‘close’] * (1-fees) # 每期能买到的股数
hs300_df[‘累计持有数量’] = hs300_df[‘每期定投数量’].cumsum() #‘每期定投数量’的累计值
hs300_df[‘累计持仓净值’] = hs300_df[‘累计持有数量’] * hs300_df[‘close’] # 所持有的全部基金当天收盘后的价值
hs300_df[‘现金流’] = hs300_df[‘每期定投金额’] * -1
hs300_df.loc[hs300_df.index[-1],’现金流’] = hs300_df[‘累计持仓净值’][-1] – hs300_df[‘每期定投金额’][-1]
这些代码在上一期讲解过,就不再重复了,有不清楚的请翻看这个系列的上篇文章。
将做好的定投模型显示出来:
print (hs300_df)
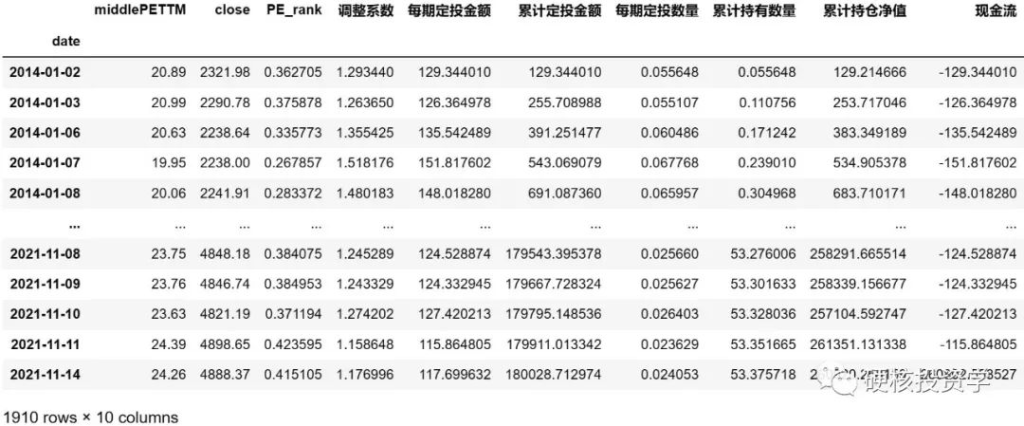
总共投了1910期,累计定投金额为180028元,累计持仓净值为260802元。
将资金曲线图画出来:
hs300_df[[‘累计定投金额’,’累计持仓净值’]].plot(figsize=(16,8),grid=True,title=’定投的资金曲线图’) # 画图
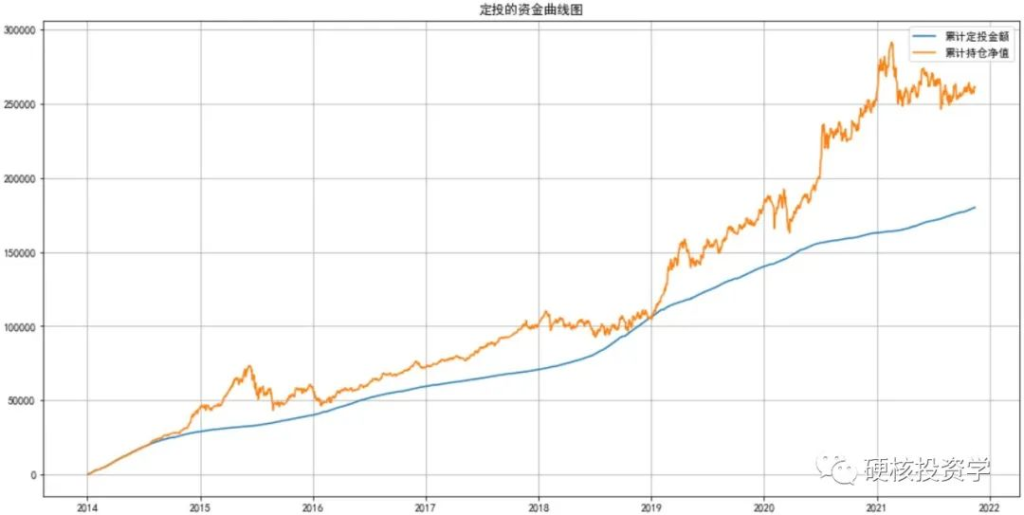
累计持仓净值曲线(黄线)一直在累计定投金额曲线(蓝线)之上,说明在这个定投期间内基本没有出现过亏损。
最后我们计算一下定投的年化收益率,用 np.irr () 这个函数就可以计算出现金流的内含收益率,因为我们是每天定投,现金流是每天的,所以计算出的内含收益率是日收益率,需要转化为年收益率:
年收益率 = (1 + 日收益率) ^ (244) – 1
1年大概有244个交易日,所以是244次方。
irr = (1+np.irr(list(hs300_df[‘现金流’])))**244-1
print (irr)
估值百分位增强型定投的年化收益率为9.8%。如果用普通的定投模型,同样的定投期间,年化收益率为8.1%。可以看出用估值百分位来增强定投是有效的。
前面说过,每期投入金额的调整系数有一个 n 次方的参数,用这个参数可以调节定投的倍数,n 越大时,指数低估时投得越多,指数高估时投得越少。在上面的例子中 n 取值为 2 ,我们试着加大 n 的取值,看效果如何,将代码中的 power = 2 改成:power = 4 ,重新运行,可以计算出此时的年化收益率为11.1%,效果更好了。
需要注意的是,加大 power 值的同时,每期实际投入金额的最大值也会随之增大。当 power = 2 时,每期实际投入金额的最大值为 224 元,即定投基数 100 元的 2.24 倍;当 power = 4 时,每期实际投入金额的最大值为 505 元,即定投基数 100 元的 5.05 倍。大家可以根据自己实际的资金情况来选择一个合适的参数值。
发布者:爱吃肉的小猫,转载请注明出处:https://www.95sca.cn/archives/40369
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!