
01 关于财富自由
最近把市面上几乎能找到的财富管理相关的,成长类的书籍,都读了一遍。
古云:“书读百遍,其义自现”,这里可以改在“书读百本,其义自现”。
个中的底层逻辑大多是相通的。
这类财富自由书,一般都不讲两个东西:
一是怎么创业和经营公司,这看似最与财富相关的方向;
二是不讲职场成长,人际社交。
我把这类财富自由称之为“财富小自由”。
像马云这种大企业家,成功集天时、地利、人和,领袖气质,冒险精神,人脉资源,家族传承,客观讲不是什么书本可以教授的东西。
这种成功“一将功成万骨枯”,普通人看看就好。
另外“小自由”,这里的“自由”,一般就是指“脱离”职场,即不必为生活去工作,即“工作自由”,所以自然不会描述工作中的成长相关。
她是选择中间的一条路,储蓄与投资(理财),被动收入。
从开源节流的角度,越靠节流这一端,就偏向过极简生活(FIRE运动);越是靠近开源这一端,就是价值创造,进而实现被动收入(注意不是工资收入)。
当下的环境,对于普通人这条路是有可能的。
02 关于读书
海量阅读是非常有价值的。
在你迷茫没有方向,内心焦虑,苦闷的时候,大量地去读书。
书中自有答案,你经历的,很多人都经历过。
低成本地经历一下别人的人生,“太阳底下并无新鲜事”。
听书只是为了判断这本书值不值得读,如果是好书,还是建议自己读原书,至少翻翻电子书。
每个人的阅历不同,解读的角度也不一样。
03 国运与大盘
时代趋势决定了我们的基本盘。
苏东坡壮年,王安石变法,举国上下鸡飞狗跳,这就注定了他起伏的一生。
国运昌盛,则资本市场兴。
04 因子分析
qlib模型训练及回测阶段代码使用了mlfow,很多人不是那么熟悉,我把它的代码最简化拿出来,去掉mlflow框架。
with R.start(experiment_name="workflow"): # train #R.log_params(**flatten_dict(task)) model.fit(dataset) # prediction recorder = R.get_recorder() sr = SignalRecord(model, dataset, recorder) sr.generate() # Signal Analysis sar = SigAnaRecord(recorder) sar.generate()
它有各种recoreder,然后统一都调用generate,里面发生了什么呢?
其实很简单。
SiganlRecord只做一件事,就是——调用训练好的模型,预测数据集,并保存到pred.pkl里,同时把测试数据集的label,保存到label.pkl里。
自己的代码如下:(这样看起来是不是就很直观了)
model.fit(dataset)
pred = model.predict(dataset)
if isinstance(pred, pd.Series):
print('is serice...')
pred = pred.to_frame('score')
pprint(pred)
pred.to_pickle('output/pred.pkl')
# 取label并保存
label = dataset.prepare(segments="test", col_set="label", data_key=DataHandlerLP.DK_R)
pprint(label)
label.to_pickle('output/label.pkl')
SigAnaRecord也一样,它读出pred.pkl和label.pkl后,计算IC值,就是预测值与label之间的“相关性”,从简化的角度,这里我们可以不save和load直接计算也行。
def calc_ic(pred: pd.Series, label: pd.Series, date_col="datetime", dropna=False) -> (pd.Series, pd.Series): df = pd.DataFrame({"pred": pred, "label": label}) ic = df.groupby(date_col).apply(lambda df: df["pred"].corr(df["label"])) ric = df.groupby(date_col).apply(lambda df: df["pred"].corr(df["label"], method="spearman")) if dropna: return ic.dropna(), ric.dropna() else: return ic, ric
calc_ic这个函数,按日期groupby后计算 pred 和 label 这两个序列的 pearson相关性和spearman相关性。
二者其实是统计学的基本概念,pearson就是传统的相关系数,而spearman是“秩相关系数”,金融上叫IC与RIC。
我们经常听金融工程的同学说“因子的IC值”,其实就是这个因子的预测结果与实际结果的相关性。
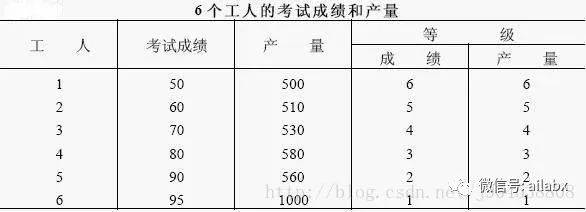
RIC大家可能陌生一点,叫“斯皮尔曼等级(秩)相关性”。
看下面这个例子,“考试成绩与产量”的相关系数=0.6+, 但若先转换为等级后,再算相关系数=1。

了解了原理,计算就比较简单了:
all = pd.concat([pred, label], axis=1) pprint(all) ic = all.groupby('datetime').apply(lambda df: df["score"].corr(df["LABEL0"])) ric = all.groupby('datetime').apply(lambda df: df["score"].corr(df["LABEL0"], method="spearman"))
05 多空分析
def calc_long_short_return( pred: pd.Series, label: pd.Series, date_col: str = "datetime", quantile: float = 0.2, dropna: bool = False, ) -> Tuple[pd.Series, pd.Series]: df = pd.DataFrame({"pred": pred, "label": label}) if dropna: df.dropna(inplace=True) group = df.groupby(level=date_col) def N(x): return int(len(x) * quantile) r_long = group.apply(lambda x: x.nlargest(N(x), columns="pred").label.mean()) r_short = group.apply(lambda x: x.nsmallest(N(x), columns="pred").label.mean()) r_avg = group.label.mean() return (r_long - r_short) / 2, r_avg
用自己的代码实现类似:
group = all.groupby(level='datetime') def N(x): return int(len(x) * 0.2) # 打分的前20%, 与后20% 对应的 真实收益率 r_long = group.apply(lambda x: x.nlargest(N(x), columns="score").LABEL0.mean()) r_short = group.apply(lambda x: x.nsmallest(N(x), columns="score").LABEL0.mean()) r_avg = group.LABEL0.mean() print((r_long-r_short)/2, r_avg)
这里r_avg就是当天所有股票的收益率的平均;
r_long是买入前20%高分的股票的平均收益;
r_short是买入后20%(低分)的股票的收益;
(r_long-r_short)/2即 最好组与最差组的 收益之差/2。
最后对根据序列计算年化的 收益率与夏普比(注意这个不是回测结果,而是模型的因子分析):
print("多空年化收益", r_long_short.mean() * 252) print("多空夏普比", r_long_short.mean() / r_long_short.std() * 252 ** 0.5) print("平均年化收益", r_avg.mean() * 252) print("平均年化夏普比", r_avg.mean() / r_avg.std() * 252 ** 0.5)
上面这些如下:
sar = SigAnaRecord(recorder)
sar.generate()
两行代码做的事情。
06 回测
基于实验的流程里的代码:
par = PortAnaRecord(recorder, port_analysis_config, "day") par.generate()
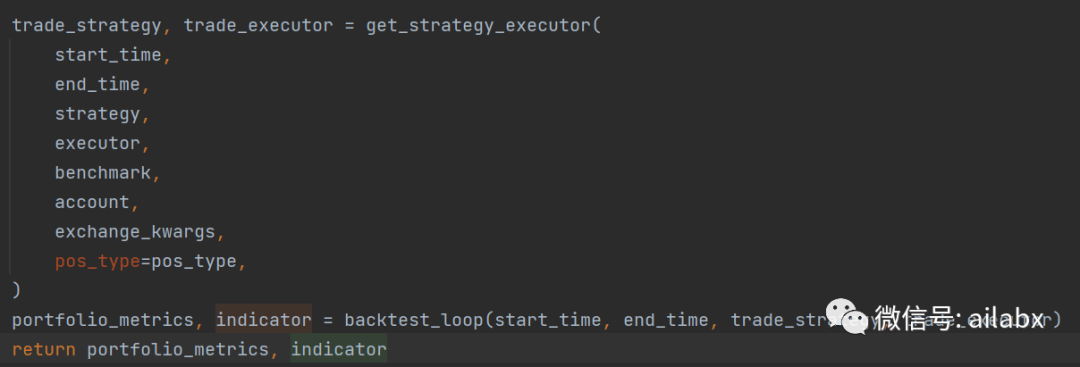
调用的是backtest_loop
单独初始化:
def get_strategy(pred_score, topK=50, n_drop=5, ): STRATEGY_CONFIG = { "topk": 50, "n_drop": 5, "signal": pred_score # pred_score, } strategy_obj = TopkDropoutStrategy(**STRATEGY_CONFIG) return strategy_obj def get_executor(): EXECUTOR_CONFIG = { "time_per_step": "day", "generate_portfolio_metrics": True, } executor_obj = executor.SimulatorExecutor(**EXECUTOR_CONFIG) return executor_obj
调用回测函数得到结果:
def do_backtest(executor, strategy, benchmark='SH000300', start_time="2017-01-01", end_time="2022-08-01"): backtest_config = { "start_time": start_time, "end_time": end_time, "account": 100000000, "benchmark": benchmark, "exchange_kwargs": { "freq": 'day', "limit_threshold": 0.095, "deal_price": "close", "open_cost": 0.0005, "close_cost": 0.0015, "min_cost": 5, }, } portfolio_metric_dict, indicator_dict = backtest(executor=executor, strategy=strategy, **backtest_config) analysis_freq = "{0}{1}".format(*Freq.parse('day')) pprint(portfolio_metric_dict, indicator_dict) # backtest info report_normal_df, positions_normal = portfolio_metric_dict.get(analysis_freq)
明天可以分析回测结果,以及对结果进行可视化。
小结:
把qlib原先的yaml驱动的全流程,基本上拆开了,由于它本身就是松散结构,这个工作不算复杂。
核心是理清数据结构(多为pandas的dataframe)。
与传统策略相比,多了一步因子的 IC分析与多空分析。
就是统计学上基本概念,不复杂。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104219
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!