
——写在前面,关于人生计划之“ABCZ”。B计划是“人生第二曲线”,是个人能力模型,兴趣外延。而不是“凭空设想”——这个更像是C计划。很多人上什么学校、学什么专业,在那个年纪是没有概念的,然后就找了一份工作,一做好多年,不甘心但放弃成本也不低。这时候,业余可能发展了一些兴趣,做了一些自己有天赋的事情,可能可以过渡了B计划。
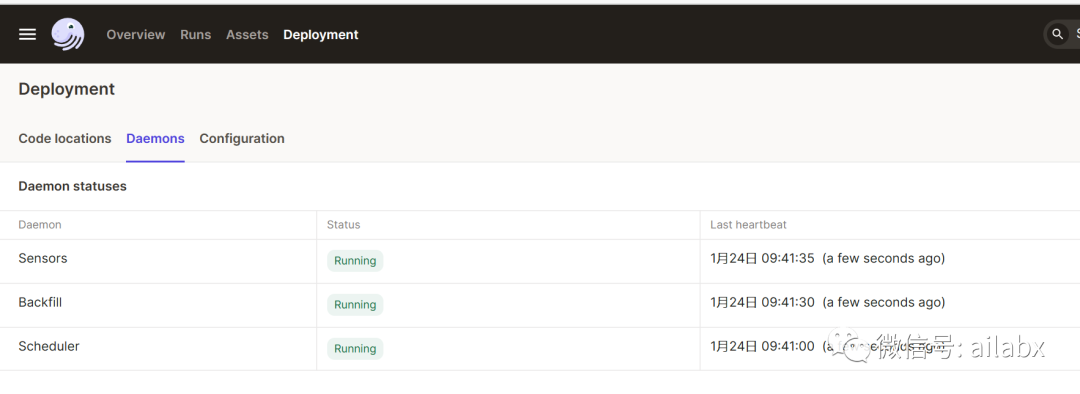
农历正月初三,今天继续聊dagster。
金融数据需要定时更新,在AI量化的工程里,定时任务很重要。
apscheduler是第一个被考量的,但需要自己管理日志,任务多了之后,任务之间的依赖与管理变得复杂。所以,我们还是考虑引入dagster。
dagster的Dockfile如下:
FROM python:3.9-slim
RUN mkdir -p /opt/dagster/dagster_home /opt/dagster/app
WORKDIR /opt/dagster/app
COPY . /opt/dagster/app
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
ENV DAGSTER_HOME=/opt/dagster/dagster_home/
VOLUME /opt/dagster/app
VOLUME /opt/dagster/dagster_home
EXPOSE 3000
RUN chmod -x start.sh ENTRYPOINT ["sh", "./start.sh"]
docker里的启动命令在start.sh:
dagster-daemon run & dagit -h 0.0.0.0 -p 3000
在docker-compose里的服务如下,把代码目录映射opt/datsteer/app里即可,后续如果只是代码变更,git直接更新即可,如果依赖有更新,则需要重新build镜像。
version: '3' services: dagster: image: 'mydagster' container_name: mydagster volumes: - /root/codes/ailab/quant-project:/opt/dagster/app ports: - 3000:3000

之前我们价量数据主要存储在mongodb里。但mongodb若要做全市场数据分析,需要把所有数据加载到内存进行计算,进行排序。——比如可转债多因模型就是如此,如果是A股的话,数据量更大。
我们需要加载700多支可转债,然后对每支可转债进行数据采集、指标计算,而后把数据合成为一个hdf5文件。
这里用到了dagster的动态图。
这里的task_graph就是单支证券的任务,可以是多个op,甚至是多个graph。
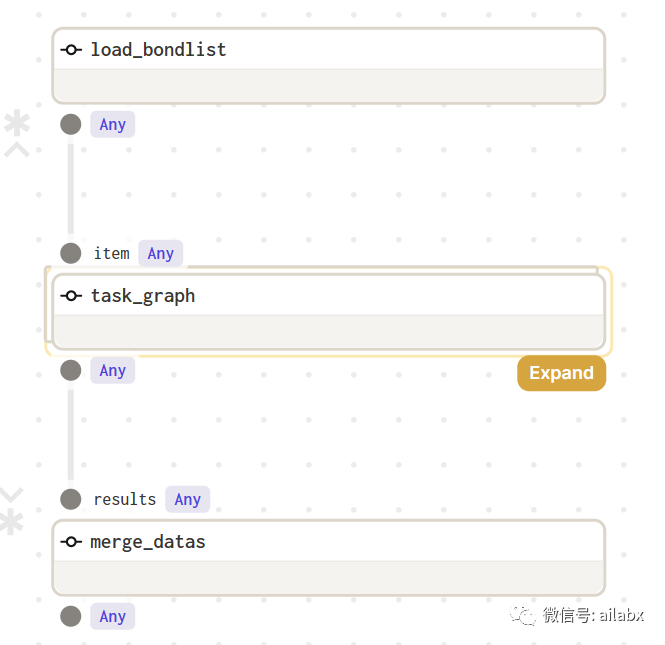
from dagster import asset, get_dagster_logger, op, DynamicOut, graph, job, DynamicOutput from quant_project.datafeed import mongo_utils @op(out=DynamicOut()) def load_bondlist(): cols = ['code', 'bond_short_name', 'stk_code', 'list_date', 'delist_date'] filters = {col: 1 for col in cols} filters['_id'] = 0 items = mongo_utils.get_db()['cb_basic'].find({}, filters) items = list(items) items = ['1', '2', '3'] for idx, item in enumerate(items): yield DynamicOutput(item, mapping_key=str(idx)) @op def update_factor_chg(item): print('step...') return item @op(name='update_close') def update_factor_close(item): print(item) return item @graph def task_graph(item): update_factor_close(item) results = update_factor_chg(item) return results @op def merge_datas(results): print('merging...') @job def cb_task_job(): bonds = load_bondlist() results = bonds.map(task_graph) print(results.collect()) merge_datas(results.collect()) one_code_job = task_graph.to_job('task_graph_job') if __name__ == "__main__": result = cb_task_job.execute_in_process()
体验下来,dagster是很适合金融数据采集、处理,还有机器学习的场景。当然这里的场景更偏向于“批处理”,“定时任务”的处理与编排。
而基于kafka streaming以及flink的流式计算,无论是airflow、prefect还是dagster都不太擅长。prefect的社区似乎有一个kafka的consumer。
在AI量化投资的场景,dagster是不错的。目前会考虑把它做为我们数据采集,任务执行的基础平台。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104168
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!