
把整个框架与思路都在社群里开源出来,就是希望大家看懂思路,而不是拿一两个策略。说实话,投资哪有这种高确定性的“圣杯”。
投资是一个“概率”游戏。我们要做的,尽量提升决策的正概率而已。因此,多一些有效因子,模型判断更准确一些。所以,方法论和思路比一个策略本身要重要得多。这是我们这个社群的目标——以盈利为目的开发策略,而且是批量的有效实战策略。
微信群现在的讨论氛围还不错,还没有加入的成员请扫码进入。一般加入之初,我都有发私信给大家,如果没有,请再星球里私信我。
今天要抽空实现“前向滚动”训练回测。
从20日动量来看,我们选择29个行业作为候选集合是对的。
因为市场是按行业分化的,尤其是市场情绪震荡有分歧之时:
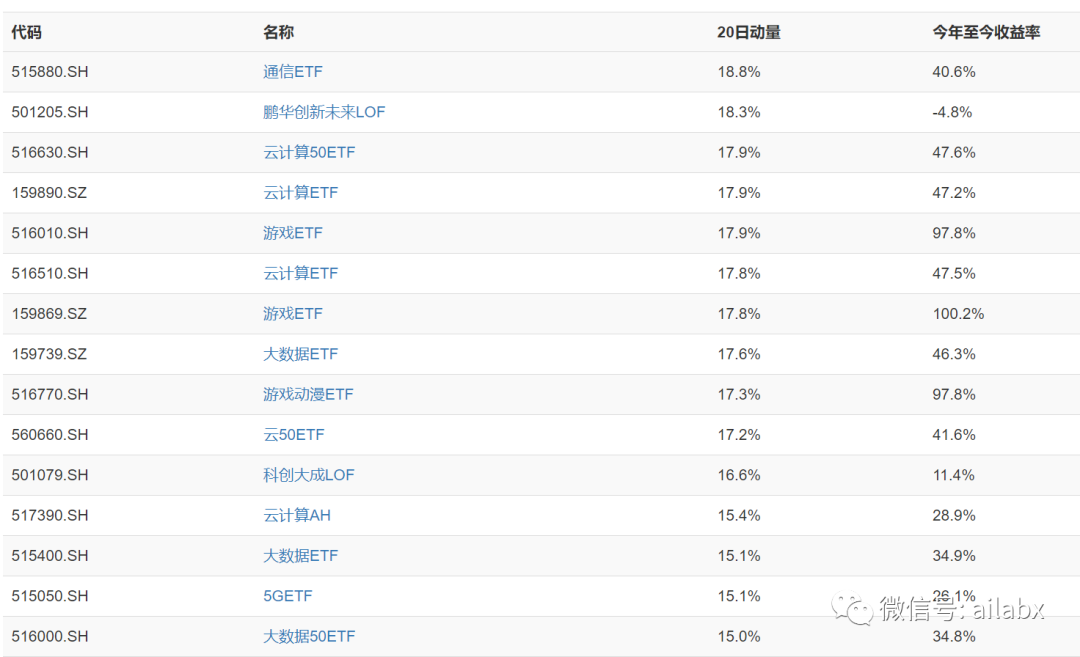

29个行业等权回测:
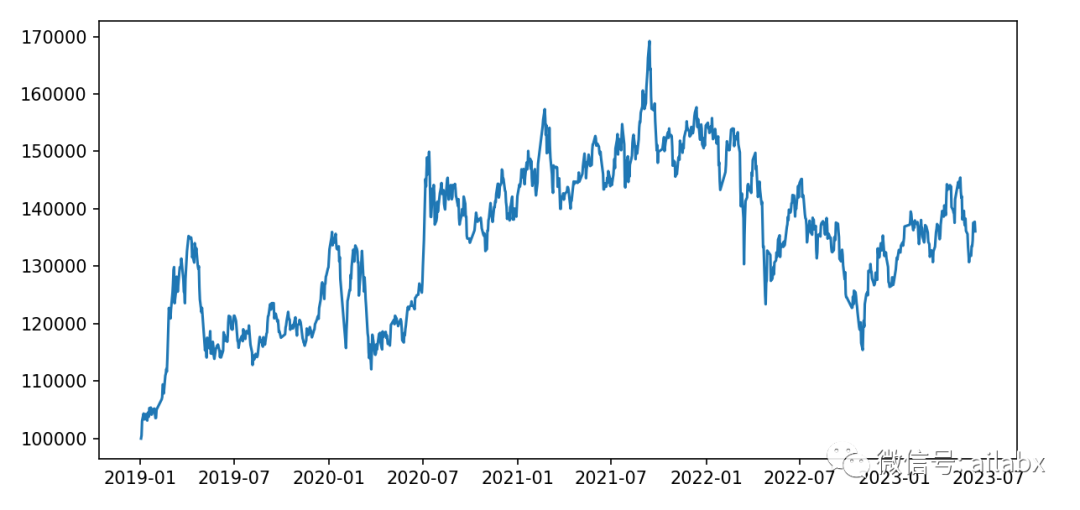
年化收益 0.075,最大回测 -0.318,夏普比 0.441。
等权加周再平衡:
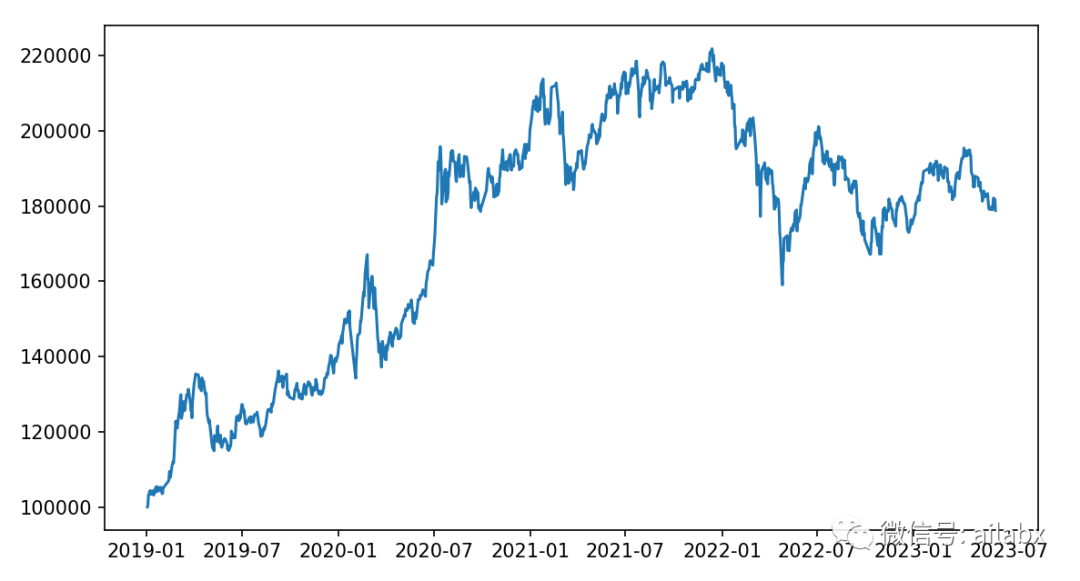
年化收益 0.146,最大回测 -0.283,夏普比 0.748。再平衡适合相关性低的组合,正当的行业比较明显。
使用lightGBM的WFA滚动训练:
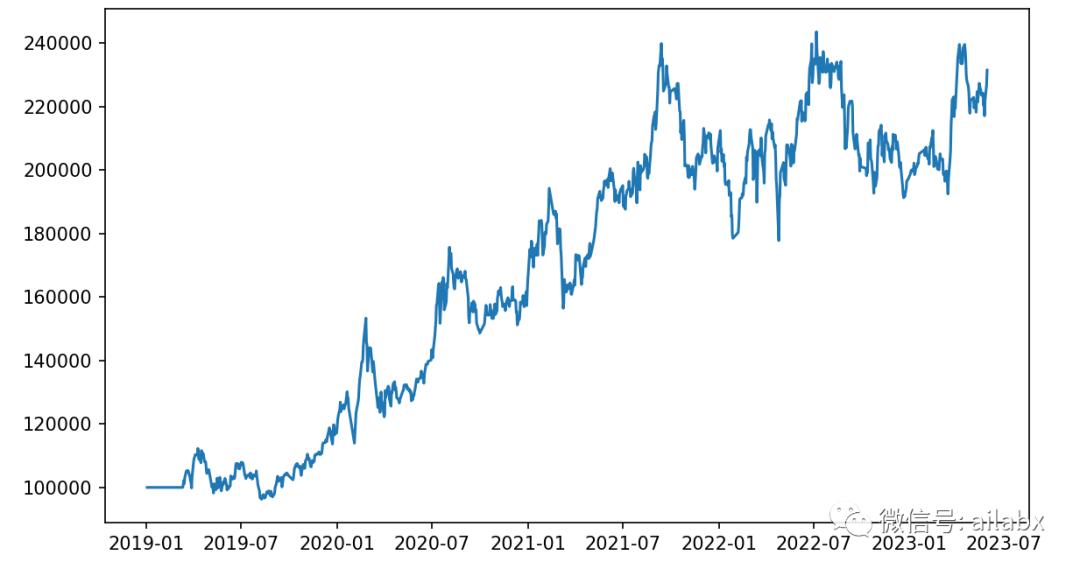
年化收益 0.219,最大回测 -0.259,夏普比 0.861。
etfs = [
'159870.SZ',
'512400.SH',
'515220.SH',
'515210.SH',
'516950.SH',
'562800.SH',
'515170.SH',
'512690.SH',
'159996.SZ',
'159865.SZ',
'159766.SZ',
'515950.SH',
'159992.SZ',
'159839.SZ',
'512170.SH',
'159883.SZ',
'512980.SH',
'159869.SZ',
'515050.SH',
'515000.SH',
'515880.SH',
'512480.SH',
'515230.SH',
'512670.SH',
'515790.SH',
'159757.SZ',
'516110.SH',
'512800.SH',
'512200.SH',
]
import numpy as np
import pandas as pd
from tqdm import tqdm
from engine.env import Env
from engine.datafeed.dataset import DataSet, AlphaLit, Alpha
ds = DataSet(etfs, start_date='20190101', handler=Alpha(), cache=True)
# ds = DataSet(['000300.SH', '399006.SZ'], start_date='20120101', handler=Alpha())
env = Env(ds.data)
from engine.context import ExecContext
from engine.algo.algos import *
from engine.algo.algo_model import ModelWFA
from engine.models.gbdt_l2r import LGBModel
model = LGBModel(load_model=False, feature_cols=ds.get_feature_names())
env.set_algos([
RunWeekly(),
ModelWFA(model=model),
SelectTopK(K=2, order_by='pred_score', b_ascending=False),
WeightEqually()
])
env.backtest_loop()
env.show_results()
下面是因子集的定义代码:
class Alpha(AlphaBase): def __init__(self): pass @staticmethod def parse_config_to_fields(): # ['CORD30', 'STD30', 'CORR5', 'RESI10', 'CORD60', 'STD5', 'LOW0', # 'WVMA30', 'RESI5', 'ROC5', 'KSFT', 'STD20', 'RSV5', 'STD60', 'KLEN'] fields = [] names = [] # kbar fields += [ "(close-open)/open", "(high-low)/open", "(close-open)/(high-low+1e-12)", "(high-greater(open, close))/open", "(high-greater(open, close))/(high-low+1e-12)", "(less(open, close)-low)/open", "(less(open, close)-low)/(high-low+1e-12)", "(2*close-high-low)/open", "(2*close-high-low)/(high-low+1e-12)", ] names += [ "KMID", "KLEN", "KMID2", "KUP", "KUP2", "KLOW", "KLOW2", "KSFT", "KSFT2", ] # =========== price ========== feature = ["OPEN", "HIGH", "LOW", "CLOSE"] windows = range(5) for field in feature: field = field.lower() fields += ["shift(%s, %d)/close" % (field, d) if d != 0 else "%s/close" % field for d in windows] names += [field.upper() + str(d) for d in windows] # ================ volume =========== fields += ["shift(volume, %d)/(volume+1e-12)" % d if d != 0 else "volume/(volume+1e-12)" for d in windows] names += ["VOLUME" + str(d) for d in windows] # ================= rolling ==================== windows = [5, 10, 20, 30, 60] fields += ["shift(close, %d)/close" % d for d in windows] names += ["ROC%d" % d for d in windows] fields += ["mean(close, %d)/close" % d for d in windows] names += ["MA%d" % d for d in windows] fields += ["std(close, %d)/close" % d for d in windows] names += ["STD%d" % d for d in windows] fields += ["slope(close, %d)/close" % d for d in windows] names += ["BETA%d" % d for d in windows] fields += ["max(high, %d)/close" % d for d in windows] names += ["MAX%d" % d for d in windows] fields += ["min(low, %d)/close" % d for d in windows] names += ["MIN%d" % d for d in windows] fields += ["corr(close/shift(close,1), log(volume/shift(volume, 1)+1), %d)" % d for d in windows] names += ["CORD%d" % d for d in windows] fields += ['close/shift(close,20)-1'] names += ['roc_20'] return fields, names
所有代码,数据均打包发布至星球,请大家前往下载:
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104114
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!