
今天市场久违的大涨!
主系统优化
主系统engine是我们常期要用和维护的,会持续优化效率,改bug等。
dataloader上周新增的reset_index,在reindex的时候,会在前面生成nan,需要drop_na一下:
ef _reset_index(self, dfs: list):
trade_calendar = []
for df in dfs:
trade_calendar.extend(list(df.index))
trade_calendar = list(set(trade_calendar))
trade_calendar.sort()
dfs_reindex = []
for df in dfs:
df_new = df.reindex(trade_calendar, method='ffill')
# diff = set(trade_calendar) - set(df.index)
# print(diff)
df_new.dropna(inplace=True) # 这里需要drop_na
df_new['return_0'] = df_new['close'].pct_change()
dfs_reindex.append(df_new)
return dfs_reindex
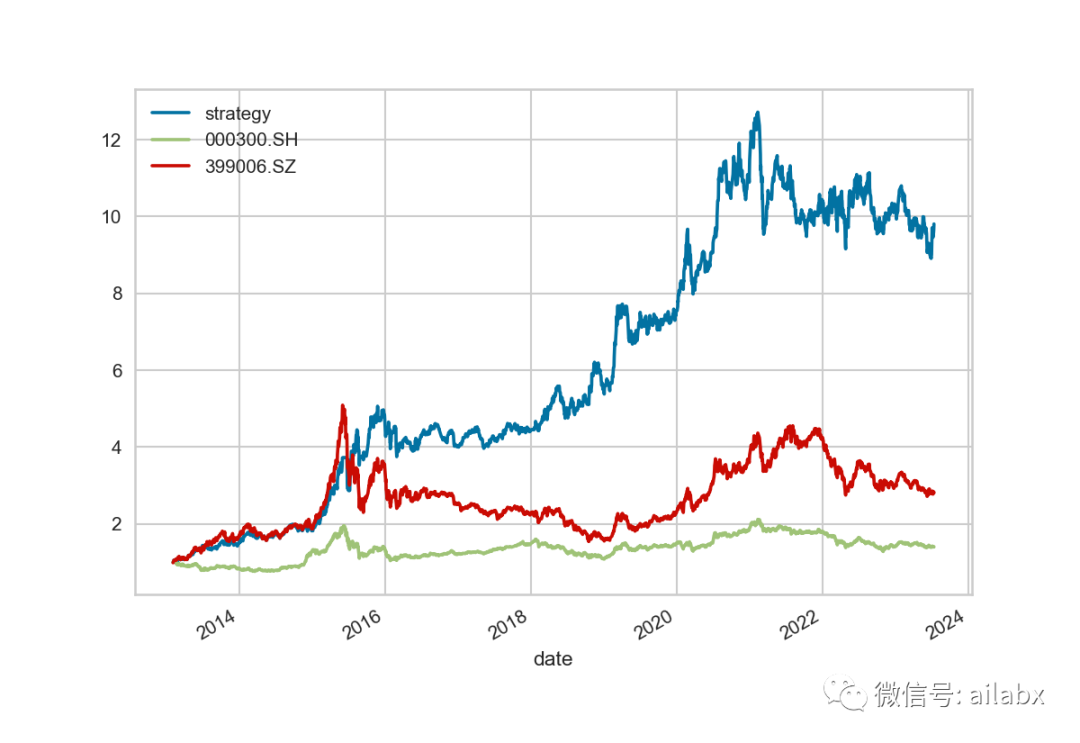
今天继续把pycaret整合到我们的系统中。
对比pycaret与我们自己实现的lightgbm。
这里调用pycaret,未调参准确率:41.39%,调参后41.69%。我们自己实现的版本,默认参数下准确率:37.41%


代码如下,大家可以自己运行跑跑看下效果,pycaret还是做了数据预处理及优化的。
import sys sys.path.append("../") from engine.datafeed.dataloader import Hdf5Dataloader from engine.config import etfs_indexes etfs = [ '510300.SH', # 沪深300ETF '159915.SZ', # 创业板 '518880.SH', # 黄金ETF '513100.SH', # 纳指ETF '159985.SZ', # 豆柏ETF '511880.SH', # 银华日利ETF ] symbols = etfs loader = Hdf5Dataloader(symbols, start_date="20130101") fields = ["roc(close,20)", "bias(close,20)", "std(volume,20)", "ema(ta_obv(close,volume),7)", "rank(roc_20)+rank(bias_20)", "shift(close, -5)/shift(open, -1) - 1", "qcut(label_c, 3)"] names = ["roc_20", "bias_20", "std_20", "obv_7", "rank_roc_bias", "label_c", 'label'] df = loader.load(fields=fields, names=names) df.dropna(inplace=True) print(df) df = df[names] del df['label_c'] print(df) from pycaret.classification import * s = setup(df, target='label', session_id=123, index=False) model = create_model('lightgbm') print(model) tune_model(model)
因此,使用pycaret,比自己一个个搞自己的模型靠谱。

import sys from engine.algo import * from engine.env import Env sys.path.append("../") from engine.datafeed.dataloader import Hdf5Dataloader from engine.config import etfs_indexes etfs = [ '510300.SH', # 沪深300ETF '159915.SZ', # 创业板 '518880.SH', # 黄金ETF '513100.SH', # 纳指ETF '159985.SZ', # 豆柏ETF '511880.SH', # 银华日利ETF ] symbols = etfs loader = Hdf5Dataloader(symbols, start_date="20130101") fields = ["roc(close,20)", "bias(close,20)", "std(volume,20)", "ema(ta_obv(close,volume),7)", "rank(roc_20)+rank(bias_20)", "shift(close, -5)/shift(open, -1) - 1", "qcut(label_c, 3)"] names = ["roc_20", "bias_20", "std_20", "obv_7", "rank_roc_bias", "label_c", 'label'] df = loader.load(fields=fields, names=names) df.dropna(inplace=True) print(df) features = ["roc_20", "bias_20", "std_20", "obv_7", "rank_roc_bias"] del df['label_c'] print(df) from pycaret.classification import * from pycaret.classification import ClassificationExperiment def train(): s = ClassificationExperiment() s.setup(df, target='label', session_id=123, index=False) model = s.create_model('lightgbm') s.save_model(model, 'pycaret_model') def predict(): s = ClassificationExperiment() s.setup(df, target='label', session_id=123, index=False) loaded_model = s.load_model('pycaret_model') print(loaded_model) pred = s.predict_model(loaded_model, data=df[features]) pred.index = df.index df['pred'] = pred['prediction_label'] print(df) return df def backtest(df): env = Env(df, benchmarks=['000300.SH', '399006.SZ']) env.set_algos([ #RunWeekly(), SelectTopK(drop_top_n=0, K=1, order_by='pred', b_ascending=False), # PickTime(benchmark='399006.SZ', signal='zscore'), # PickTime(benchmark='000300.SH', signal='zscore'), WeightEqually() ]) env.backtest_loop() env.show_results() if __name__ == '__main__': df = predict() backtest(df)
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/104034
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!