
引入dataclass做策略配置:
大家使用这个ProjConfig写配置非常容易,IDE还会提示参数。

from gui.proj_loader import ProjConfig, AlgoConfig, from_toml from config import DATA_DIR_PRJ proj = ProjConfig() proj.name = '网格策略' proj.commission = 0.0001 proj.slippage = 0.0001 proj.symbols = ['B0'] # 证券池列表 proj.benchmark = '000300.SH' proj.start_date = '20100101' # 这里是因子列表 proj.fields = ['max(high,1440)', 'min(low,1440)', '(max+min)/2'] proj.names = ['max', 'min', 'mid'] # 这里是策略算子列表 proj.algos.append(AlgoConfig(name='AlgoGrid', args=[])) print(proj) print(proj.load_df().dropna(inplace=True)) # 保存到目录 proj.to_toml(path=DATA_DIR_PRJ.resolve())
写好后可以自动保存成toml使用。
而后可以使用如下脚本来运行toml。
from engine.backtrader_engine import BacktraderEngine from gui.proj_loader import ProjConfig, AlgoConfig, from_toml from config import DATA_DIR_PRJ proj = ProjConfig() name = '网格策略' # 这里修改策略名称即可,策略列表在 data/projs下 p = from_toml(DATA_DIR_PRJ.joinpath('{}.toml'.format(name))) print(p) df = p.load_df() algos = p.parse_algos() print(algos) df.dropna(inplace=True) print(df) e = BacktraderEngine(df, benchmark=p.benchmark, slippage=p.slippage, commission=p.commission) e.run_algo_strategy(algos) e.analysis(console=True)
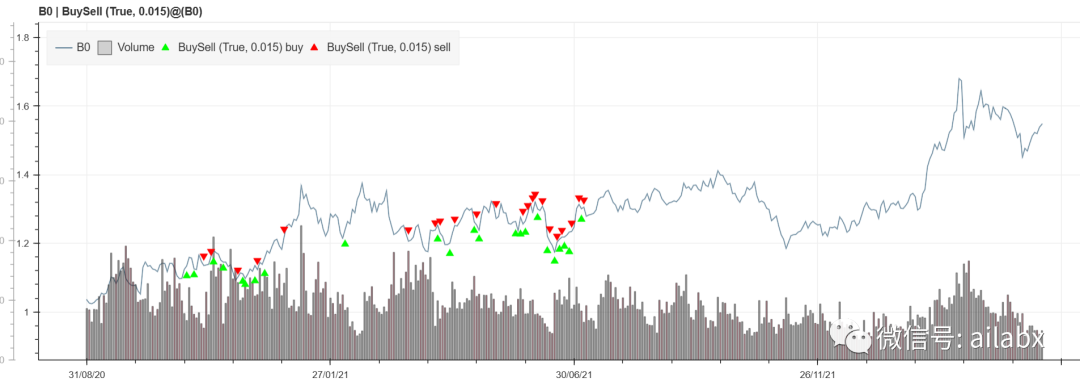
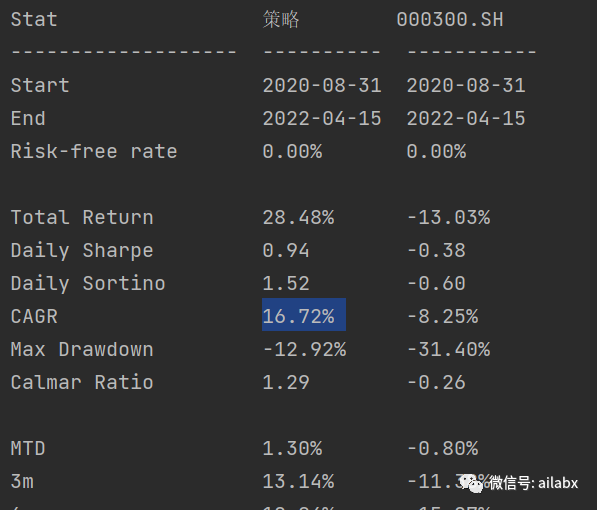
吾日三省吾身
有同学问及,量化回测有什么用?回测代表不了实盘。
这个问题曾经回答过,回测是实盘“必要非充分“条件,就像成长是成功的”必要非充分条件“。简单说,你自己有一个思路,觉得特别好,你的直觉和所谓盘感都告诉你,这个很好。那最简单的做法就是量化回测验证一下,也没什么成本。昨天去书店转一圈,发现现在讲K线的投资书少了,估计与量化兴起有关。你说”两条均线“打天下,用我们的quantlab,你直接测一下,结果不就出来了嘛。所以量化之一大功能就是”证伪“。
简言之:回测结果好,实盘未必好;但回测结果都不好,实盘能好嘛?
回测能帮你排坑,过滤掉不好的思路,你可以接近零成本试错。
不忘初心,星球的目标是什么?
量化投资里最难的当然是策略思路,AI量化里就有找有用的因子。这是大家一直努力的目标,但过程中,还有一件很繁琐的事情,就是把策略逻辑表达为“代码”。这个过程有大量的细节,调试,而且多数都是重复性的工作。
我们的目标之一,就是让思路到策略代码,尽量简洁。因此有了我们的“积木式”的策略开发,就是强调易用性。
今天实现一下performance计算,对于回测而言,我们最关心的几个指标:最大回撤,波动率,年化收益等。
先看效果:

代码下工程如下位置:(已经更新至星球)

import pandas as pd from datetime import datetime def year_frac(start, end): """ Similar to excel's yearfrac function. Returns a year fraction between two dates (i.e. 1.53 years). Approximation using the average number of seconds in a year. Args: * start (datetime): start date * end (datetime): end date """ if start > end: raise ValueError("start cannot be larger than end") # obviously not perfect but good enough return (end - start).total_seconds() / (31557600) def calc_stats(df_price: pd.DataFrame): if type(df_price) is pd.Series: df_price = pd.DataFrame(df_price) df_price.dropna(inplace=True) df_rates = df_price.pct_change() df_equity = (1 + df_rates).cumprod() df_equity.dropna(inplace=True) df_rates.dropna(inplace=True) # import empyrical # print('年化收益:', round(empyrical.annual_return(df_rates), 3)) count = len(df_price) start = df_price.index[0] end = df_price.index[-1] accu_return = round(df_equity.iloc[-1] - 1, 3) accu_return.name = '累计收益' annu_ret = round((accu_return + 1) ** (252 / count) - 1, 3) annu_ret.name = '年化收益' annu_ret2 = round((accu_return+1) ** (1 / year_frac(start, end)) - 1,3) annu_ret2.name = 'CAGR' # 标准差 std = round(df_rates.std() * (252 ** 0.5), 3) std.name = '年化波动率' # 夏普比 sharpe = round(annu_ret / std, 3) sharpe.name = '夏普比率' # 最大回撤 mdd = round((df_equity / df_equity.expanding(min_periods=1).max()).min() - 1, 3) mdd.name = '最大回撤' ret_2_mdd = round(annu_ret / abs(mdd), 3) ret_2_mdd.name = '卡玛比率' df_ratios = pd.concat([annu_ret, annu_ret2, mdd, ret_2_mdd, sharpe, accu_return, std], axis=1) df_ratios['开始时间'] = start.strftime('%Y-%m-%d') df_ratios['结束时间'] = end.strftime('%Y-%m-%d') return df_ratios.T
我的计算方式,与zipline类似,

bt的计算与我的略有差别:

我看了下它的代码:bt的逻辑是按照自然天数/365,我们是按照回测天数/252。从合理性而言,bt的更符合直觉。

大家可以看下对比情况:

另外可以给loguru添加全局的重定向:
def my_logger_notify(data): g.notify({'msg_type': 'LOGGER', 'message': data}) from loguru import logger logger.add(my_logger_notify)
如此,日志可以实时显示在gui的文本框里。

发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103846
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!