
星球群里好多同学在聊,实盘的事情。
量化交易系统自动化,工程化的事情。
客观地说,精力有点放错了地方。我之前也在回测系统的设计上花了很多的心力,当然这个是值得的——主要是为了写策略,优化策略更快,比如“因子表达式”、“模块化写策略”,“策略模板“,”自动化超参数优化“。
——这些在Quantlab 3.3基本都交付了。
Quantlab3.3代码发布:全新引擎 | 静态花开:年化13.9%,回撤小于15% | lightGBM实现排序学习
创业板指布林带突破策略:年化12.8%,回撤20%+| Alphalens+streamlit单因子分析框架(代码+数据)
交易里最重要的事情是策略。
策略的主流与未来是”多因子“,私募里的策略也是以多因子为主。
多因子策略的优点:容量大,容易与AI、机器学习相结合、容易优化,形式统一。
比如你从5个因子,扩展到500个因子,策略逻辑基本是不需要变的。
如果你是规则策略,这基本是做不到到。信号相互矛盾了如何处理等?
多因子分解为两个部分: 因子挖掘、因子合成(机器学习模型)。
因子合成,借鉴bigquant的思路我们来实现StockRanker。
就是通过多因子,对多支股票进行排序。
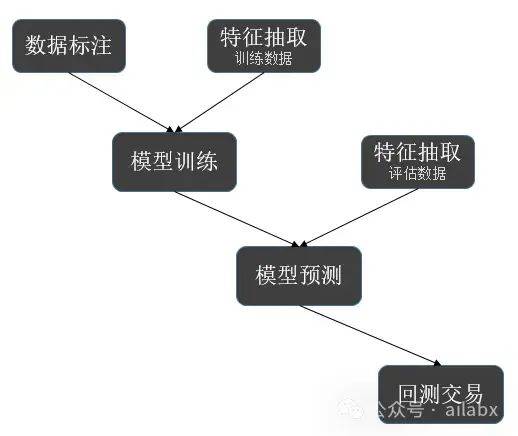

下面的代码使用lightGBM对多支ETF进行排序预测。
import joblib import os import lightgbm as lgb def prepare_groups(df): df_copy = df.copy(deep=True) df_copy['day'] = df_copy.index group = df_copy.groupby('day')['day'].count() return group class StockRanker: def __init__(self, load_model=False, feature_cols=None): self.feature_cols = feature_cols if load_model: path = os.path.dirname(__file__) self.ranker = joblib.load(path + '/lgb.pkl') def predict(self, data): data = data.copy(deep=True) if self.feature_cols: data = data[self.feature_cols] pred = self.ranker.predict(data) return pred def train(self, x_train, y_train, q_train, model_save_path): ''' 模型的训练和保存 :param x_train: :param y_train: :param q_train: :param model_save_path: :return: ''' train_data = lgb.Dataset(x_train, label=y_train, group=q_train) params = { 'task': 'train', # 执行的任务类型 'boosting_type': 'gbrt', # 基学习器 'objective': 'lambdarank', # 排序任务(目标函数) 'metric': 'ndcg', # 度量的指标(评估函数) 'max_position': 10, # @NDCG 位置优化 'metric_freq': 1, # 每隔多少次输出一次度量结果 'train_metric': True, # 训练时就输出度量结果 'ndcg_at': [10], 'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。 'num_iterations': 200, # 迭代次数,即生成的树的棵数 'learning_rate': 0.01, # 学习率 'num_leaves': 31, # 叶子数 # 'max_depth':6, 'tree_learner': 'serial', # 用于并行学习,‘serial’:单台机器的tree learner 'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量 'verbose': 2 # 显示训练时的信息 } #import lightgbm as lgb #gbm = lgb.LGBMRanker() #gbm.fit(x_train, y_train, group=q_train, # eval_set=[(x_train, y_train)], eval_group=[q_train], # eval_at=[5, 10, 20]) #print(gbm.feature_importances_) gbm = lgb.train(params, train_data, valid_sets=[train_data]) # 这里valid_sets可同时加入train_data,val_data print(gbm.feature_importance()) gbm.save_model(model_save_path) def predict(x_test, comments, model_input_path): ''' 预测得分并排序 :param x_test: :param comments: :param model_input_path: :return: ''' gbm = lgb.Booster(model_file=model_input_path) # 加载model ypred = gbm.predict(x_test) predicted_sorted_indexes = np.argsort(ypred)[::-1] # 返回从大到小的索引 t_results = comments[predicted_sorted_indexes] # 返回对应的comments,从大到小的排序 return t_results ''' def train_bak(self, ds: DataSet): X_train, X_test, y_train, y_test = ds.get_split_data() X_train_data = X_train.drop('symbol', axis=1) X_test_data = X_test.drop('symbol', axis=1) # X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=1) query_train = self._prepare_groups(X_train.copy(deep=True)).values query_val = self._prepare_groups(X_test.copy(deep=True)).values query_test = [X_test.shape[0]] import lightgbm as lgb gbm = lgb.LGBMRanker() gbm.fit(X_train_data, y_train, group=query_train, eval_set=[(X_test_data, y_test)], eval_group=[query_val], eval_at=[5, 10, 20], early_stopping_rounds=50) print(gbm.feature_importances_) joblib.dump(gbm, 'lgb.pkl') ''' if __name__ == '__main__': from datafeed.dataloader import CSVDataloader from config import DATA_DIR symbols = [ '511220.SH', # 城投债 '512010.SH', # 医药 '518880.SH', # 黄金 '163415.SZ', # 兴全商业 '159928.SZ', # 消费 '161903.SZ', # 万家行业优选 '513100.SH' # 纳指 ] # 证券池列表 loader = CSVDataloader(path=DATA_DIR.joinpath('etfs'), symbols=symbols) df = loader.load(fields=['slope(close,20)', 'qcut(shift(close,5)/close-1,5)'], names=['roc_20', 'label']) ranker = StockRanker() df.set_index([df.index, 'symbol'], inplace=True) df.sort_index(inplace=True) x_train = df[['roc_20']] y_train = df['label'] q_train = prepare_groups(x_train) print(y_train) ranker.train(x_train=x_train, y_train=y_train, q_train=q_train, model_save_path='model.pkl')
代码在如下这个位置:
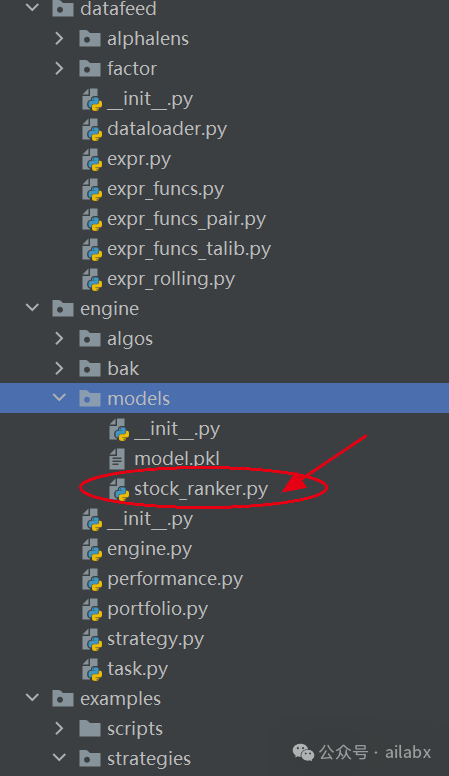
明天要添加更多因子,进行更细节的优化。
历史文章:
Quantlab3.3代码发布:全新引擎 | 静待花开:年化13.9%,回撤小于15% | lightGBM实现排序学习
创业板指布林带突破策略:年化12.8%,回撤20%+| Alphalens+streamlit单因子分析框架(代码+数据)
去掉底层回测引擎,完全自研,增加超参数优化,因子自动挖掘,机器模型交易。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103559
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!