
越发不确定的当下,职场躺不平,卷不动——有时候连卷的机会都没有。
很多公司遇到的困难,必须断臂求生。
创业又九死一生。
中年人上有老,下有小,躺不平,卷不动。
很多人“被动”走向了投资。——至少似乎有点事情做,好像有时候还能赚点钱。——梦想中,没准还能一不小心,找到圣杯,走向人生巅峰。
——当然,小心你的本金。
投资是一个非常专业的行为,不比你任何从事过的工作简单。
看起来不就是一买一卖嘛,有多少英雄折戟沉沙。
今天还是要先从方法论上讲讲,投资的三个层次:大类资产配置、战术资产调优和择时。
大类资产配置
资本市场有一个假设就是肯定长期向上。资本市场建立的逻辑,本身就是大家集中力量办大事,风险共担,收益共享。——这里办大事的逻辑,当然是要把事情做成。——比如大航海时代,集资出海贸易。
某一艘船会有很大的不确定性,也就是风险。但从长期和整体来看,航海事业一定是高收益——否则你折腾它干啥。
这时候,如果你全面配置,无视短期波动,就可能拿到市场长期增长的收益,俗称市场Beta。
这是大类资产配置的逻辑基础。风险平价等策略都是它的衍生和应用。
它的特点是不预测,按风险暴露情况相等来配置,拿到市场综合Beta。
长期看,10%左右的长期收益是可期的。——这时候,如果你本金超过500万,就可以每年获得税后50万的被动收入——你就一定意义上财务自由了!10%长期年化真的挺容易的:国内版全天候风险平价策略——零代码开发(系统代码+数据)
数据说话——全球主要指数,A股,港股,美股,欧洲,黄金,原油:
from datafeed.dataloader import CSVDataloader data = CSVDataloader.get(['000300.SH', #沪深300 '159915.SZ', #创业板 'HSI', #香港恒生 '^NDX',# 纳指100 'GDAXI',#德国DAX 'N225',#日经225 'AU.NH',#南华黄金期货指数 'SC.NH',#南华 原油期货指数 '000012.SH',#国债指数 ]) data.dropna(inplace=True) (data.pct_change()+1).cumprod().plot()
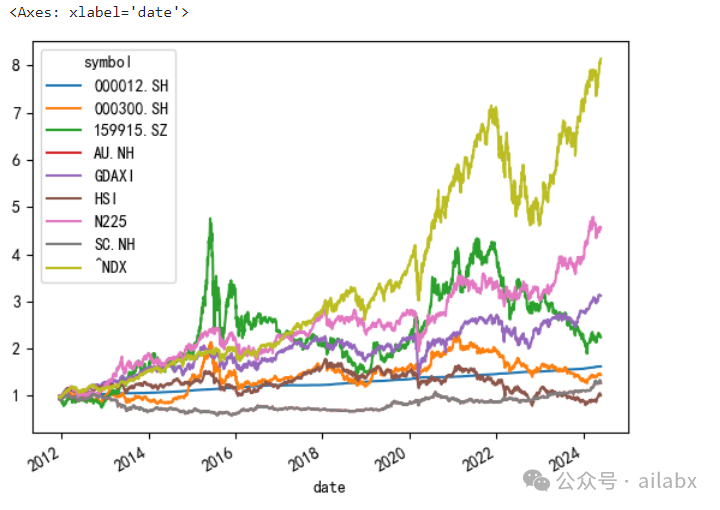

最近A股回调,以致于从指数上看,竟然十年没跑盈国债——当然这是暂时的——投资是一个无限游戏。
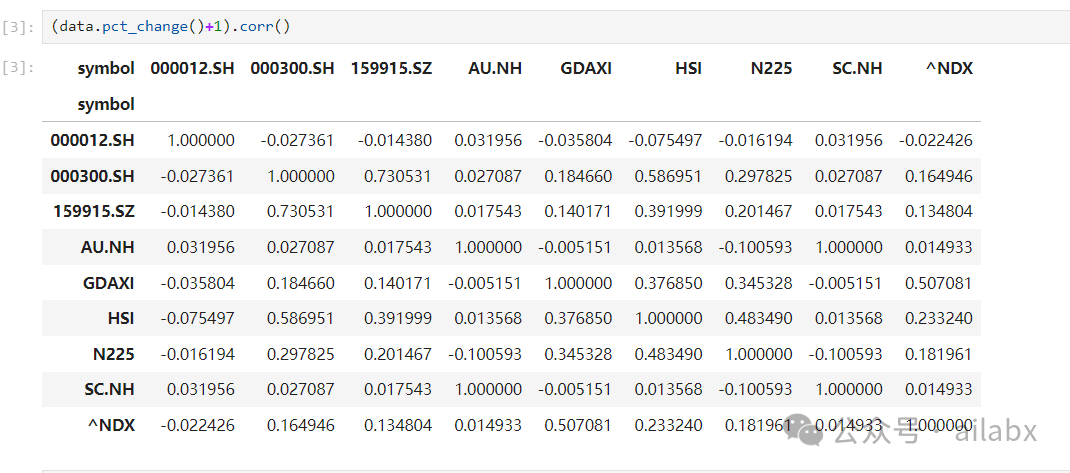
从相关性看过去,还是很好的,黄金、原油,债券和所有其他品类的相关性都低,除A股与恒生相关性比较高之外,A股与美股、欧洲相关性都不高。
这些资产我们做——风险平价策略:
import bt s = bt.Strategy('全球大类资-风险平价-月度再平衡', [ bt.algos.RunAfterDays( 20*6 + 1 ), bt.algos.RunMonthly(), bt.algos.SelectAll(), bt.algos.WeighERC(), bt.algos.Rebalance()]) test = bt.Backtest(s, data) stras = [test]
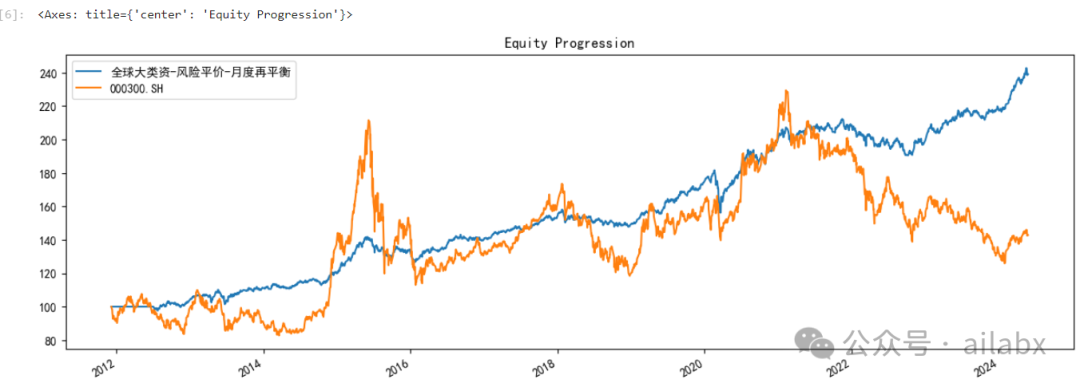
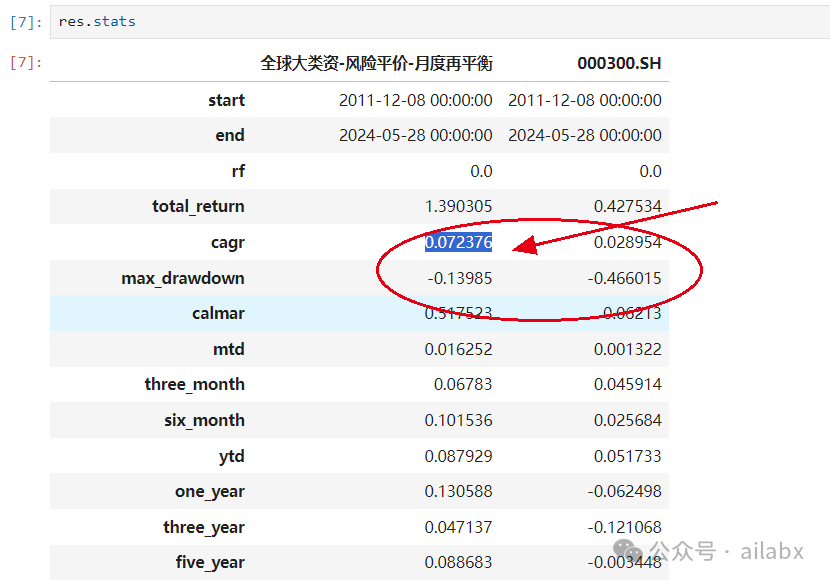
长期年化7.2%,最大回撤13%,要知道——我们没有使用全收益指数,真正交易的时候收益会更高。
另外,这些都是大盘宽期指数,做一些行业指数增强后,收益年化10%不是大问题。
代码和策略这里取:
目前设想的——Quantlab5.0,之所以升级一个大版本,与4.x有很大不同。
5.0专注策略开发,可能以notebook形式为主,弱化gui界面,甚至少用streamlit。同时弱化策略框架的封装,这样大家一可一眼看明白一个策略如何开发出来,如何运行,如何调优。
——简言之,就是一切围绕可实盘策略驱动开发,开发赋能交易,而非其他。
数据加载方面,使用csv加载,数据很重要,处理也挺耗时,但之于策略开发,并非核心,因此简化+标准化:
对于bt框架而言,就是一次性加载多个symbols的收盘价,形成一个dataframe即可——以下示例,加载沪深300指数、创业板指数收盘价,并给图,计算相关性:
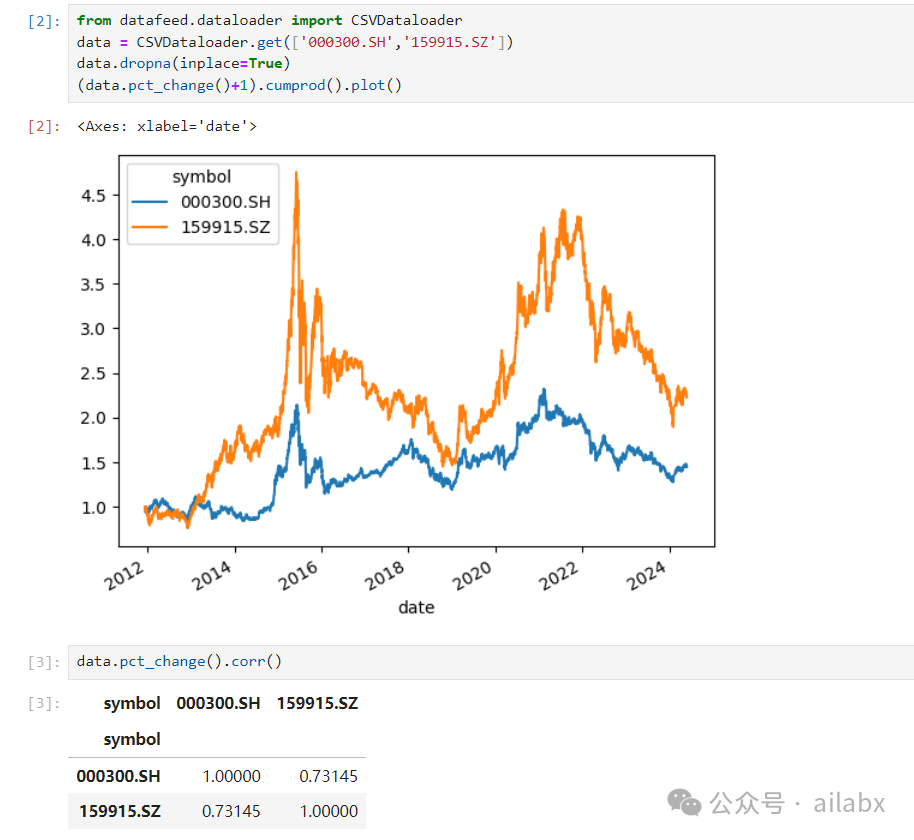
可以看出,大小盘的相关性仍然高达0.73。
@staticmethod def get(symbols: list[str], col='close', start_date='20100101'): dfs = [] for s in symbols: df = CSVDataloader.read_csv(s) if df is not None: dfs.append(df) df_all = pd.concat(dfs, axis=0) if col not in df_all.columns: logger.error('{}列不存在') return None df_close = df_all.pivot_table(values=col, index=df_all.index, columns='symbol') df_close = df_close[start_date:] return df_close
我们可以很容易进行全球大类资产——时间序列的分析:
from datafeed.dataloader import CSVDataloader data = CSVDataloader.get(['000300.SH', #沪深300 '159915.SZ', #创业板 'HSI', #香港恒生 '^NDX',# 纳指100 'GDAXI',#德国DAX '000012.SH',#国债指数 ]) data.dropna(inplace=True) (data.pct_change()+1).cumprod().plot()
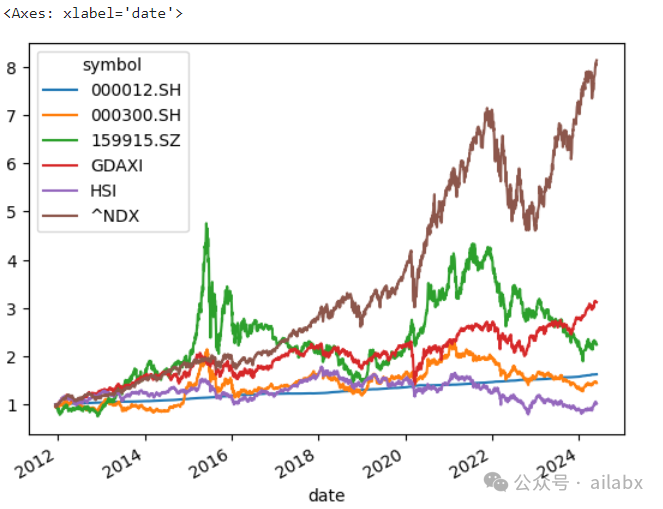
可以看出来,纳指100一骑绝尘。
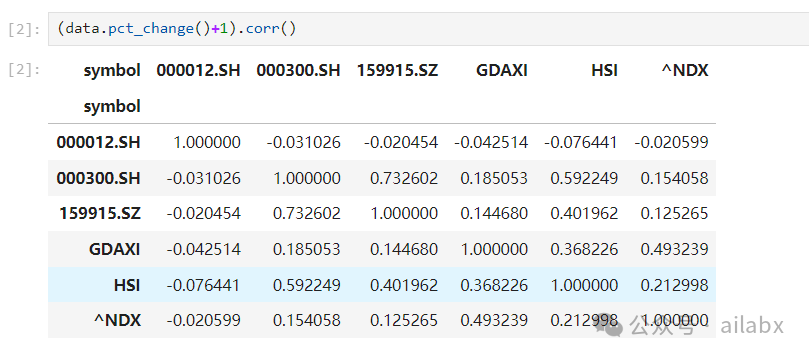
国债和所有资产都是负相关,沪深 和德国,纳指100的相关度很低,与恒生相关度高。德国(欧洲)与美股(纳指100)相关度也还好。
——从大类资产配置的角度,长期向上的资产,相关度越低,则越能在不降低收益率的基础上,有效降低波动。
重新整合代码目录:
这是投资组合理论,是投资之基础。
从量化学习的角度,除了python基础之外,最应该熟悉的是掌握一两款回测框架。
当然,如果有兴趣,自己实现一个回测框架——之前我花不少时间,在打磨自己的回测引擎。——这个好处是你知道底层框架的设计细节,对于你调试策略,理解逻辑很有帮助。
从实战的角度,选择成熟的框架就好。
回测框架与实盘框架,我建议是分开的。——回测是验证你的思路,求方便、省事,效率高。而实盘是真金白银,求稳定,可靠。
二者有一定冲突的,都按实盘的标准来,你的策略很复杂,而且你搞不清楚是策略没写好,还是策略本身就不行。所以,分开来。
从回测的角度,Quantlab5.0(计划中),会引入多个回测框架,包含但不限于:bt, backtesting.py, pybroker或backtrader, qlib等。
每个框架各有所长,比如bt特别适合资产配置、轮动策略,而backtesting.py适合单标的择时(backtrader的单标的版本,但策略和指标比backtrader直观和易用),pybroker支持机器学习,尤其是WFA股东训练。
数据方面,专注指数(ETF),对于回测而言,它们都是时间序列,迁移起来是非常容易的。——一开始不必在数据上花费太多时间。
发布者:股市刺客,转载请注明出处:https://www.95sca.cn/archives/103229
站内所有文章皆来自网络转载或读者投稿,请勿用于商业用途。如有侵权、不妥之处,请联系站长并出示版权证明以便删除。敬请谅解!